Навигация
Линейные списки. Стек. Дек. Очередь
94620
знаков
8
таблиц
0
изображений
Содержание
Введение 3
Глава 1. Динамические типы данных_ 6
1.1 Списки. Очередь. Стек. Дек. 6
1.2 Динамические информационные структуры_ 22
Глава 2. Разработка факультативного курса «Динамические типы данных»_ 29
2.1 Методические рекомендации по введению факультативного курса в школе_ 29
2.2 Разработка программного средства по теме «Динамические типы данных»_ 38
Заключение 42
Литература_ 44
Приложение 1. (Листинг программы) 45
ВведениеСегодня человек живет в мире, где информация имеет огромное значение. Жизненно важно научиться правильно с ней работать и использовать различные инструменты для этой работы. Одним из таких инструментов является компьютер, который стал универсальным помощником человеку в различных сферах деятельности.
В вычислительной машине программы обычно оперируют с таблицами информации. В большинстве случаев это не просто аморфные массы числовых величин: в таблицах присутствуют важные структурные отношения между элементами данных.
Чтобы правильно использовать машину, важно добиться хорошего понимания структурных отношений, существующих между данными, способов представления таковых в машине и методов работы с ними.
Изучить наиболее важные факты, касающиеся информационных структур: их статические и динамические свойства; средства распределения памяти и представления данных; эффективные алгоритмы для создания, изменения, разрушения структурной информации и доступа к ней.
В простейшей форме таблица может быть линейным списком элементов. Тогда присущие ей структурные свойства содержат в себе ответы на такие вопросы, как: "Какой элемент является первым в списке? какой — последним? какой элемент предшествует данному или следует за данным?" Можно много говорить о структуре даже в этом совершенно очевидном случае.
В более сложных ситуациях таблица может быть двумерным массивом (т. е. матрицей, иногда называемой сеткой, имеющей структуру строк и столбцов), либо может быть n-мерным массивом при весьма больших значениях n, либо она может иметь структуру дерева, представляющего отношения иерархии или ветвления, либо это может быть сложная многосвязанная структура с огромным множеством взаимных соединений, такая, например, которую можно найти в человеческом мозгу.
Системы обработки списков полезны в очень многих случаях, однако при их использовании программист нередко сталкивается с излишними ограничениями.
Теперь целесообразно определить несколько терминов и понятий, которыми мы будем часто пользоваться в дальнейшем. Информация в таблице представлена множеством узлов (некоторые авторы называют их "записями", "бусинами", "объектами"); мы иногда вместо "узел" будем говорить "элемент". Каждый узел состоит из одного или нескольких последовательных слов в памяти машины, разделенных на именуемые части, называемые полями. В простейшем случае узел — это просто одно слово памяти, он имеет только одно поле, включающее все слово.
В связи с этим цель нашей работы: Знакомство с теоретическим положением, касающиеся информационных структур и разработка программного средства «Динамические структуры данных».
Этой целью определяется следующая гипотеза: если при изучении данной темы будет использоваться компьютер, то усвоение темы будет более успешным, так как усиливает мотивацию, и влияет на конечный результат.
Предмет исследования: Изучение динамических информационных структур.
Объект исследования: Знакомство учащихся с основами программирования.
Достижением цели и согласно поставленной гипотезы определяются следующие задачи:
1. Изучить литературу по теме динамические информационные структуры, педагогическую и методическую по теме исследования;
2. Проанализировать виды динамических информационных структур;
3. Разработать факультатив по теме исследования;
4. Разработать программный продукт по теме исследования.
Глава 1. Динамические типы данных 1.1 Списки. Очередь. Стек. Дек.Список (list) – набор элементов, расположенных в определенном порядке. Таким набором быть может ряд знаков в слове, слов в предложений в книге. Этот термин может также относиться к набору элементов на диске. Использование при обработке информации списков в качестве типов данных привело к появлению в языках программирования средств обработки списков.
Список очередности (pushup list) – список, в котором последний поступающий элемент добавляется к нижней части списка.
Список с использованием указателей (linked list) – список, в котором каждый элемент содержит указатель на следующий элемент списка.
Линейный список (linear list) — это множество, состоящее из узлов , структурные свойства которого по сути ограничиваются лишь линейным (одномерным) относительным положением узлов, т. е. теми условиями, что если , то является первым узлом; если , то k-му узлу предшествует и за ним следует ; является последним узлом.
Операции, которые мы имеем право выполнять с линейными списками, включают, например, следующие:
1. Получить доступ к k-му узлу списка, чтобы проанализировать и/или изменить содержимое его полей.
