Веб-страницы и веб-приложения. 235
Основные возможности Shell
Некоторые специальные команды
История команд
Управляющие структуры скриптов
Алиасинг
Xxx tt
Старт X Window
Инсталирование периферии на примере ленточного накопителя
Операции над файловой системой
После того как отработает конфигурационный скрипт, достаточно набрать make, потом make install и можно приступать к конфигурированию сервера
Следующие, решите вопросы по функциональности ресурса
Навигация
Старт X Window
Администрирование локальных сетей
374863
знака
43
таблицы
0
изображений
4.1 Старт X Window
Для старта системы X Window нужно запустить команду x11start. Он стартует программу xinit которая запускает Х сервер и клиентов а также оконный менеджер в зависимости от конфигурационного файла .x11start.
4.2 X ресурсы
Ресурсы определяют поведение программ (геометрия, цвета, шрифты, поведение клавиатуры, ….). Существует несколько способов позволяющих их изменять:
· Опции командной строки
· .Xdefaults файл
· загрузка ресурсов через менеджер ресурсов
· application resource файлы (app-delaults файлы)
Менеджер ресурсов xrdb
xrdb [option] filename
основные опции:
-load ресурсы загружаемые из файла перезаписывают сущестивующие
-merge ресурсы загружаемые из файла обьеденяются с сущестивующими
-remove ресурсы указаные в файле удаляются из собственности менеджера
ресурсов.
-edit поместить ресурсы собственности менеджера в файл
Для задания ресурсов используют строку вида:
[client_name] * resource: value
или
[client_сlass] * resource: value
Имена и классы клиентовКаждый Х клиент имеет имя и класс. Имя определяет специфического клиента а класс категорию клиента. Ресурсы определенные через имя клиента имеют больший приоритет перед теми что определены через класс клиента. Для лучшего понимания ресурсы определенные через класс пишуться с большорй буквы. Назначить имя клиенту можно при его старте:
xterm –name myTerminal
чтобы получить к ним доступ достаточно загрузить в ресурс менеджер следующие строки:
Xterm.name: myTerminal
MyTerminal*background: green
Имена и классы ресурсовРесурсы как и классы имеют имена и классы. Индивидуальные пишутся с маленькой буквы. Ресурс класса всегда ссылается на класс ресурсов. Поэтому если ресурс *background: red сделает все тоновые цвета красными, то *Background: red сделает красными те ресурсы которые принадлежат к классу Background к которым могут принадлежать cursorColor, pointerColor … Индивидуальные ресурсы всегда имеют приоритет перед ресурсами классов. Это демонстрирует следующий пример ресурсного файла:
*Foreground: red
Xterm*Foreground: gray
Xterm*foreground: yellow
Xterm*CursorColor: green
В именах ресурсов возможно употребление символа * на первом месте. Нарример ресурс *foreground будет обозначать цвет тона всех приложений, в отличии от xterm*foreground только xterm-a.
Типы ресурсовПомимо того что каждое приложение может использовать свои собственные ресурсы, существует огромное количество стандартизированых ресурсов. Напрример рассмотренные выше цвета которые можно задавать и в RGB представлении (соответствие между именем цвета и RGB содержится в файле /usr/X11/lib/rgb.txt). Помимо них к стандартным ресурсам относятся геометрические (width, height, column, row), шрифты (Font, FontList, FontSet) и.т.п.
Управление шрифтамиВ системе X11 шрифты бывают двух видов: bitmap (растровые) шрифты и scalable typeface (векторные). Растровый шришт состоит из набора файлов в каждом из которых хранятся символы определенного размера. С растровыми шрифтами напрямую может работать Х сервер и Font сервер. Векторный шрифт перед тем как должен быть выведен на дисплей проходит серию математических обработок после которых он превращается в растровый определенного размера, начертания и.т.п. Если Х сервер желает работать с векторными шрифтами, он должен их получить от Font сервера.
Настройка путей поиска шрифтов. Команда xset.
В качества источника шрифтов для Х сервера может выступать либо директория, либо Font сервер который принимает соединения на определенный TCP порт (tcp/<hostname>:portnumber). Путь поиска может быть установлен командой xset.
xset option
где option может принимать следующие значения:
q выводит информацию о системе X11 включая fontpath
-fp source[,source …] удаляет источник с начала (-fp) или с конца (fp-) пути
fp- source [,source] поиска шрифтов
+fp source[,source …] добавляет источник к началу (+fp) или к концу (fp+) пути
fp+ source [,source] поиска шрифтов
fp= source [,source] назначает fontpath
fp default сбрасывает fontpath в значение по умолчанию
fp rehash заставляет сервер перечитать базу шрифтов (это нужно в тех
случаях когда изменялось содержимое директорий со
шрифтами)
Получение списка шрифтов доступных в системе. Команда xlsfont
xlsfont [-option]
Где option
-display host:display Х сервер с которого нужно получить листинг шрифтов
-l генерировать маленький листинг
-ll генерировать большой листинг
-lll генерировать очень большой листинг
-n количество колонок для листинга
-w ширина каждой колонки для листинга
В выводимом листинге могут быть как шрифты так и алиасы, последние имеют короткое название.
Использование Font сервера.
Фонт сервер позволяет иметь одну единственную точку с которой все Х сервера будут загружать шрифты, что существенно облегчит конфигурирование систем с большим количеством Х серверов. Кроме того как было сказано выше, если Х сервер хочет работать с векторными шрифтами – он должен это делать исключительно через фонт сервер.
Запуск фонт сервера (если он не был запущен предварительно) осуществляется командой:
/usr/X11/bin/fs –daemon –port <TCP_port>
Для того чтобы фонт сервер запускался во время старта, нужно разрешить его автостарт выполнив:
/etc/set_parms font_c-s
Конфигурационный файл фонт сервера находится в каталоге /etc/X11/fs/config . По сигналу SIGUSR1 он перечитывает свою конфигурацию.
Описание шрифтов. XLFD формат.
Стандарт Х11 предусматривает язык описания шрифтов XLFD (X Logical Font description). Согласно ему имя шрифта состоит из 15 позиций разделенных минусами:
FontNameRegistry-Foundry-FamilyName-Weightname-Slant-SetwidthName-AddStyle-Name-PixelSize-PointSize-ResolutionX-ResolutionY-Spacing-AverageWidth-CharSetRegistry-CharSetCoding
Каким именно будет результирующее имя в XLFD формате зависит от типа фонт-запроса к Х серверу. Возможные типы запросов:
Reference XLFD Этот запрос идет при выполнениии команды xlsfonts и имя
берется из файла fonts.dir . Векторные шрифты при этом имеют PixelSize и PointSize нулевыми.
Request XLFD В результате этого запроса будет получено XLFD имя
запрашиваемого шрифта или его алиас из файла font.alias. При этом поля содержащие * (обозначающие любое значение) будут заменены на ?
resolved XLFD Это уже точное имя шрифта которое выддается сервером в ответ на запрос. Все поля являются заполненными, но результат может и не совпадать с исходным запросом.
XLFD синтаксис
FontNameRegistry авторитетный источник который зарегистрировал шрифт. Обычно пустое поле J
Foundry имя “оцифровщика” шрифта
FamilyName трейд-марка или коммерческое имя шрифта
WeightName[ext] относительный вес шрифта (жирность). Для векторных шрифтов может обозначать темность или светлось (параметр ext)
Slant[ext] напрвление шрифта (roman, italic, oblique, …) для векторных шрифтов параметр задает наклов в угловых единицах.
SetwithName ширина юнита (сжатый или растянутый)
AddStyleName[ext] название для уникальной идентификации шрифта (serife, cursive, …) В векторных шрифтах определят степень поворота или зеркальность шрифта.
PixelSize[ext] высота шрифта в пикселях. Для векторных шрифтов параметр указывает дополнительную растяжку по горизонтали.
PointSize[ext] размер кубика в поинтах.
ResolutionX Разрешение (горизонтальное и вертикальное) шрифта в
ResolutionY пикселях на инч. Если не указано сервер выбирает сам в зависимости от разрешения дистплея.
Spacing расстояние между юнитами в шрифте. (М – фиксированное,
Р – пропорциональное)
AverageWidth Cредняя ширина шрифта
CharacterSetRegistry имя закрепленное X консорциумом за CharacterSetEncoding
CharacterSetEncoding определяет кодировку
Файл font.dir
Этот файл находится в каталогах файлов фонтов, он создается либо при инсталяции системы либо после выполнения команды mkfontdir для растровых или stmkdirs для векторных шрифтов. Он содержит в первой строчке количество шрифтов в директории а в последующих XLFD названия шрифтов.
Файл font.alias
Этот файл так же как и font.dir содержится в каталогах шрифтов и служит для лиасинга
длинных имен шрифтов в короткие которые затем легче использовать. После правки этого файла обязательно нужно выполнять команду
xset fp rehash
а также рестартовывать по сигналу SIGUSR1 фонт сервер.
Администрирование растровых шрифтов.
Для добавления растрового шрифта в систему нужно выполнить следующие действия:
· Если шрифт не в .pcf формате сконвеертировать его с помощью программы bdftopcf
· Скомпрессировать шрифт утилитой compress
· Скопировать в нужную директорию
· Запустить mkfontdir для модификации fonts.dir файла.
· Если директория со шрифтами используется только Х сервером то выполнить xset fp rehash , если она используется еще и фонт сервером то рестартовывать по сигналу SIGUSR1 фонт сервер.
Для удаления растрового шрифта из системы Х11 необходимо:
· Удалить фонт файл.
· Запустить mkfontdir для модификации fonts.dir файла.
· Если директория со шрифтами используется только Х сервером то выполнить xset fp rehash , если она используется еще и фонт сервером то рестартовывать по сигналу SIGUSR1 фонт сервер.