2. Включить новый узел непосредственно перед k-ым узлом.
3. Исключить k-й узел.
4. Объединить два (или более) линейных списка в один список.
5. Разбить линейный список на два (или более) списка.
6. Сделать копию линейного списка.
7. Определить количество узлов в списке.
8. Выполнить сортировку узлов списка в возрастающем порядке по некоторым полям в узлах.
9. Найти в списке узел с заданным значением в некотором поле.
Специальные случаи k=1 и k=n в операциях (1), (2) и (3) особо выделяются, поскольку в линейном списке проще получить доступ к первому и последнему элементам, чем к произвольному элементу.
В машинных приложениях редко требуются все девять из перечисленных выше операций в самом общем виде. Мы увидим, что имеется много способов представления линейных списков в зависимости от класса операций, которые необходимо выполнять наиболее часто. По-видимому, трудно спроектировать единственный метод представления для линейных списков, при котором все эти операции выполняются эффективно; например, сравнительно трудно эффективно реализовать доступ к k-му узлу в длинном списке для произвольного k, если в то же время мы включаем и исключаем элементы в середине списка. Следовательно, мы будем различать типы линейных списков по главным операциям, которые с ними выполняются.
Очень часто встречаются линейные списки, в которых включение, исключение или доступ к значениям почти всегда производятся в первом или последнем узлах, и мы дадим им специальные названия:
Многие люди поняли важность стеков и очередей и дали другие названия этим структурам; стек называли пуш-даун (push-down) списком, реверсивной памятью, гнездовой памятью, магазином, списком типа LIFO ("last-in-first-out" — "последним включается — первым исключается") и даже употребляется такой термин, как список йо-йо! Очередь иногда называют — циклической памятью или списком типа FIFO ("first-in-first-out" — "первым включается — первым исключается"). В течение многих лет бухгалтеры использовали термины LIFO и FIFO как названия методов при составлении прейскурантов. Еще один термин "архив" применялся к декам с ограниченным выходом, а деки с ограниченным входом называли "перечнями", или "реестрами". Такое разнообразие названий интересно само по себе, Поскольку оно свидетельствует о важности этих понятий. Слова "стек" и "очередь" постепенно становятся стандартными терминами; из всех других словосочетаний, перечисленных выше, лишь "пуш-даун список" остается еще довольно распространенным, особенно в теории автоматов.
При описании алгоритмов, использующих такие структуры, принята специальная терминология; так, мы помещаем элемент на верх стека или снимаем верхний элемент. Внизу стека находится наименее доступный элемент, и он не удаляется до тех пор, пока не будут исключены все другие элементы. Часто говорят, что элемент опускается (push down) в стек или что стек поднимается (pop up), если исключается верхний элемент. Эта терминология берет свое начало от "стеков" закусок, которые можно встретить в кафетериях, или по аналогии с колодами карт в некоторых перфораторных устройствах. Краткость слов "опустить" и "поднять" имеет свое преимущество, но эти термины ошибочно предполагают движение всего списка в памяти машины. Физически, однако, ничего не опускается; элементы просто добавляются сверху, как при стоговании сена или при укладке кипы коробок. В применении к очередям мы говорим о начале и конце очереди; объекты встают в конец очереди и удаляются в момент, когда наконец достигают ее начала. Говоря о деках, мы указываем левый и правый концы. Понятие верха, низа, начала и конца применимо иногда и к декам, если они используются как стеки или очереди. Не существует, однако, каких-либо стандартных соглашений относительно того, где должен быть верх, начало и конец: слева или справа. Таким образом, мы находим, что в наших алгоритмах применимо богатое разнообразие описательных слов: "сверху — вниз" — для стеков, "слева — направо" — для деков и "ожидание в очереди" — для очередей.
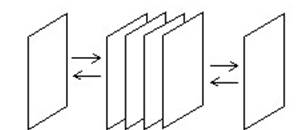
Однонаправленный и двунаправленный список – это линейный список, в котором все исключения и добавления происходят в любом месте списка.
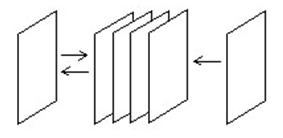
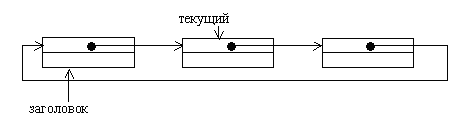
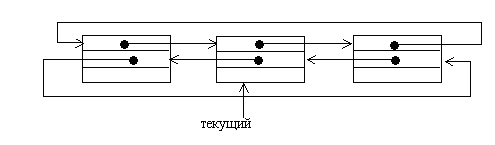
Однонаправленный список отличается от двунаправленного списка только связью. То есть в однонаправленном списке можно перемещаться только в одном направлении (из начала в конец), а двунаправленном – в любом. Из рисунка это видно: сверху однонаправленный список, а снизу двунаправленный
На рисунке видно как добавляется и удаляется элемент из двунаправленного списка. При добавлении нового элемента (обозначен N) между элементами 2 и 3. Связь от 3 идет к N, а от N к 4, а связь между 3 и 4 удаляется.