Для создания fonts.dir файла достаточно запустить mkfontdir указав ей в качестве аргумента директорию со шрифтами.
Компилирование .BDF шрифтов в .PCF шрифты.
Растровые шрифты в системе Х11 могут быть представлены в нескольких формах:
· .pcf Переносимый бинарный формат описания шрифта
· .pcf.Z компрессированный .pcf
· .bdf текстовый формат
· .bdf.Z компрессированный .bdf
· .bcf компрессированный .bdf
· .snf не переносимый бинарный формат шрифта (использовался до X11R5)
· .snf.Z компрессированный .snf (использовался до X11R5)
· .scf компрессированный .snf (использовался до X11R5)
·
Предпочтительным форматом для Х сервера является компрессированый .pcf.
Для конвертации .bdf в .pcf с одновременной компрессией можно воспользоваться командой:
bdftopcf font_file.bdf | compress > font_file.pcf.Z
4. Программирование на HP-UX
Для создания выполняемых програм, нужно скомпилировать исходный код где содержиться главная програма.
Расмотрим пример компиляции.
$ cc –Aa myprog.c
Процес компиляции покадет все сообщения (статус,предупреждения, ошибки) на стандартный поток вывода ошибок (stderr). После этого компилятор создаст файл a.out который уже можно запускать. Аналогично можно скомпиларовать Фортрановскую прогамму командой f77. Если програма состоит из несколько файлов, то омпиляция будет выглядет следующем образом:
$ cc –Aa main.c myfunc.c
main.c:
myfunc.c:
после этого можно будет запускать a.out.
Можно сказать что процес компиляции похожий как на рисунке:
На самом деле процесс компиляции намноого сложнее. Этот процес компиляции занимает несколько этапов.
1) Для каждого исходного файла запускаеться компилятор который создает обьектный файл (если исходные коды написаны на разных языках програмирования, то для каждого запускаеться тот соотвествующий компилятор)
2) После компиляция (этап создания) обьектных файлов запускаеться линковщик (HP-UX linker (ld))
На картинке можете увидеть более детальный процес компиляции:
Для более детального просмтотра этапов прохождения компиляции, можно посмотреть задав опцию –v (verbose)
$ cc -Aa -v main.c myfunc.c
cc: CCOPTS is not set.
main.c:
/opt/langtools/lbin/cpp.ansi main.c /var/tmp/ctmAAAa16327 -D__hp9000s700 -D__hp9000s800 -D__hppa -D__hpux -D__unix -D_PA_RISC1_1
cc: Entering Preprocessor.
/opt/ansic/lbin/ccom /var/tmp/ctmAAAa16327 main.o -Oq00,al,ag,cn,Lm,sz,Ic,vo,lc,mf,Po,es,rs,sp,in,vc,pi,fa,pe,Rr,Fl,pv,pa,nf,cp,lx,st,ap,Pg,ug,lu,dp,fs,bp,wp! -Aa
myfunc.c:
/opt/langtools/lbin/cpp.ansi myfunc.c /var/tmp/ctmAAAa16327 -D__hp9000s700 -D__hp9000s800 -D__hppa -D__hpux -D__unix -D_PA_RISC1_1
cc: Entering Preprocessor.
/opt/ansic/lbin/ccom /var/tmp/ctmAAAa16327 myfunc.o -Oq00,al,ag,cn,Lm,sz,Ic,vo,lc,mf,Po,es,rs,sp,in,vc,pi,fa,pe,Rr,Fl,pv,pa,nf,cp,lx,st,ap,Pg,ug,lu,dp,fs,bp,wp! -Aa
cc: LPATH is /usr/lib/pa1.1:/usr/lib:/opt/langtools/lib:
/usr/ccs/bin/ld /opt/langtools/lib/crt0.o -u main main.o myfunc.o -lc
cc: Entering Link editor.
Из этого примера можно посмотреть такие этапы
cpp.ansi это С препроцесор после этого запускаеться /lib/ccom – эта програма(компилятор) уже создает .о файлы. Последний этап это этап создания исполняемого кода, это Линкер, которые связывает все обьекты .
Что такое Обьектный файл ?
Обьектный файл содержет машиные инструкции а данные с которых линкеровщик создает исполняемую програму. Каждий обьектный файл содержит НАЗВАНИЕ (symbol name) и ссылку на это название.
Названия делятся на 3 категории:
1) Локальные обьявления (local definition) – это коды или данные которые могут использоваться только в том обьектном файле где они обьявленые.
2) Глобальные обьявления (global definition) – это обьявления прорцедур,функций,данных котоые могут быть доступны из других обьектных файлов
3) Внешние ссылки (extern references) – это обьявления которые глобальный инаходяться в других обьектных файлах.
Для просмотра обявлений успользуеться програма nm.
Этап линкирования.Линкирование это последний этап создания запускания файлов, он в включает в a.out файл все ссылки обьявлений и их реализации , которые встречаються в програме. Если например есть сылка а нет реализаци то линкировщик скажет что не находит внешнего обявления и выдаст следюющее:
$ cc main.c
/bin/ld: Unsatisfied symbol:
my_func (code)
Работа с библиотеками
Очень полезным средсвом для хранения сылски реализаций внешних обьявлений есть библиотеки. Стандартная библиотека libc которая содержит «основные» функции для C,Fortran
Библиотеки называються libname.sfx
Name – название библиотеки, которая идентефецирует библиотеку
Sfx - если .а – архив, .sl – общедоступная библиотека.
Для того что б указать компилятору библиотеку то указываеться через опцию –l. Например
--lm (подключает стандартну математическую библиотеку libm.a).
По умолчанию подключаються библиотеки libcl,libisamstub,libc.
По умолчанию библиотеки ищатся по путям /lib,/usr/lib,lib/libp. Можно задать пути где искать:
1) Переменой коружения LPATH
2) Опция линкера -L
Также для каждой програмы входит обьектный файл /lib/crt0.o В этом файле содержаться таочки входа в програму,простомтр аргументов и прочее.
Можна прочитать о фунциях которые есть в стандартных библиотеках исполюзую man-page
Вызовы (функции) описываються следующим образом
Name(nL)
Name – название
N – 2-системные вызовы, 3-другие библиотеки
L – буква которая означает к которой библиотеке вызов относиться
Вот примеры:
| Група | Описание |
| (2) | Системные вызовы, низкоуровневый доступ до системных ресурсов. (работа с файлами,сигналы,управление процесами). Все вызовы содержаться в libc |
| (3C) | Стандартные С вызовы . Находяться в libc |
| (3S) | Стандартные вызова input/output (stdio(3S)) Находяться в libc |
| (3M) | Математические фунции. Для подключения используеться –lm или -lM |
| (3G) | Графические фунции |
| (3I) | Библиотека инструментариев |
| (3X) | Разные специализированые библиотеки |
| Сравнительные оценки Архивных и Общедоступных библиотек | ||
| Расширение | .a | .sl |
| Обьектный код | Делаеться с обьектного кода | Делаеться с независимо-позиционого (PIC) обьектного кода.Делаеться компилятором с опцией +z или +Z. |
| Создание | Составляеться обьектные файлы ar командой | Составляеться PIC обьекты с ld командой |
| Связывание адресса вызова | Адресс определяется при линкировании програмы | Адресс определяеться при выполнении програмы |
| a.out | Содержит в себе все вызовы и даные | Содержит только таблицу где где содержаться адреса иназвание библитек |
| При запуске | Каждая програма содержит собственую копию библиотеки | Все програмы используют одну бублиотеку, которая в памяти присутствующая только один раз |
Опции компилятора cc
cс [option] files
· -Amode
· mode=c По умолчанию, стандартный компилятор С (по Керниган, Риттчи)
· mode=a ANSI C (ISO 9899:1990)
· mode=e Расшириное ANSI C
· -c Отменить фазу редактирования связей и создавать об'ектный файл даже в случае программы, состоящей только из одного модуля.
· -p Сгенерировать дополнительные команды для подсчета числа обращений к каждой функции. Кроме того, если имеет место фаза редактирования связей, стандартная подпрограмма инициализации заменяется на такую, которая автоматически вызывает функцию monitor(3C) и обеспечивает запись файла mount.out при нормальном завершении об'ектной программы. Профиль выполнения программы может быть затем получен при помощи команды prof(1).
· -Dname=def определяет макрос для препроцесорра (эквивалентно #define )
· -E посылает на стандартный поток вывода (по умолчанию на stderr)
· -g содержит дополнительную информацию для отладки
· -Idir Изменить алгоритм поиска включаемых (посредством директивы #include) файлов, имена которых не начинаются с символа /, а именно: сначала искать в указанном каталоге, а затем уже в каталогах стандартного списка. Так, включаемые файлы, чьи имена заданы в двойных кавычках, сначала ищутся в каталоге, содержащем файл, затем в каталогах, указанных с помощью опции -I, а затем уже в каталогах стандартного списка. Включаемые файлы, чьи имена заданы в угловых скобках, не ищутся в каталоге, содержащем файл.
· -lname включает библиотеку
· -L dir dir= Дополнить каталогом список каталогов, которые содержат об ектные библиотечные модули [для редактирования связей посредством ld
· -v расширынай информация о процессе компиляции
· -w не показывает предупреждений
· -Wx,arglist передает аргументы (опции) arglist для процеса. x
может принимать значения:
· d Driver
· p Preprocessor
· c Compiler
· a Assembler
· l Linker
· +z,+Z Опция создает PIC код
· -O Включить оптимизацию обьектного кода
Создание архивной библиотеки.1) Для открытия библиотеки необходимо создать оььектные файлы. (в основном каждая функция представляет свой обьектный файл)
2) Соеденить все обьекты в один архив командой ar с ключем r
Описание команды arar [-][d][r][q][t][p][m][x][v][c][l][s] [позиционирующее_имя]
а_файл [имя ...]
Команда ar предоставляет средства обслуживания группы файлов, об единенных в один архивный файл. Применяется главным образом для создания и изменения библиотечных файлов, используемых редактором связей. Может применяться и для других подобных целей. Магические цепочки и заголовки файлов состоят из печатаемых ASCII-символов, так что если в состав архива входят только печатаемые файлы, то и архив в целом окажется печатаемым.
При создании архива командой ar заголовки файлов строятся в формате, не зависящем от конкретной машины. Формат и структура мобильного архива подробно описаны в ar(4). Таблица имен архива (описанная там же) используется редактором связей [ld(1)] для сокращения числа проходов по библиотекам об ектных файлов. Команда ar создает и поддерживает таблицу имен только при наличии в архиве хотя бы одного об ектного файла. Таблица имен в случае ее создания помещается в начале архива в качестве файла с особым именем. Ни ссылка на этот файл, ни доступ к нему для пользователя невозможны. При создании или изменении архива командой ar(1) таблица имен всякий раз перестраивается. Таблицу имен можно перестроить принудительно, воспользовавшись описанной ниже опцией s.
В отличие от командных опций командный ключ составляет обязательную часть командной строки ar. Ключ (которому может предшествовать символ -) представляет собой один из символов набора drqtpmx. Аргументами же ключа могут служить один или несколько символов из набора vuaibcls. Позиционирующее_имя - это имя элемента архива, которое используется в качестве указателя конкретного места архива, куда должны помещаться другие файлы. А_файл - это имя архивного файла. Под именами подразумеваются имена файлов, входящих в архив. Символам, образующим ключ, приписан следующий смысл:
| d | Удалить указанные файлы из архива. |
| r | Заменить указанные файлы в архиве. Если в ключе наряду с r присутствует необязательный символ u, то замена будет произведена только для тех из указанных файлов, у которых дата последней модификации превышает соответствующую дату у одноименных файлов, хранящихся в архиве. Если ключ содержит признак позиционирования, т.е. один из необязательных символов abi, то в команде должен присутствовать аргумент позиционирующее_имя и в этом случае все новые файлы будут помещаться перед (b или i) или вслед за (a) файлом с таким именем. При отсутствии признака позиционирования новые файлы будут помещаться в конец архива. |
| q | Быстро поместить указанные файлы в конец архива. Использование символов позиционирования недопустимо. Проверка, имеются ли уже в архиве указанные файлы, командой не осуществляется. Данная возможность полезна только для того, чтобы избежать квадратичного роста временных затрат при наращивании больших архивов. Отказ от проверок может, напротив, повести к росту размеров архивного файла. |
| t | Вывести оглавление архива. Если имена не указаны, перечисляются все файлы архива; если имена указаны, выводятся только они. |
| p | Напечатать указанные файлы из архива. |
| m | Переместить указанные файлы в конец архива. Если ключ содержит признак позиционирования, то в команде должен присутствовать аргумент позиционирующее_имя, и тогда место, куда перемещаются файлы, будет определяться так же, как и для опции r. |
| x | Извлечь указанные файлы из архива и поместить в текущий каталог. Если имена не указаны, извлекаются все содержащиеся в архиве файлы. Операция не изменяет архивный файл. |
Аргументам ключа приписан следующий смысл:
| v | Вывести подробное, файл за файлом, описание процедуры создания нового архивного файла из старого архива и указанных в команде файлов-компонентов. При совместном использовании ключа t и аргумента v выводится подробная информация о каждом файле. При совместном использовании x и v по мере извлечения файлов будут выводиться их имена. |
| c | Подавить сообщение, выдаваемое обычно при создании а_файла. |
| l | Помещать временные файлы в локальный (текущий рабочий) каталог, а не в подразумеваемый временный каталог TMPDIR. |
| s | Принудительно регенерировать таблицу имен архива, даже если вызов не предусматривает модификации содержимого архива. Эта команда полезна при восстановлении таблицы имен после применения к архиву команды |
Первый шаг в создание общедоступной библиотеки должен создать объектные файлы,
cодержащий переместимый код (PIC). Имеются два способа создать
PIC объектные файлы:
· Компилировать исходные файлы с + z или + Z опция компилятора, описанная ниже.
· Записать программы на языке ассемблера, которые используют соответствующее адресование режимы
·
+ z и + Z параметры вынуждают компилятор генерировать PIC объектные файлы.
ПримерПредположите, что Вы имеете некоторые функции C, сохраненные в length.c, которые конвертируют(преобразовывают) между Английскими и Метрическими модулями длины. Для компилиции эти подпрограммы и создайние PIC объектных файлов с компилятором C, Вы можете бы использовать эту команду:
$ cc -Aa -c +z length.c
+z опция создает PIC.
Создание Общедоступной Библиотеки с ldЧтобы создавать общедоступную библиотеку от одного или большее количество PIC объектные файлы, используйте линкер ld, с -b опцией. По умолчанию, ld назовет библиотеку а.out. Вы можете изменять название с -o опцией.
Например, предположите, что Вы имеете три исходных файла C, содержащие подпрограммы, чтобы делать длину, объем, и массовые преобразования модуля. Они названы length.c, volume.c, и mass.c, соответственно. Делать общедоступную библиотеку от этих исходных файлов, сначала компилируют все три файла, использующие +z опцию, затем комбинируют заканчивающиеся .o файлы с ld. Показаны ниже команды, которые Вы использовали бы, чтобы создать общедоступную библиотеку, названную libunits.sl:
$ cc -Aa -c + z length.c volume.c mass.c
length.c:
volume.c:
mass.c:c:
$ ld -b -o libunits.sl length.o volume.o mass.o
Как только библиотека создана, убедитесь наличия прав читения и выполнения.Но можна выставить права такой командой
$ chmod +r+x libunits.sl
Например, если Вы имеете программу c названным convert.c, который вызываетподпрограммы с libunits.sl, Вы могли бы компилироватьИ связь это с командой cc:
$ cc -Aa convert.c libunits.sl
Как только выполнимая программа создана, библиотека не должна быть перемещена потому что
абсолютное имя пути библиотеки сохранено в выполнимой программе
Модифицирование Общедоступной БиблиотекиКоманда ld не может заменять или удалять объектные модули в общедоступной библиотеке. Поэтому, чтобы модифицировать общедоступную библиотеку, Вы должны повторно связать библиотеку со всеми объектными файлами, которые Вы хотите, чтобы библиотека включила. Например, предположите, что Вы устанавливаете некоторые подпрограммы в length.c (от предыдущего раздела) которые давали неправильные результаты. Чтобы модифицировать libunits.sl библиотеку, чтобы включить эти изменения(замены), Вы использовали бы этот ряд команд:д:
$ cc -Aa -c + z length.c
$ ld -b -o libunits.sl length.o volume.o mass.o
Любые программы, которые используют эту библиотеку, будут теперь использовать новые версии подпрограмм. То есть Вы не должны повторно связать никакие программы, которые используют эту общедоступную библиотеку. Это - то, потому что подпрограммы в библиотеке приложены к программе во время выполнения.я.
Это - одно из преимуществ общедоступных библиотек по библиотекам архива: если Вы изменяете(заменяете) библиотеку архивов, Вы должны повторно связать любые программы, которые используют библиотеку архивов. С общедоступными библиотеками, Вы должны только освежить библиотеку.
Применение make
Создание программы частенько начинается с маленького однофайлового проекта. Проходит некоторое время и проект, как снежный ком, начинает обрастать файлами, заголовками, подключаемыми библиотеками, требуемыми опциями компиляции... и для его сборки становится уже недостаточным сказать "cc -o file file.c". Когда же, через пару дней, однажды набранная магическая строчка, содержащая все необходимые для сборки проекта параметры компилятора, таинственно исчезает в недрах истории вашего командного интерпретатора, рождается естественное желание увековечить свои знания в виде, к примеру, шелл скрипта. Затем, возможно, захочется сделать этот скрипт управляемым параметрами, чтобы его можно было использовать для разных целей... Однако, чудо юникса состоит в том, что если вам что-то понадобилось, значит кто-нибудь это уже сделал, и пришло время вспомнить о существовании команды make.
Рассмотрим несложную программу на C. Пусть программа prog состоит из пары файлов кода main.c и supp.c и используемого в каждом из них файла заголовков defs.h. Соответственно, для создания prog необходимо из пар (main.c defs.h) и (supp.c defs.h) создать объектные файлы main.o и supp.o, а затем слинковать их в prog. При сборке вручную, выйдет что-то вроде:
cc -c main.c defs.h
cc -c supp.c defs.h
cc -o prog main.o supp.o
Если мы в последствии изменим defs.h, нам понадобится полная перекомпиляция, а если изменим supp.c, то повторную компиляцию main.о можно и не выполнять. Казалось бы, если для каждого файла, который мы должны получить в процессе компиляции указать, на основе каких файлов и с помощью какой команды он создается, то пригодилась бы программа, которая во-первых, собирает из этой информации правильную последовательность команд для получения требуемых результирующих файлов и, во-вторых, инициирует создание требуемого файла только в случае, если такого файла не существует, или он старше, чем файлы от которых он зависит. Это именно то, что делает команда make! Всю информацию о проекте make черпает из файла Makefile, который обычно находится в том же каталоге, что и исходные файлы проекта.
Простейший Makefile состоит из синтаксических конструкций всего двух типов: целей и макроопределений.