В однонаправленном списке структура добавления и удаления такая же только связь между элементами односторонняя.
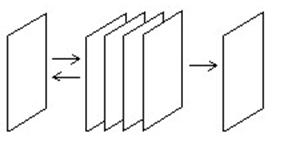
Очередь (queue) — линейный список, в котором все включения производятся на одном конце списка, а все исключения (и обычно всякий доступ) делаются на другом его конце.
Очередь — тип данных, при котором новые данные располагаются следом за существующими в порядке поступления; поступившие первыми данные при этом обрабатываются первыми.
В некоторых разделах математики слово "очередь" используют в более широком смысле, обозначая любой сорт списка, в котором производятся включения и исключения; указанные выше специальные случаи называются тогда "очередями с различными дисциплинами". Однако здесь термин "очередь" используется лишь в узком смысле, аналогичном упорядоченным очередям людей, ожидающим обслуживания.
Правило здесь такое же, как в живой очереди: первым пришёл—первым обслужен. Пришел новый покупатель, встал (добавился) в конец очереди, а который уже отоварился ушел (удалился) из начала очереди. То есть первым пришел, первым ушел.
Другими словами, у очереди есть голова (head) и хвост (tail). Элемент, добавляемый в очередь, оказывается в её хвосте, как только что подошедший покупатель; элемент, удаляемый из очереди, находится в её голове, как тот покупатель, что отстоял дольше всех.
В очереди новый элемент добавляется только с одного конца. Удаление элемента происходит на другом конце. В данном случае это может быть только 4 элемент. Очередь по сути однонаправленный список, только добавление и исключение элементов происходит на концах списка.
Стек (stack) — линейный список, в котором все включения и исключения (и обычно всякий доступ) делаются в одном конце списка.
Стек — часть памяти ОЗУ компьютера, которая предназначается для временного хранения байтов, используемых микропроцессором; при этом используется порядок запоминания байтов «последним вошел – первым вышел», поскольку такие ввод и вывод организовывать проще всего, также операции осуществляются очень быстро. Действия со стеком производится при помощи регистра указателя стека. Любое повреждение этой части памяти приводит к фатальному сбою.
Стек в виде списка (pushdown list) – стек, организованный таким образом, что последний вводимый в область памяти элемент размещается на вершине списка.
Из стека мы всегда исключаем "младший" элемент из имеющихся в списке, т. е. тот, который был включен позже других. Для очереди справедливо в точности противоположное правило: исключается всегда самый "старший" элемент; узлы покидают список в том порядке, в котором они в него вошли.
Стеки очень часто встречаются в практике. Простым примером может служить ситуация, когда мы просматриваем множество данных и составляем список особых состояний или объектов, которые должны обрабатываться позднее; когда первоначальное множество обработано, мы возвращаемся к этому списку и выполняем последующую обработку, удаляя элементы из списка, пока список не станет пустым. Для этой цели пригодны как стек, так и очередь, но стек, как правило, удобнее. При решении задач наш мозг ведет себя как "стек": одна проблема приводит к другой, а та в свою очередь к следующей; мы накапливаем в стеке эти задачи и подзадачи и удаляем их по мере того, как они решаются. Аналогично процесс входов в подпрограммы и выходов из них при выполнении машинной программы подобен процессу функционирования стека. Стеки особенно полезны при обработке языков, имеющих структуру вложений. К ним относятся языки программирования, арифметические выражения и немецкие "Schachtelsatze" /буквально "вложенные предложения"/. Вообще, стеки чаще всего возникают в связи с алгоритмами, имеющими явно или неявно рекурсивный характер.
Представьте себе, что четыре железнодорожных вагона находятся на входной стороне пути (рис. 1) и перенумерованы соответственно 1, 2, 3 и 4. Предположим, что мы выполняем следующую последовательность операций (которые согласуются с направлением стрелок на рисунке и не требуют, чтобы вагоны "перепрыгивали" друг через друга). Отправьте:
| (а) вагон 1 в стек; (b) вагон 2 в стек; (с) вагон 2 на выход; (d) вагон 3 в стек; | (е) вагон 4 в стек; (f) вагон 4 на выход; (g) вагон 3 на выход; (h) вагон 1 на выход. |
В результате этих операций первоначальный порядок вагонов, 1234, изменился на 2431. Цель этого упражнения состоит в том, чтобы исследовать, какие перестановки можно получить, используя стеки, очереди и деки.