Цель в Makefile - это файл(ы), построение которого предполагается в процессе компиляции проекта. Описание цели состоит из трех частей: имени цели, списка зависимостей и списка команд интерпретатора sh, требуемых для построения цели. Имя цели - непустой список файлов, которые предполагается создать. Список зависимостей - список файлов, из которых строится цель. Имя цели и список зависимостей составляют заголовок цели, записываются в одну строку и разделяются двоеточием. Список команд записывается со следующей строки, причем все команды начинаются с обязательного символа табуляции. Возможна многострочная запись заголовка или команд через применение символа "\" для экранирования конца строки. При вызове команды make, если ее аргументом явно не указана цель, будет обрабатываться первая найденная в Makefile цель, имя которой не начинается с символа ".". Примером для простого Makefile может послужить уже упоминавшаяся программа prog:
prog: main.o supp.o
cc -o prog main.o supp.o
main.o supp.o: defs.h
В прведенном примере можно заметить ряд особенностей: в имени второй цели указаны два файла и для этой же цели не указана команда компиляции, кроме того, нигде явно не указана зависимость объектных файлов от "*.c"-файлов. Дело в том, что команда make имеет предопределенные правила для получения файлов с определенными суффиксами. Так, для цели - объектного файла (суффикс ".o") при обнаружении соответствующего файла с суффиксом ".c", будет вызван компилятор "сс -с" с указанием в параметрах этого ".c"-файла и всех файлов - зависимостей. Более того, в этом случае явно не указанные ".c"-файлы make самостоятельно внесет в список зависимостей и будет реагировать их изменение так же, как и для явно указанных зависимостей. Впрочем, ничто не мешает указать для данной цели альтернативную команду компиляции.
Вы вероятно заметили, что в приведенном Makefile одни и те же объектные файлы перечисляются несколько раз. А что, если к ним добавится еще один? Для упрощения таких ситуаций make поддерживает макроопределения.
Макроопределение имеет вид "ПЕРЕМЕННАЯ = ЗНАЧЕНИЕ". ЗНАЧЕНИЕ может являться произвольной последовательностью символов, включая пробелы и обращения к значениям уже определенных переменных. В дальнейшем, в любом месте Makefile, где встретится обращение к переменной-макроопределению, вместо нее будет подставлено ее текущее значение. Обращение к значению переменной в любом месте Makefile выглядит как $(ПЕРЕМЕННАЯ) (скобки обязательны, если имя переменной длиннее одного символа). Значение еще не определенных переменных - пустая строка. С учетом сказанного, можно преобразовать наш Makefile:
OBJS = main.o supp.o
prog: $(OBJS)
cc -o prog $(OBJS)
$(OBJS): defs.h
Теперь предположим, что к проекту добавился второй заголовочный файл supp.h, который включается только в supp.c. Тогда Makefile увеличится еще на одну строчку:
supp.o: supp.h
Таким образом, один целевой файла может указываться в нескольких целях. При этом полный список зависимостей для файла будет составлен из списков зависимостей всех целей, в которых он участвует, однако создание файла будет производиться только один раз.
В нашем примере мы группировали цели по принципу общих зависимостей, однако существует и альтернативный способ - группировать зависимости по одной цели. В этом случае Makefile будет выглядеть немного иначе, однако его суть не изменится.
OBJS = main.o supp.o
prog: $(OBJS)
cc -o prog $(OBJS)
main.o: defs.h
supp.o: defs.h supp.h
Обычно Makefile пишется так, чтобы простой запуск make приводил к компиляции проекта, однако, помимо компиляции, Makefile может использоваться и для выполнения других вспомогательных действий, напрямую не связанных с созданием каких-либо файлов. К таким действиям относится очистка проекта от всех результатов компиляции, или вызов процедуры инсталляции проекта в системе. Для выполнения подобных действий в Makefile могут быть указаны дополнительные цели, обращение к которым будет осуществляться указанием их имени аргументом вызова make (например, "make install"). Подобные вспомогательные цели носят название фальшивых, что связанно с отсутствием в проекте файлов, соответствующих их именам. Фальшивая цель может содержать список зависимостей и должна содержать список команд для исполнения. Поскольку фальшивая цель не имеет соответствующего файла в проекте, при каждом обращении к ней make будет пытаться ее построить. Однако, возможно возникновение конфликтной ситуации, когда в каталоге проекта окажется файл с именем, соответствующим имени фальшивой цели. Если для данного имени не определены файловые зависимости, он будет всегда считаться актуальным (up to date) и цель выполняться не будет. Для предотвращения таких ситуаций make поддерживает "встроенную" переменную ".PHONY", которой можно присвоить список имен целей, которые всегда должны считаться фальшивыми.
Теперь можно привести пример полного Makefile, пригодного для работы с проектом prog и принять во внимание некоторые часто применяемые приемы:
OBJS = main.o supp.o
BINS = prog
PREFIX = /usr/local
INSTALL = install
INSOPTS = -s -m 755 -o 0 -g 0
CC = gcc
.PHONY = all clean install
all: $(BINS)
prog: $(OBJS)
$(CC) -o prog $(OBJS)
main.o: defs.h
supp.o: defs.h supp.h
clean:
rm -f $(BINS)
rm -f $(OBJS)
rm -f *~
install: all
for $i in $(BINS) ; do \
$(INSTALL) $(INSOPTS) $$i $(PREFIX)/bin ; \
done
Итак, у нас появились три фальшивых цели: all, clean и install. Цель all обычно используется как псевдоним для сборки сложного проекта, содержащего несколько результирующих файлов (исполняемых, разделяемых библиотек, страниц документации и т.п.). Цель clean используется для полной очистки каталога проекта от результатов компиляции и "мусора" - резервных файлов, создаваемых текстовыми редакторами (они обычно заканчиваются символом "~"). Цель install используется для инсталляции проекта в операционной системе (приведенный пример расчитан на установку только исполняемых файлов). Следует отметить повсеместное использование макроопределений - помимо всего, этот прием повышает читабельность. Обратите также внимание на определение переменной $(CC) - это встроенная переменная make и она неявно "сработает" и при компиляции объектных файлов.
Внутренние макросы
Мake поддерживает пять внутренних макросов, полезных при написании правил построения целевых файлов:
$*
Этот макрос является именем файла без расширения из текущей зависимости; вычисляется только для подразумеваемых правил (см. Суффиксы).
$@
Этот макрос заменяется на полное имя целевого файла; вычисляется только для явно заданных зависимостей.
$<
Вычисляется только для подразумеваемых правил или для правила .DEFAULT. Этот макрос заменяется на имя файла, от которого по умолчанию зависит целевой файл. Так, в правиле .c.o макрос $< будет заменен на имя файла с расширением .c. Например, правило для изготовления оптимизированного об ектного файла из файла с расширением .c может быть таким:
.c.o:
cc -c -O $*.c
или
.c.o:
cc -c -O $<
$?
Макрос $? можно использовать в явных правилах make-файла. Этот макрос заменяется на список файлов-источников, которые изменялись позднее целевого файла.
$%
Этот макрос применяется только тогда, когда целевой файл указан в виде библ(файл.o), что означает, что он находится в библиотеке библ. В этом случае $@ заменяется на библ (имя архива), а $% заменяется на настоящее имя файла, файл.o.
Четыре из этих макросов имеют альтернативную форму. Если к любому из этих макросов добавлено F, то он заменяется на соответствующее макросу имя файла без имени каталога; если же добавлено D, то макрос заменяется на остальную часть значения первоначального макроса без последнего символа /, то есть на имя каталога. Так, $(@D) соответствует каталогу из $@. Если каталог не указан, то генерируется текущий каталог (.). Только макрос $? не имеет альтернативной формы.
Библиотеки
Если целевой файл или имя из списка зависимостей содержит скобки, то оно рассматривается как имя архивной библиотеки, а цепочка символов в скобках - как имя элемента библиотеки. Так, и библ(файл.o), и $(БИБЛ)(файл.o) обозначают библиотеку, содержащую файл.o (предполагается, что макрос БИБЛ был предварительно определен). Выражение $(БИБЛ)(файл1.o файл2.o) недопустимо. Правила обработки библиотечных файлов имеют вид .XX.a, где XX - суффикс, по которому будет получен элемент библиотеки. К сожалению, в текущей реализации требуется, чтобы XX отличался от суффикса элемента библиотеки. Например, нельзя, чтобы библ(файл.o) зависел от файл.o явно. Наиболее общее использование интерфейса работы с библиотеками следующее (предполагается, что исходными являются файлы на языке C):
lib: lib(file1.o) lib(file2.o) lib(file3.o)
@echo lib is now up-to-date
.c.a:
$(CC) -c $(CFLAGS) $<
$(AR) $(ARFLAGS) $@ $*.o
rm -f $*.o
Фактически, правило .c.a, приведенное выше, встроено в make. Более интересный, но более ограниченный пример конструкции, поддерживающей работу с библиотеками:
lib: lib(file1.o) lib(file2.o) lib(file3.o)
$(CC) -c $(CFLAGS) $(?:.o=.c)
$(AR) $(ARFLAGS) lib $?
rm $? @echo lib is now up-to-date
.c.a:;
Здесь используется режим подстановки расширений макросов. Список $? определен как множество имен об ектных файлов (в библиотеке lib), чьи исходные C-файлы были изменены. Подстановка заменяет .o на .c. (К сожалению, нельзя еще трансформировать в .c~; однако, это может стать возможно в будущем). Заметим также, что запрещается правило .c.a:, создающее каждый об ектный файл один за другим. Эта конструкция значительно ускоряет обновление библиотек, но становится весьма громоздкой, если библиотека содержит как программы на C, так и на ассемблере.
Отладчик ADB Вызов ADBDызываетcz ADB, выполняя adb (1) команду. Синтаксис:
adb [-w] [-k] [-Idir] [-Ppid ] [objfile [corefile]
Где:
-w Разрешает запись в объектный файл.
-k Сообщает ADB, что объектные и основные файлы являются файлами ядра, так что ADB может исполнять соответствующее управление памятью.
-Idir Определяет каталоги , который содержит команды для ADB.
-Ppid "Принимают" уже процесс выполнения для отладки.
objfile Называет выполнимый объектный файл.
corefile Называет основной загрузочный модуль.
Обычно, вызывая ADB:
adb a.out core
Или более просто:
adb
Потому что настройка по умолчанию для объектного файла - a.out, и core файл - core.
Поставка знаку "минус" (-) для средств названия(имени) файла " игнорирует этот параметр, " как в:
adb a.out -
Чтобы записывать в объектный файл при игнорировании core файла, можна напечатать:
adb -w a.out -
Чтобы отлаживать выполняющийся в настоящее время процесс, вызовите ADB, печатая:
adb -Ppid a.out
Pid или " идентификатор процесса " может быть получен, используя ps (1) команда.
Потому что ADB прерывает нажатия клавиши, Вы не можете использовать сигнал выхода из, чтобы выйти от ADB. Вы должны использовать явный запрос ADB $q или $Q (или CONTROL D) чтобы выйти от ADB.
Использование ADB В интерактивном режиме
Вы работаете в интерактивном режиме с ADB, вводя запросы.
Общая форма для запроса:
[address] [,count] [command] [modifier]
ADB поддерживает текущий адрес, называемый "точкой". Этот адрес подобен в функции к текущему указателю в HP-UX редакторе, vi (1). Когда Вы указываете address, ADB устанавливает точку к тому расположению. ADB тогда выполняет команду command count раз. Вы можете вводить address и count как выражения. Вы создаете эти выражения от символов в пределах программы, которую Вы можете проверять и от десятичного числа, восьмеричных, и шестнадцатеричных целых чисел. Вот списки различных операторы для формирующихся выражений.
Формирующие выражение ОператорыОператор Операция
+ Добавление
- Вычитание или Отрицание
* Умножение
% Целочисленный раздел(деление)
~ Одноместный НЕ
& Поразрядный И
| Поразрядный Содержащий ИЛИ
* Серия к следующему множителю
ADB исполняет арифметические операции на всех 32 битах.
ADB "помнит" последний(прошлый) набор оснований системы счисления. Вы можете изменять(заменять) текущее основание системы счисления с $o, $d, или $x команды. В течение запуска, заданное по умолчанию основание системы счисления шестнадцатерично. Если Вы изменяете(заменяете) основание системы счисления к десятичному числу, весь последующий ввод и вывод целых чисел интерпретируется как десятичное число, пока другой спецификатор основания системы счисления не используется.
Таблица 2 списка некоторые обычно использовала команды ADB и их значение.
Обычно Используемый ADB КомандыКоманда Описание
? Печатает содержание от objfile.
/ Печатает содержание от corefile.
= Печатает значение "точки" (.) (адресс) .
: Контрольной точки останова .
$ Разные запросы.
; Разделитель команд.
! Выйти в Шелл.
CONTROL C Заканчивает любую команду ADB.
Отображение Информации
Вы можете запросить ADB расположения или в объектном файле или core файле. Запрос (?) показывает содержание объектного файла, в то время как / запрос исследует core файл. Как только Вы инициализируете процесс (использование или:r или команда:e), или ? или / обращаются к расположениям в адресном пространстве выполняющего процесса.
После любого ? или / запросов, Вы можете определить формат, что ADB должен использовать, чтобы печатать эту информацию. Таблица 3 списка некоторые обычно используемые команды формата.
Обычно Используемых Команды ФорматаКоманда Описание
c Один байт как символ.
b Один байт как шестнадцатеричное значение.
x Два байта в шестнадцатеричном.
X Четыре байта в шестнадцатеричном.
d Два байта в десятичном числе.
f Четыре байта в единственном(отдельном) с плавающей запятой.
F Восемь байтов в двойном с плавающей запятой.
i Команда Precision Architecture HEWLETT-PACKARD.
s Символьная строка С нулевым символом в конце.
a Печатать в символической форме.
n Печатать newline.
r Печатать пустое пространство.
^ Резервируют точку.
Например, чтобы печатать первый шестнадцатеричный элемент массива длинных целых чисел, названных ints, Вы напечатали бы запрос:
ints/X
Этот запрос устанавливает значение точки к значению таблицы идентификаторов ints. Это также устанавливает значение точечного приращения к четыре. " Точечное приращение " является числом байтов, которые ADB печатает в требуемом формате.
В другом примере, чтобы печатать первые четыре байта как шестнадцатеричный номер после последующих четыре байта как десятичное число, Вы напечатали бы запрос:
ints/XD
В этом случае, ADB все еще устанавливает точку к ints, но точечное приращение - теперь восемь байтов.
Команда newline - специальная команда, которая повторяет предыдущую команду. Команда newline также использует значение точечного приращения, но команда не может всегда иметь значение. В этом контексте, однако, это означает повторять предыдущую команду, используя индекс одних и адрес точки плюс точечное приращение. Так, в этом случае(регистре), команда newline устанавливает точку к ints + 0x8 и печатает два длинных целого числа: первый как шестнадцатеричный номер и второй как десятичное число. Вы можете также повторить команду newline так часто как хотите. Например, Вы могли бы использовать эту методику, чтобы просмотреть разделы памяти.
При использовании этого примера, чтобы иллюстрировать другой пункт, Вы можете печатать первые четыре байта в длинном шестнадцатеричном формате и следующих четырех байтах в байте шестнадцатеричный формат, печатая запрос:
ints/X4b
Как эти примеры, Вы можете предшествовать любой команде формата с десятичным символом повторения.
Кроме того, Вы можете использовать параметр индекса запроса ADB, чтобы повторить, полный формат командует определенным числом раз. Например, чтобы печатать три строки, использующие вышеупомянутый формат, Вы напечатали бы запрос:
ints, 3/X4bn
(n в конце команды печатает перевод каретки, который делает вывод более легким для чтения.)
В этом примере, ADB устанавливает значение точки к ints + 0x10, скорее чем ints. Это случается, потому что каждый раз ADB заново выполняет команду формата, это устанавливает точку к точке плюс точечное приращение. Поэтому, значение точки - значение, которое точка имела в начале последнего(прошлого) выполнения команды формата. Точечное приращение - размер требуемого формата (в этом случае(регистре), восемь байтов). Команда newline в это время установила бы точку в ints + 0x18 и печать только одно повторение(копия) формата, потому что значение индекса сброшено к одному.
Чтобы проверять текущее значение точки, Вы можете напечатать запрос:
. = a
= команда может печатать значение адреса в любом формате.
Вы можете также использовать = команду, чтобы конвертировать(преобразовать) от одного ядра до другого. Например, Вы можете печатать значение "0x32" в восьмеричном, шестнадцатеричном, и представление десятичных чисел, печатая:
0x32 = oxd
ADB "помнит" сложный формат просьбы о каждом из?, /, и = команды. Например, после ввода предыдущего запроса, Вы можете печатать значение "0x64" в восьмеричном, шестнадцатеричном, и представление десятичных чисел, печатая:
0x64 =
Тогда, потому что последний введенный / команда была ints/X4b, Вы можете напечатать:
ints/
Печатать четыре байта в длинном шестнадцатеричном формате и четырех байтах в байте шестнадцатеричный формат.
Дополнительные команды печатиКоманда Описание
$b Печатают текущие контрольные точки.
$c Печать располагает в стеке след.
$d Основание системы счисления значения по умолчанию Набора, чтобы адресовать параметр.
$e Печатают внешние переменные.
$f Регистраторы С плавающей точкой как единственная(отдельная) точность.
$F Регистраторы С плавающей точкой как двойная точность.
$m Печатают карты сегмента ADB.
$r Печатают общих регистраторов.
$s Смещение Набора для соответствия символа.
$v Печатают ADB переменные.
$w Вывод Набора выравнивает ширину.
Рекомендуеться также посмтотреть на лучший Отладчик под Unix:
http://www.kiarchive.ru/pub/gnu/gnu-mirror/Manuals/ddd/html_mono/ddd.html
Отладчик XDB
XDB – отладчик для отлаживания програм написаных на языках C, HP FORTRAN, HP Pascal, and C++ и понимает следующие команды:
xdb [-d dir] [-r file] [-R file] [-p file] [-P process_ID] [-L] [-l library]
[-i file] [-o file] [-e file] [-S num] [-s] [objectfile [corefile]]
где
-d dir определяет дополнительный каталог где размещены исходный коды
-r file определяет рекордный файл
-R file определяет файл restore, который был определен перед –p но после –r опции
-p file определяет файл воспоизведения действий (playback)
-P process_ID Определяет process_ID до которого желаем «присоедениться» чтоб отправить в
режим отладки
-L определяет строчно-ориентированный интерфейс.
-l library определяет библиотеку (общедоступную) до которой желаете подсоедениться
-i file переопределяет поток ввода в файл или в устройство
-o file переопределяет поток вывода в файл или в устройство
-e file переопределяет поток вывода ошибок в файл или в устройство
-S num устанавливает размер кеширования строки (по умолчанию 1024 что есть минимальный) –s определяет все библиотеки (общедоступный) которые использует програма
Размер екрана будет в зависимости от переменой окружения TERM или можно установить используя переменный LINES и COLUMNS.