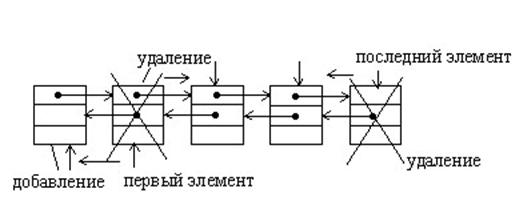
В стеке элемент добавляется и удаляется только с одного конца. На рисунке это элемент N. То есть если он добавился, то удаляется может сначала только он, а уж потом все остальные.
Стек можно представить себе как коробку, в которую складывают какие-нибудь предметы, чтобы достать самый нижний нужно предварительно вытащить остальные. Стек можно уподобить стопке тарелок, из которой можно взять верхнюю и на которую можно положить новую тарелку. [Другое название стека в русской литературе — «магазин» — понятно всякому, кто разбирал автомат Калашникова].
Дек (deck) (стек с двумя концами) — линейный список, в котором все включения и исключения (и обычно всякий доступ) делаются на обоих концах списка.
Иногда аналогия с переключением железнодорожных путей, предложенная Э. Дейкстрой, помогает понять механизм стека. На рис. 2. Изображен дек в виде железнодорожного разъезда.
Следовательно, дек обладает большей общностью, чем стек или очередь; он имеет некоторые общие свойства с колодой карт (в английском языке эти слова созвучны). Мы будем различать деки с ограниченным выходом или ограниченным входом; в таких деках соответственно исключение или включение допускается только на одном конце.
В деке все исключения и добавления происходят на обоих его концах. Дек по сути двунаправленный список.
В связанном списке (linked list) элементы линейно упорядочены, но порядок определяется не номерами, как в массиве, а указателями, входящими в состав элементов списка. Списки являются удобным способом хранения динамических множеств, позволяющим реализовать все операции, (хотя и не всегда эффективно).
Если каждый стоящий в очереди запомнит, кто за ним стоит, после чего все в беспорядке рассядутся на лавочке, получится односторонне связанный список; если он запомнит ещё и впереди стоящего, будет двусторонне связанный список.
Другими словами, элемент двусторонне связанного списка (doubly linked list) — это запись, содержащая три поля: key (ключ) и два указателя — next (следующий) и prev (от previous—предыдущий). Помимо этого, элементы списка могут содержать дополнительные данные. Если х — элемент списка, то next указывает на следующий элемент списка, а prev — на предшествующий. Если prev{х}=nil, то у элемента х нет предшествующего: это голова (head) списка. Если next{х}= nil, то х — последний элемент списка или, как говорят, его хвост (tail).
Прежде чем двигаться по указателям, надо знать хотя бы один элемент списка. В различных ситуациях используются разные виды списков. В односторонне связанном (singly linked) списке отсутствуют поля prev. В упорядоченном (sorted) списке элементы расположены в порядке возрастания ключей, так что у головы списка ключ наименьший, а у хвоста списка — наибольший, в отличие от неупорядоченного (unsorted) списка. В кольцевом списке (circular list) поле prev головы списка указывает на хвост списка, а поле next хвоста списка указывает на голову списка.
Если иное не оговорено особо, под списком мы будем понимать неупорядоченный двусторонне связанный список.
Вместо того чтобы хранить список в последовательных ячейках памяти, можно использовать значительно более гибкую схему, в которой каждый узел содержит связь со следующим узлом списка.
Здесь А, В, С, D и Е— произвольные ячейки в памяти, а Л — пустая связь. Программа, в которой используется такая таблица, имела бы, в случае последовательного распределения, дополнительную переменную или константу, значение которой показывает, что таблица состоит из пяти элементов; эту же информацию можно задать с помощью признака конца ("пограничника"), снабдив им элемент 5 или следующую ячейку, В случае связанного распределения в программе имеется переменная связи или константа, которая указывает на А, а отправляясь от А, можно найти все другие элементы списка.
Cвязи часто изображаются просто стрелками, поскольку, как правило, безразлично, какую фактическую ячейку памяти занимает элемент. Поэтому приведенную выше связанную, таблицу можно изобразить следующим образом:
Здесь FIRST — переменная связи, указывающая на первый узел в списке.