При запуске xdb имеет 3 окна:
· Окно кода (содержит исходный код)
· Окно информации (содержит значения параметров и прочее)
· Командное окно, окно упраления
5. Примеры командr запускает програму с параметрами
R запускет програму без параметров
s пошаговый запусr (входит в функции)
S пошаговый запусr (не входить в функции)
к убить процесс
q выйти из отладчика
с продолжить выполнения програмы (continue)
v 11 посмотреть 11 строку кода
+5 посмотрить на 5 строк ниже
-5 ---------------------------- выше
v my_function показать функцию
v test1.c просмотреть файл test1.c
v test1.c:40 просмотреть файл test1.c на 40 строке
V посмотреть текущуй стек (сотояний вызовов)
V 2 посмотреть текущей стек на 2 уровня глубже
w 12 установить размер окна кода на 12
td показать код на asssembly языке (что б возвратиться к коду то еще раз нужно набрать td)
ts показать код и asssembly
s 6 запустить 6 шагов
/ n=4 ищет код n=4 (снизу)
? n=4 ищет код n=4 (сверху)
b 42 устанавливает точку останова в 42 строке
b 32 \4 в 32 строке будет останавливаться програма 4 раза
bp устанавливает точку останова на точке входа в програму
bp my_funс устанавливает точку останова на точке входа в процедуру my_func
lb просмотреть точки останова
db 2 удалить 2ю точку остнаова
db * удалить все точки останова
p count просмотреть значение count
p count\x просмотреть в шестнацатиричном виде
p num\D просмотреть переменую в long типе как десятеричную
p . показать преведущее значение
p *(&.+42) показать значение на 42 байта дальше от преведуще-показаного значения
p my_struct показывает даные в структуре
p my_struct.name показывает значение в структуры поля name
p *ptr значения указателя
p+ (p-) показывет следущий(преведущий) елемент
p num=num+20 увеличить значения на 20
t показывает стек
Справочная таблица команд и флагов XDB
h [topic] Print commands/syntaxes related to this topic.
Help without a topic prints the complete help text. Available topics
include command names (short form) which print the syntax for and a
terse description of the command. Other topics are:
assert assertions; macro macros;
bpset set breakpoints; misc other commands, etc.;
bpstat view & modify breakpoints; options xdb command line;
C++ C++ features; proc procedure related;
cmdlist command list features; record write & use log files;
control process control; register registers;
data view & modify data; screen window modes;
disasm disassembly mode; signal signal handling;
formats format specifiers; state global state switches;
help this description; source view source;
list list various items; trace trace stack or proc(s);
locations location syntax; variables variable syntax.
Process control:
r [arguments] Run child process with arguments.
R Run child process with no arguments.
c [location] Continue from breakpoint with no signal, set temporary breakpoint at location.
C [location] Continue with current signal, set temporary breakpoint at location.
s [number] Single step, follow procedure calls.
S [number] Single step, step over procedure calls.
g (line | #label) Go to line in current procedure.
g (+|-) [lines] Go forward/back 1 or given number of lines.
k Kill child process, if any.
Setting breakpoints:
b [location] [\count] [commands] Set breakpoint.
ba [address] [\count] [commands] Set breakpoint at code address.
bb [depth] [\count] [commands] Set breakpoint at procedure beginning.
bi expr.proc [\count] [commands] Set an instance breakpoint.
bi [-c|-C] expr [commands] Set an instance breakpoint.
bp [commands] Set procedure breakpoints.
bpc [-c|-C] class [commands] Set a class breakpoint.
bpo [[class]::]proc [commands] Set breakpoints on overloaded functions.
bpt [commands] Set procedure trace breakpoints.
bpx [commands] Set procedure exit breakpoints.
bt [(depth | proc)] [\count] [commands] Trace procedure.
bu [depth] [\count] [commands] Set up-level breakpoint.
bx [depth] [\count] [commands] Set breakpoint at procedure exit.
bpg [commands] Set paragraph breakpoints. (MPE-only)
tpg [commands] Set paragraph trace breakpoints. (MPE-only)
txc Toggle the exception stop-on-catch state.
txt Toggle the exception stop-on-throw state.
View and modify breakpoint status:
lb List all breakpoints.
lx List exception stop-on-throw and -catch state.
db [number | *] Delete one or all breakpoints.
dp Delete procedure breakpoints.
Dpx Delete procedure exit breakpoints.
Dpt Delete procedure trace breakpoints.
dpg Delete paragraph [trace] breakpoints.(MPE-only)
ab [number | *] Activate one or all breakpoints.
sb [number | *] Suspend one or all breakpoints.
tb Toggle overall breakpoints state.
abc commands Global breakpoint commands.
dbc Delete global breakpoint commands.
bc number expr Set a breakpoint count.
xcc commands Define the stop-on-catch command-list.
xtc commands Define the stop-on-throw command-list.
i expr {commands} [{commands}] Conditionally execute commands. (Also: if)
{ } Group commands.
; Separate commands.
Q Quiet breakpoint reporting.
"any string" Print string.
Source viewing:
L Show current location and its source line.
v [location] View source at location in source window.
va [address] View address in disassembly window.
V [depth] View procedure at depth in source window.
top View procedure at top of stack.
up [number] View procedure number levels higher in stack.
down [number] View procedure number levels lower in stack.
+[number] Move forward in sourcefile.
-[number] Move backward in sourcefile.
/[string] Search forwards in sourcefile for string.
?[string] Search backwards for string.
n Repeat previous search.
N Repeat previous search in opposite direction.
apm old_path [new_path] Add (prefix) path map for source files.
dpm [index | *] Delete path map(s) for source files.
lpm List path maps in order of precedence.
D "dir" Add a directory search path for source files.
ld List all directories.
lf [string] List all (or matching) files.
lsl List all shared libraries.
lp [[class]::][string] List all (or matching) procedures.
lo [[class]::][string] List all (or matching) overloaded functions.
lcl [string] List all (or matching) classes.
lct [string] List all (or matching) class templates.
ltf [string] List all (or matching) function expansions.
lft [string] List all (or matching) function templates.
View and modify data:
p expr [\format] Print value of expression using format.
p expr?format Print address of expression using format.
p -[\format] Print value of prev memory location using format.
p +[\format] Print value of next memory location using format.
p class:: Print static members of class.
l [[class]::][proc[:depth]] List all parameters and locals of proc.
t [depth] Trace stack.
T [depth] Trace stack and show local variables.
tst Toggle stub visibility. (PA-RISC only)
lr [string] List all (or matching) registers.
lc [string] List all (or matching) commons. (PA-RISC only)
lg [string] List all (or matching) globals.
ls [string] List all (or matching) special variables.
mm [string] Show memory-map of all (or matching) loaded shared -libraries.
f ["printf-style-format"] Set address printing format.
disp item [\format] Display Cobol data item value using format.(MPE-only)
move val to item Move value "val" to cobol data item "item" (MPE-only)
pq <<same as p>> Print quietly. Evaluate without printing.
ll [string] List all (or matching) labels.
lz List all signals.
z [number] [i][r][s][Q] Toggle flags (ignore, report, stop, Quiet) for signal.
Screen modes:
am Activate more (turn on pagination).
sm Suspend more (turn off pagination).
w number Set size of source window.
td Toggle disassembly mode.
ts Toggle split-screen mode.
fr Display floating point registers.
gr Display general registers.
tf Toggle float register display precision (PA-RISC only).
sr Display special registers. (PA-RISC only)
u Update screen.
U Refresh source & location windows on screen.
+r Scroll floating point registers forward.
-r Scroll floating point registers backward.
Assertions:
a commands Create a new assertion with a command list.
aa (number | *) Activate one or all assertions.
da (number | *) Delete one or all assertions.
la List all assertions.
sa (number | *) Suspend one or all assertions.
ta Toggle overall assertions state.
x [expr] Exit assertion mode, possibly aborting the assertion command list.
Macros:
def name [replacement-text] Define a macro name.
lm [string] List all (or matching) macros.
tm Toggle the macro substitution mechanism.
undef (name | *) Remove the macro definition for name or all.
Record and playback:
tr [@] Toggle the record [record-all] mechanism.
< file Playback from file.
<< file Playback from file with single stepping.
> file Record commands to file.
>> file Append commands to file.
>@ file Record-all debugger commands & output to file.
>>@ file Append all debugger commands & output to file.
">>" is equivalent to ">" for the next four commands.
> Show status of current recording file.
>@ Show status of current record-all file.
>(t | f | c) Turn recording on (t), or off (f), or close the recording file (c).
>@(t | f | c) Turn record-all on (t), or off (f), or close the record-all file (c).
Misc:
ss file Save (breakpoint, macro, assertion) state.
tc Toggle case sensitivity in searches.
<carriage-return> Repeat previous command.
~ Repeat previous command.
! [command-line] Execute shell (with or without commands).
q Quit debugger.
$addr Unary operator, address of object.
$sizeof Unary operator, size of object.
$in Unary boolean operator, execution in procedure.
# [text] A comment.
I Print debugger status.
M [(t | c) [expr [; expr ...]]] Print or set (text or core) maps.
tM Toggle between default and modifiable core maps.
VARIABLESvar Search current procedure and globals.
class::var Search class for variable.
[[class]::]proc:[class::]var Search procedure for variable.
[[class]::]proc:depth:[class::]var Search procedure at depth on stack.
:var or ::var Search for global variable only.
. Shorthand for last thing you looked at.
$var Define or use special variable.
$result Return value of last cmd line procedure call.
$signal Current child process signal number.
$lang Current language for expression evaluation.
$depth Default stack depth for local variables.
$print Display mode for character data.
$line Current source line number.
$malloc Debugger memory allocation (bytes).
$step Instr. count in non-debug before free-run.
$cplusplus C++ feature control flags.
$regname Hardware registers.
$fpa Treat fpa sequence as one instruction.(S300 only)
$fpa_reg Address register for fpa sequences. (S300 only)
LOCATIONSline source line & code address (if any)
#label "
file[:line] "
[file:]proc[:proc[...]][:line|#label] "
[class]::proc[:line|#label] "
proc#line code address (if any)
[class]::proc#line "
name@shared_lib Address of name in shared library
FORMATSA format has the form [count]formchar[size]. formchar's are:
a String at address.
(b | B) Byte in decimal (either way).
(c | C) (Wide) character.
(d | D) (Long) decimal.
(e | E) E floating point notation (as double).
(f | F) F floating point notation (as double).
(g | G) G floating point notation (as double).
i Machine instruction (disassembly).
(k | K) Formatted structure display (with base classes).
n "Normal" format, based on type.
(o | O) (Long) octal.
p Print name of procedure containing address.
(r | R) Print template of object (with base classes).
s String from pointer.
S Formatted structure display.
(t | T) Print type of object (with base classes).
(u | U) (Long) unsigned decimal.
(w | W) Wide character string (at address).
(x | X) (Long) hexadecimal.
(z | Z) (Long) binary.
Size can be a number or one of the following:
b 1 byte (char)
s 2 bytes (short)
l 4 bytes (long)
D 8 bytes (double - floating point formats only)
L 16 bytes (long double - floating point only)
6. Системные вызовы и взаимодействие с UNIX.В этой главе речь пойдет о процессах. Скомпилированная программа хранится на диске как обычный нетекстовый файл. Когда она будет загружена в память компьютера и начнет выполняться - она станет процессом.
UNIX - многозадачная система (мультипрограммная). Это означает, что одновременно может быть запущено много процессов. Процессор выполняет их в режиме разделения времени - выделяя по очереди квант времени одному процессу, затем другому, третьему... В результате создается впечатление параллельного выполнения всех процессов (на многопроцессорных машинах параллельность истинная). Процессам, ожидающим некоторого события, время процессора не выделяется. Более того, "спящий" процесс может быть временно откачан (т.е. скопирован из памяти машины) на диск, чтобы освободить память для других процессов. Когда "спящий" процесс дождется события, он будет "разбужен" системой, переведен в ранг "готовых к выполнению" и, если был откачан будет возвращен с диска в память (но, может быть, на другое место в памяти!). Эта процедура носит название "своппинг" (swapping).
Можно запустить несколько процессов, выполняющих программу из одного и того же файла; при этом все они будут (если только специально не было предусмотрено иначе) независимыми друг от друга. Так, у каждого пользователя, работающего в системе, имеется свой собственный процесс-интерпретатор команд (своя копия), выполняющий программу из файла /bin/csh (или /bin/sh).
Процесс представляет собой изолированный "мир", общающийся с другими "мирами" во Вселенной при помощи:
a) Аргументов функции main:
void main(int argc, char *argv[], char *envp[]);
Если мы наберем команду
$ a.out a1 a2 a3
то функция main программы из файла a.out вызовется с
argc = 4 /* количество аргументов */
argv[0] = "a.out" argv[1] = "a1"
argv[2] = "a2" argv[3] = "a3"
argv[4] = NULL
По соглашению argv[0] содержит имя выполняемого файла из которого загружена эта программа*.
b) Так называемого "окружения" (или "среды") char *envp[], продублированного также в предопределенной переменной
extern char **environ;
Окружение состоит из строк вида
"ИМЯПЕРЕМЕННОЙ=значение"
Массив этих строк завершается NULL (как и argv). Для получения значения переменной с именем ИМЯ существует стандартная функция
char *getenv( char *ИМЯ );
Она выдает либо значение, либо NULL если переменной с таким именем нет.
c) Открытых файлов. По умолчанию (неявно) всегда открыты 3 канала:
ВВОД В Ы В О Д
FILE * stdin stdout stderr
соответствует fd 0 1 2
связан с клавиатурой дисплеем
#include <stdio.h>
main(ac, av) char **av; {
execl("/bin/sleep", "Take it easy", "1000", NULL);
}
Эти каналы достаются процессу "в наследство" от запускающего процесса и связаны с дисплеем и клавиатурой, если только не были перенаправлены. Кроме того, программа может сама явно открывать файлы (при помощи open, creat, pipe, fopen). Всего программа может одновременно открыть до определенное количество файлов в зависииости от настройки ядра.
d) Процесс имеет уникальный номер, который он может узнать вызовом
int pid = getpid();
а также узнать номер "родителя" вызовом
int ppid = getppid();
Процессы могут по этому номеру посылать друг другу сигналы:
kill(pid /* кому */, sig /* номер сигнала */);
и реагировать на них
signal (sig /*по сигналу*/, f /*вызывать f(sig)*/);
e) Существуют и другие средства коммуникации процессов: семафоры, сообщения, общая память, сетевые коммуникации.
f) Существуют некоторые другие параметры (контекст) процесса: например, его текущий каталог, который достается в наследство от процесса-"родителя", и может быть затем изменен системным вызовом
chdir(char *имя_нового_каталога);
У каждого процесса есть свой собственный текущий рабочий каталог. К "прочим" характеристикам отнесем также: управляющий терминал; группу процессов (pgrp); идентификатор (номер) владельца процесса (uid), идентификатор группы владельца (gid), реакции и маски, заданные на различные сигналы; и.т.п.
g) Издания других запросов (системных вызовов) к операционной системе ("богу") для выполнения различных "внешних" операций.
h) Все остальные действия происходят внутри процесса и никак не влияют на другие процессы и устройства ("миры"). В частности, один процесс НИКАК не может получить доступ к памяти другого процесса, если тот не позволил ему это явно (механизм shared memory); адресные пространства процессов независимы и изолированы (равно и пространство ядра изолировано от памяти процессов).
Операционная система выступает в качестве коммуникационной среды, связывающей "миры"-процессы, "миры"-внешние устройства (включая терминал пользователя); а также в качестве распорядителя ресурсов "Вселенной", в частности - времени (по очереди выделяемого активным процессам) и пространства (в памяти компьютера и на дисках).
Уже неоднократно упоминали "системные вызовы". Что же это такое? С точки зрения Си-программиста - это обычные функции. В них передают аргументы, они возвращают значения. Внешне они ничем не отличаются от написанных нами или библиотечных функций и вызываются из программ одинаковым с ними способом.
С точки же зрения реализации - есть глубокое различие. Тело функции-сисвызова расположено не в нашей программе, а в резидентной (т.е. постоянно находящейся в памяти компьютера) управляющей программе, называемой ядром операционной системы*.
Поведение всех программ в системе вытекает из поведения системных вызовов, которыми они пользуются. Даже то, что UNIX является многозадачной системой, непосредственно вытекает из наличия системных вызовов fork, exec, wait и спецификации их функционирования! То же можно сказать про язык Си - мобильность программы зависит в основном от набора используемых в ней библиотечных функций (и, в меньшей степени, от диалекта самого языка, который должен удовлетворять стандарту на язык Си). Если две разные системы предоставляют все эти функции (которые могут быть по-разному реализованы, но должны делать одно и то же), то программа будет компилироваться и работать в обоих системах, более того, работать в них одинаково.
Сам термин "системный вызов" как раз означает "вызов системы для выполнения действия", т.е. вызов функции в ядре системы. Ядро работает в привелегированном режиме, в котором имеет доступ к некоторым системным таблицам*, регистрам и портам внешних устройств и диспетчера памяти, к которым обычным программам доступ аппаратно запрещен (в отличие от MS DOS, где все таблицы ядра доступны пользовательским программам, что создает раздолье для вирусов). Системный вызов происходит в 2 этапа: сначала в пользовательской программе вызывается библиотечная функция-"корешок", тело которой написано на ассемблере и содержит команду генерации программного прерывания. Это - главное отличие от нормальных Си-функций - вызов по прерыванию. Вторым этапом является реакция ядра на прерывание:
1. переход в привелегированный режим;
2. разбирательство, КТО обратился к ядру, и подключение u-area этого процесса к адресному пространству ядра (context switching);
3. извлечение аргументов из памяти запросившего процесса;
4. выяснение, ЧТО же хотят от ядра (один из аргументов, невидимый нам - это номер системного вызова);
5. проверка корректности остальных аргументов;
6. проверка прав процесса на допустимость выполнения такого запроса;
7. вызов тела требуемого системного вызова - это обычная Си-функция в ядре;
8. возврат ответа в память процесса;
9. выключение привелегированного режима;
10. возврат из прерывания.
Во время системного вызова (шаг 7) процесс может "заснуть", дожидаясь некоторого события (например, нажатия кнопки на клавиатуре). В это время ядро передаст управление другому процессу. Когда наш процесс будет "разбужен" (событие произошло) - он продолжит выполнение шагов системного вызова.
Большинство системных вызовов возвращают в программу в качестве своего значения признак успеха: 0 - все сделано, (-1) - сисвызов завершился неудачей; либо некоторое содержательное значение при успехе (вроде дескриптора файла в open(), и (-1) при неудаче. В случае неудачного завершения в предопределенную переменную errno заносится номер ошибки, описывающий причину неудачи (коды ошибок предопределены, описаны в include-файле <errno.h> и имеют вид Eчтото). Заметим, что при УДАЧЕ эта переменная просто не изменяется и может содержать любой мусор, поэтому проверять ее имеет смысл лишь в случае, если ошибка действительно произошла:
#include <errno.h> /* коды ошибок */
extern int errno;
extern char *sys_errlist[];
int value;
if((value = sys_call(...)) < 0 ){
printf("Error:%s(%d)\n", sys_errlist[errno],
errno );
exit(errno); /* принудительное завершение программы */
}
Предопределенный массив sys_errlist, хранящийся в стандартной библиотеке, содержит строки-расшифровку смысла ошибок (по-английски). Посмотрите описание функции per- ror().