Теперь мы можем сопоставить эти две основные формы хранения информации:
1) Связанное распределение требует дополнительного пространства в памяти для связей. В некоторых ситуациях этот фактор может быть доминирующим. Однако мы часто встречаемся с таким положением, когда информация в узле не занимает все слово целиком, и поэтому место для поля связи уже существует. Кроме того, во многих применениях несколько элементов можно объединять в один узел, и, следовательно, потребуется лишь одна связь ни несколько элементов информации. Но гораздо важнее тот факт, что при использовании связанной памяти часто возникает неявный выигрыш в памяти, поскольку можно совмещать общие части таблиц; и во многих Случаях последовательное распределение не будет столь эффективным, как связанное, если так или иначе не остается пустым довольно большое количество ячеек памяти.
2) Легко исключить элемент, находящийся внутри связанного списка. Например, чтобы исключить элемент 3, нам необходимо только изменить связь в элементе 2. При последовательном же распределении такое исключение обычно потребует перемещения значительной части списка вверх на другие места памяти.
3) Если используется связанная схема, то легко включить элемент в список. Например, чтобы включить элемент в (1), необходимо изменить лишь две связи:
Такая операция заняла бы значительное время при работе с длинной последовательной таблицей.
4) При последовательном распределении значительно быстрее выполняются обращения к произвольным частям списка. Доступ к k-му элементу списка, если k — переменная, для последовательного распределения занимает фиксированное время, а для связанного — необходимо k итераций, чтобы добраться до требуемого места. Таким образом, полезность связанной памяти основывается на том факте, что в огромном большинстве приложений мы будем продвигаться по списку последовательно, а не произвольным образом; если нам необходимы элементы в середине или в нижней части списка, то постараемся завести дополнительную переменную связи или список переменных связи, которые указывают на соответствующие места в списке.
5) При использовании схемы со связями упрощается задача объединения двух списков или разбиения списка на части.
6) Схема со связями годится для структур более сложных, чем простые линейные списки. У нас может быть переменное количество списков, размер которых непостоянен; любой узел одного списка может быть началом другого списка; в одно и то же время узлы могут быть связаны в несколько последовательностей, соответствующих различным спискам, и т.д.
7) На многих машинах простые операции, такие, как последовательное продвижение по списку, выполняются несколько быстрее для последовательных списков.
Таким образом, мы видим, что метод связывания, который освобождает нас от ограничений, возникающих вследствие последовательной природы машинной памяти, при некоторых операциях обеспечивает существенно большую эффективность, но в ряде случаев приводит к потере некоторых возможностей. Обычно в конкретной ситуации очевидно, какой метод распределения наиболее приемлем, и часто в программе для организации различных списков используются оба метода.
В следующих нескольких примерах мы будем ради удобства предполагать, что узел — это одно слово и что оно разделено на два поля INFO и LINK:
Использование связанного распределения, как правило, предполагает существование некоторого механизма поиска пустого пространства для нового узла, когда мы хотим включить в список некоторую вновь образованную информацию. Для этой цели обычно существует специальный список, называемый списком свободного пространства.
Циклическое кольцо или список (circular list или ring) – файл, у которого нет определенного начала и конца; каждый элемент файла содержит указатель на начало следующего элемента; при этом «последний» элемент указывает на «первый», так что к списку можно обратиться с любого элемента.
Циклически связанный список (сокращенно — циклический список) обладает той особенностью, что связь его последнего узла не равна Л, а идет назад к первому узлу списка. В этом случае можно получить доступ к любому элементу, находящемуся в списке, отправляясь от любой заданной точки; одновременно мы достигаем также полной симметрии, и теперь нам уже не приходится различать в списке "последний" или "первый" узел. Типичная ситуация выглядит следующим образом:
Предположим, в узлах имеется два поля: INFO и LINK. Переменная связи PTR указывает на самый правый узел списка, a LINK (PTR) является адресом самого левого узла.
Разного рода расщепления одного циклического списка на два, соответствуют операциям конкатенации (объединения) и деконкатенации (разъединения) цепочек.
Таким образом, мы видим, что циклические списки можно использовать не только для представления структур, которым свойственна цикличность, но также для представления линейных структур; циклический список с одним указателем на последний узел, по существу, эквивалентен простому линейному списку с двумя указателями на начало и конец. В связи с этим наблюдением возникает естественный вопрос: Как найти конец списка, имея в виду круговую симметрию? Пустой связи Л, которая отмечает конец, не существует. Проблема решается так: если мы выполняем некоторые операции, двигаясь по списку от одного узла к следующему, то мы должны остановиться, когда мы вернулись к исходному месту (предполагая, конечно, что исходное место все еще присутствует в списке).
Другим решением только что поставленной проблемы может быть включение в каждый циклический список специального отличимого узла, который служит местом, удобным для остановки. Этот специальный узел называется головой списка, и во многих приложениях можно ради удобства потребовать, чтобы каждый циклический список имел один узел, который является головой этого списка. Одно из преимуществ в этом случае заключается в том, что циклический список никогда не будет пустым.
При ссылке на списки вместо указателя на правый конец списка используется обычно голова списка, которая часто находится в фиксированной ячейке памяти.
В качестве примера использования циклических списков рассмотрим арифметические действия над многочленами от переменных х, у и z с целыми коэффициентами. Существует много задач, в которых математик предпочитает работать с многочленами, а не просто с числами; речь идет об операциях, подобных умножению
на ,
дающему в итоге
.
Связанное распределение — естественный инструмент для этой цели, поскольку количество слагаемых в многочлене может расти и их число нельзя заранее предсказать; кроме того, может потребоваться, чтобы в памяти одновременно присутствовало несколько многочленов.
1.2 Динамические информационные структурыДинамические переменные и указатели автоматически порождаются при входе в тот блок, в котором они описываются, существуют на протяжении работы всего блока и уничтожаются при выходе их этого блока.
Обращение к статическим переменным производится по их именам, а тип определяется их описанием. Вся работа по размещению статических объектов в памяти машины выполняется на этапе трансляции. Однако использование только статических переменных может вызвать трудности при составлении эффективной машинной программы. Во многих случаях заранее неизвестен размер той или иной структуры данных, или структура может изменяться в процессе выполнения программы. Одна из подобных структур - последовательный файл.
В языке Паскаль предусмотрена возможность использования динамических величин. Для них выделение и очистка памяти происходит не на этапе трансляции, а в ходе выполнения самой программы. Для работы с динамическими величинами в Паскале предусмотрен специальный тип значений - ссылочный. Этот тип не относится ни к простым, ни к составным. Переменные ссылочного типа, или указатели, являются статическими переменными. Значением переменной ссылочного типа является адрес ячейки - места в памяти соответствующей динамической величины. Свое значение ссылочная переменная получает в процессе выполнения программы, в момент появления соответствующей динамической величины.
Переменные ссылочного типа (указатели) вводятся в употребление обычным путем с помощью их описания в разделе переменных, а их тип, указывающий на тип создаваемых в программе соответствующих динамических величин, тоже определяется либо путем задания типа в описании переменных, либо путем указания имени ранее описанного типа.
Значением указателя является адрес ячейки, начиная с которой будет размещена в памяти соответствующая динамическая величина.
На этой схеме р. - имя указателя; звездочкой изображено значение указателя, а стрелка отражает тот факт, что значением указателя является адрес объекта (ссылка на объект), посредством которого объект и доступен в программе.
В некоторых случаях возникает необходимость в качестве значения указателя принять «пустую» ссылку, которая не связывает с указателем никакого объекта. Такое значение в Паскале задается служебным словом nil и принадлежит любому ссылочному типу. Результаты выполнения оператора p:=nil можно изобразить следующим образом:
Процедура new(i) выполняет две функции:
1) резервирует место в памяти для размещения динамического объекта соответствующего типа с именем i;
2) указателю i присваивает адрес динамического объекта i.
Однако, узнать адрес динамической переменной с помощью процедуры writeln (i) нельзя.
Динамические объекты размещаются по типу стека в специальной области памяти — так называемой «куче» свободной от программ и статических переменных. Символ ^ после имени указателя означает, что речь идет не о значении ссылочной переменной, а о значении того динамического объекта, на который указывает эта ссылочная переменная.
Имя ссылочной переменной с последующим символом ^ называют «переменной с указателем». Именно она синтаксически выполняет роль динамической переменной и может быть использована в любых конструкциях языка, где допустимо использование переменных того типа, что и тип динамической переменной.
Если в процессе выполнения программы некоторый динамический объект р^, созданный в результате выполнения оператора new(p), становится ненужным, то его можно уничтожить (очистить выделенное ему место в памяти) с помощью стандартной процедуры dispose(p). В результате выполнения оператора вида dispose(p) динамический объект, на который указывает ссылочная переменная р, прекращает свое существование, занимаемое им место в памяти становится свободным, а значение указателя р становится неопределенным (но не равным nil).
Если до вызова процедуры dispose(p) имел пустое значение nil, то это приведет к «зависанию» программы.
Если же до вызова этой процедуры указатель р не был определен, то это может привести к выходу из строя операционной системы.
Значение одного указателя можно присвоить другому указателю того же типа. Можно также указатели одинакового типа сравнивать друг с другом, используя отношения «=» или «о».
Стандартные процедуры new и dispose позволяют динамически порождать программные объекты и уничтожать их, что дает возможность использовать память машины более эффективно.
Связанные списки данных. Несмотря на богатый набор типов данных в Паскале, он не исчерпывает всего практически необходимого для разработки многих классов программ. В частности, из разнообразных связанных структур данных в языке стандартизированы массивы и файлы, а кроме них могут потребоваться и схожие с ними, но иные структуры. Для них характерны, в частности, следующие признаки:
а) неопределенное заранее число элементов;
б) необходимость хранения в оперативной памяти.
Средство для реализации таких структур дает аппарат динамических переменных. Простейшей из обсуждаемых структур является однонаправленный список. Он строится подобно очереди на прием к врачу: пациенты сидят на любых свободных местах, но каждый из них знает, за кем он в очереди (т.е. данные размещаются на свободных местах в памяти, но каждый элемент содержит ссылку на предыдущий или следующий элемент). Поскольку количество пациентов заранее не очевидно, структура является динамической.
Другая подобная структура - стек. Его моделью может служить трубка с запаянным концом, в которую вкатывают шарики. При этом реализуется принцип «последним вошел - первым вышел». Возможное количество элементов в стеке не фиксировано.
Остановимся на примере стека и покажем его программную реализацию. Технически при этом следует решить ряд задач, из которых наиболее специфическими являются
а) связывание последующих компонентов стека;
б) смещение ссылок при каждом движении по стеку.
Из-за необходимости хранить не только значение каждого элемента, но и соответствующую ссылку на последующий элемент, каждый из элементов будем хранить в виде двухполевой записи, в которой первое поле - значение элемента, а второе - ссылка на следующий элемент. Схематически эту структуру можно описать следующим образом
(элементу, который пришел первым, ссылаться не на что, о чем свидетельствует «пустая ссылка» nil).
Ниже приведены примеры создания и уничтожения списков, добавление и удаление элементов из списка на Delphi. Рассмотрены только для однонаправленного и двунаправленного списков для остальных даны примеры в демонстрационной программе.
Type
List = ^Spisok; - Однонаправленный
Spisok = record
Info: Integer; - Информационное поле
Next: List; - Ссылка на следующий элемент
end;
ListTwo = ^SpisokTwo; - Двунаправленный
SpisokTwo = record
Info: Integer; - Информационное поле
Next: ListTwo; - Ссылка на следующий элемент
Prev: ListTwo; - Ссылка на предыдущий элемент
end;
Создание списка
procedure CreateLists; - процедура создания списка
begin
X := Random(101); Определяем значение первого элемента
Uk := nil; Указателям присваиваем nil.
q := nil;
AddToList (X, Uk); Добавляем элемент Х в список.
q := Uk; Формируем указатель на начало списка.
for i := 1 to 9 do Добавляем оставшиеся элементы в список.
begin
X := Random(101);
AddToList (X, q);
end;
ListBegin := Uk; Определяем указатель списка.
end;
Уничтожение списка
procedure DestroyList (PointerBegin: List); Процедура уничтожения списка
(PointerBegin – указатель на начало списка).
begin
while PointerBegin <> nil do Если указатель не nil, то
begin
q := PointerBegin;
PointerBegin := PointerBegin ^.Next; Ссылка на следующий.
if q <> nil then Dispose(q); Уничтожение.
end;
end;
Добавление элемента в список
procedure AddToList(X: Integer; var PointerEndList: List);
Добавить элемент в конец списка
(PointerEndList - указатель на последний элеменBЀ списка)
begin
if PointerEndList = nil then
Если первый элемент еще не существует или список пуст, то
begin
New(PointerEndList); Создаем новую переменную
PointerEndList ^.Info := X; Инф. Части присваиваем элем. Х
PointerEndList ^.Next := nil; Ссылке на следующий - nil
end
else иначе добавляем в список
begin
New(PointerEndList ^.Next); Создаем новую ссылку
PointerEndList := PointerEndList ^.Next;
Указателю присвоить ссылку на след. элемент
PointerEndList ^.Info := X;
PointerEndList ^.Next := nil;
end;
end;
Удаление элемента из списка.
procedure DeleteFromList(Position: Integer);
Удаляет элемент под номером Position
begin
q := ListBegin; Присваивается ссылка на первый элемент
if q <> nil then Если список не пуст, то
begin
if Position = 0 then Если позиция = 0, то удаляем первый элемент
begin
ListBegin := q^. Next;
if q <> nil then Dispose(q);
end
else
begin
i := 0;
while (i < Position - 1) and (q <> nil) do
Ищем элемент после которого нужно удалить
begin
q := q^. Next;
Inc(i);
end;
r := q^. Next;
if r <> nil then Если удаляемый элемент существует, то удаляем его
begin
q^. Next := r^. Next;
if r <> nil then Dispose(r);
end
end;
end
end;
Глава 2. Разработка факультативного курса «Динамические типы данных» 2.1 Методические рекомендации по введению факультативного курса в школеВ системе школьных факультативов необходимо изучение информатики с большей полнотой. Это требует в свою очередь особенно тщательного отбора материала который может быть хорошо усвоен учащимися за ограниченное количество часов.
Разработанный нами факультатив рассчитан на 14 часов.
Задачи факультатива:
1) Ввести понятие линейного списка, однонаправленного и двунаправленного списка, циклического списка, стека, дека и очереди;
2) Сформировать познавательный интерес у учащихся к информатике;
3) Развить у учащихся творческие способности.
Цель первого урока – дать учащимся на качественном уровне необходимый подготовительный материал, который включает в себя:
1) Определение линейного списка.
2) Операции со списками.
3) Виды списков.
4) Связанное распределение.
5) Динамические переменные.
На 2 – 6 уроках учащиеся знакомятся со списками более глубже. Седьмой урок итоговый. Учащимся предлагается тестовая программа, в которой они отвечают на вопросы и оценивают результаты полученных знаний. В целом же факультатив рассчитан на семь двух часовых занятий.
Общая структура факультатива такова:
| № урока | Тема | Кол-во часов |
| №1. | Списки | 2 |
| №2. | Однонаправленный и двунаправленный список | 2 |
| №3. | Циклический список | 2 |
| №4. | Очередь | 2 |
| №5. | Стек | 2 |
| №6. | Дек | 2 |
| №7. | Тест | 2 |
Конспекты уроков
Тема: «Очередь»
Цели:
1. Раскрыть понятие линейного списка «Очередь».
2. Научиться использовать «Очередь» на практике при решении задач.
3. Сформировать у учащихся познавательный интерес к информатике.
| № | Этап урока | Время (мин.) |
| 1. | Организационный момент | 2 |
| 2. | Подготовка к лабораторной работе | 10 |
| 3. | Выполнение лабораторной работы | 20 |
| 4. | Закрепление | 8 |
Лабораторная работа №4 по теме «Очередь».
1. Нажмите кнопку "Теория" для очереди.
Внимательно изучите теоретический материал.
2. Нажмите кнопку "Обновить" для формирования списков.
Кнопки "<< и >>" служат для перемещения курсора по очереди.
а) Переместитесь вправо до 3 элемента;
б) Переместитесь влево (см. коментарии);
Кнопка "Добавить" служит для добавления элемента в очередь.
а) Добавьте 1, 4, 5-м элементами число 99;
б) Добавьте последним число 999;
Кнопка "Удалить" служит для удаления элемента из очереди.
Удалите 1, 2, 3 элементы;
Похожие работы
... ячейка, а имя переменной превращается в адрес ячейки. Появление этого адреса происходит в результате работы специального оператора языка (NEW), однако его значение в большинстве случаев не используется при программировании на алгоритмических языках типа Паскаль. Условимся считать, что адрес ячейки, которая будет хранить переменную А, есть А. Или, другими словами, А - это общее имя переменной и ...
... : 1. Добавление элемента в начало дека. 2. Удаление элемента из начала дека. 3. Добавление элемента в конец дека. 4. Удаление элемента из конца дека. 5. Проверка дека на наличие в нем элементов. Динамические структуры данных: дек В языках программирования существует такой способ выделения памяти под данные, который называется динамическим. В этом случае ...
... с помощью массива или списка, строку с помощью массива или списка. Теперь последовательно рассмотрим вышеперечисленные структу- ры данных и их представление через более прстые применимо к языку Pascal. 2.2 _Массив Переменная или константа, имеющая структуру массива, являет- ся совокупностью элементов одного и того же типа. Каждая от- дельная компонента массива ...
... с адресом р. В повседневной практике средства работы с адресами используются довольно редко. Основное назначение указателей состоит в том, чтобы обеспечить механизм использования в программе динамических переменных. Этот механизм мы и будем обсуждать подробно в следующих разделах. 1.2. Описание указателей В Pascal имеются два различных вида указателей: типизированные и нетипизированные. ...
0 комментариев