Время в UNIX.Ниже приведены примеры как узнавать время:
. В системе UNIX время обрабатывается и хранится именно в виде числа секунд; в частности текущее астрономическое время можно узнать системным вызовом
#include <sys/types.h>
#include <time.h>
time_t t = time(NULL); /* time(&t); */
Функция
struct tm *tm = localtime( &t );
разлагает число секунд на отдельные составляющие, содержащиеся в int-полях структуры:
tm_year год (надо прибавлять 1900)
tm_yday день в году 0..365
tm_mon номер месяца 0..11 (0 - Январь)
tm_mday дата месяца 1..31
tm_wday день недели 0..6 (0 - Воскресенье)
tm_hour часы 0..23
tm_min минуты 0..59
tm_sec секунды 0..59
Номера месяца и дня недели начинаются с нуля, чтобы вы могли использовать их в качестве индексов:
char *months[] = { "Январь", "Февраль", ..., "Декабрь" };
printf( "%s\n", months[ tm->tm_mon ] );
Часто бывает нужда передавать значения времени в одной строке
Вот пример программы которая преобразовывает в ремя в такой формат:
/* Mon Jun 12 14:31:26 2000 */
#include <stdio.h>
#include <time.h>
main() { /* команда date */
time_t t = time(NULL);
char *s = ctime(&t);
printf("%s", s);
}
UNIX-машины имеют встроенные таймеры (как правило несколько) с довольно высоким разрешением. Некоторые из них могут использоваться как "будильники" с обратным отсчетом времени: в таймер загружается некоторое значение; таймер ведет обратный отсчет, уменьшая загруженный счетчик; как только это время истекает - посылается сигнал процессу, загрузившему таймер.
Вот как, к примеру, выглядит функция задержки в микросекундах (миллионных долях секунды). Примечание: эту функцию не следует использовать вперемежку с функциями sleep и alarm.
#include <sys/types.h>
#include <signal.h>
#include <sys/time.h>
void do_nothing() {}
/* Задержка на usec миллионных долей секунды (микросекунд) */
void usleep(unsigned int usec) {
struct itimerval new, old;
/* struct itimerval содержит поля:
struct timeval it_interval;
struct timeval it_value;
Где struct timeval содержит поля:
long tv_sec; -- число целых секунд
long tv_usec; -- число микросекунд
*/
struct sigaction new_vec, old_vec;
if (usec == 0) return;
/* Поле tv_sec содержит число целых секунд.
Поле tv_usec содержит число микросекунд.
it_value - это время, через которое В ПЕРВЫЙ раз
таймер "прозвонит",
то есть пошлет нашему процессу
сигнал SIGALRM.
Время, равное нулю, немедленно остановит таймер.
it_interval - это интервал времени, который будет загружаться
в таймер после каждого "звонка"
(но не в первый раз).
Время, равное нулю, остановит таймер
после его первого "звонка".
*/
new.it_interval.tv_sec = 0;
new.it_interval.tv_usec = 0;
new.it_value.tv_sec = usec / 1000000;
new.it_value.tv_usec = usec % 1000000;
/* Сохраняем прежнюю реакцию на сигнал SIGALRM в old_vec,
заносим в качестве новой реакции do_nothing()
*/
new_vec.sa_handler = do_nothing;
sigemptyset(&new_vec.sa_mask);
new_vec.sa_flags = 0;
sigaction(SIGALRM, &new_vec, &old_vec);
/* Загрузка интервального таймера значением new, начало отсчета.
* Прежнее значение спасти в old.
* Вместо &old можно также NULL - не спасать.
*/
setitimer(ITIMER_REAL, &new, &old);
/* Ждать прихода сигнала SIGALRM */
sigpause(SIGALRM);
/* Восстановить реакцию на SIGALRM */
sigaction(SIGALRM, &old_vec, (struct sigaction *) 0);
sigrelse(SIGALRM);
/* Восстановить прежние параметры таймера */
setitimer(ITIMER_REAL, &old, (struct itimerval *) 0);
}
Пример оспользования интервалов
#include <stdio.h>
#include <unistd.h> /* _SC_CLK_TCK */
#include <signal.h> /* SIGALRM */
#include <sys/time.h> /* не используется */
#include <sys/times.h> /* struct tms */
struct tms tms_stop, tms_start;
clock_t real_stop, real_start;
clock_t HZ; /* число ticks в секунде */
/* Засечь время момента старта процесса */
void hello(void){
real_start = times(&tms_start);
}
/* Засечь время окончания процесса */
void bye(int n){
real_stop = times(&tms_stop);
#ifdef CRONO
/* Разность времен */
tms_stop.tms_utime -= tms_start.tms_utime;
tms_stop.tms_stime -= tms_start.tms_stime;
#endif
/* Распечатать времена */
printf("User time = %g seconds [%lu ticks]\n",
tms_stop.tms_utime / (double)HZ, tms_stop.tms_utime);
printf("System time = %g seconds [%lu ticks]\n",
tms_stop.tms_stime / (double)HZ, tms_stop.tms_stime);
printf("Children user time = %g seconds [%lu ticks]\n",
tms_stop.tms_cutime / (double)HZ, tms_stop.tms_cutime);
printf("Children system time = %g seconds [%lu ticks]\n",
tms_stop.tms_cstime / (double)HZ, tms_stop.tms_cstime);
printf("Real time = %g seconds [%lu ticks]\n",
(real_stop - real_start) / (double)HZ, real_stop - real_start);
exit(n);
}
/* По сигналу SIGALRM - завершить процесс */
void onalarm(int nsig){
printf("Выход #%d ================\n", getpid());
bye(0);
}
/* Порожденный процесс */
void dochild(int n){
hello();
printf("Старт #%d ================\n", getpid());
signal(SIGALRM, onalarm);
/* Заказать сигнал SIGALRM через 1 + n*3 секунд */
alarm(1 + n*3);
for(;;){} /* зациклиться в user mode */
}
#define NCHLD 4
int main(int ac, char *av[]){
int i;
/* Узнать число тиков в секунде */
HZ = sysconf(_SC_CLK_TCK);
setbuf(stdout, NULL);
hello();
for(i=0; i < NCHLD; i++)
if(fork() == 0)
dochild(i);
while(wait(NULL) > 0);
printf("Выход MAIN =================\n");
bye(0);
return 0;
}
Сигналы.Процессы в UNIX используют много разных механизмов взаимодействия. Одним из них являются сигналы.
Сигналы - это асинхронные события. Что это значит? Сначала объясним, что такое синхронные события: я два раза в день подхожу к почтовому ящику и проверяю - нет ли в нем почты (событий). Во-первых, я произвожу опрос - "нет ли для меня события?", в программе это выглядело бы как вызов функции опроса и, может быть, ожидания события. Во-вторых, я знаю, что почта может ко мне прийти, поскольку я подписался на какие-то газеты. То есть я предварительно заказывал эти события.
Схема с синхронными событиями очень распространена. Кассир сидит у кассы и ожидает, пока к нему в окошечко не заглянет клиент. Поезд периодически проезжает мимо светофора и останавливается, если горит красный. Функция Си пассивно "спит" до тех пор, пока ее не вызовут; однако она всегда готова выполнить свою работу (обслужить клиента). Такое ожидающее заказа (события) действующее лицо называется сервер. После выполнения заказа сервер вновь переходит в состояние ожидания вызова. Итак, если событие ожидается в специальном месте и в определенные моменты времени (издается некий вызов для ОПРОСА) - это синхронные события. Канонический пример - функция gets, которая задержит выполнение программы, пока с клавиатуры не будет введена строка. Большинство ожиданий внутри системных вызовов - синхронны. Ядро ОС выступает для программ пользователей в роли сервера, выполняющего сисвызовы (хотя и не только в этой роли - ядро иногда предпринимает и активные действия: передача процессора другому процессу через определенное время (режим разделения времени), убивание процесса при ошибке, и.т.п.).
Сигналы - это асинхронные события. Они приходят неожиданно, в любой момент времени - вроде телефонного звонка. Кроме того, их не требуется заказывать - сигнал процессу может поступить совсем без повода. Аналогия из жизни такова: человек сидит и пишет письмо. Вдруг его окликают посреди фразы - он отвлекается, отвечает на вопрос, и вновь продолжает прерванное занятие. Человек не ожидал этого оклика (быть может, он готов к нему, но он не озирался по сторонам специально). Кроме того, сигнал мог поступить когда он писал 5-ое предложение, а мог - когда 34-ое. Момент времени, в который произойдет прерывание, не фиксирован.
Сигналы имеют номера, причем их количество ограничено - есть определенный список допустимых сигналов. Номера и мнемонические имена сигналов перечислены в includeфайле <signal.h> и имеют вид SIGнечто. Допустимы сигналы с номерами 1..NSIG-1, где NSIG определено в этом файле. При получении сигнала мы узнаем его номер, но не узнаем никакой иной информации: ни от кого поступил сигнал, ни что от нас хотят. Просто "звонит телефон". Чтобы получить дополнительную информацию, наш процесс должен взять ее из другого известного места; например - прочесть заказ из некоторого файла, об имени которого все наши программы заранее "договорились". Сигналы процессу могут поступать тремя путями:
От другого процесса, который явно посылает его нам вызовомkill(pid, sig);
где pid - идентификатор (номер) процесса-получателя, а sig - номер сигнала. Послать сигнал можно только родственному процессу - запущенному тем же пользователем.
От операционной системы. Система может посылать процессу ряд сигналов, сигнализирующих об ошибках, например при обращении программы по несуществующему адресу или при ошибочном номере системного вызова. Такие сигналы обычно прекращают наш процесс. От пользователя - с клавиатуры терминала можно нажимом некоторых клавиш послать сигналы SIGINT и SIGQUIT. Собственно, сигнал посылается драйвером терминала при получении им с клавиатуры определенных символов. Так можно прервать зациклившуюся или надоевшую программу.Процесс-получатель должен как-то отреагировать на сигнал. Программа может:
проигнорировать сигнал (не ответить на звонок); перехватить сигнал (снять трубку), выполнить какие-то действия, затем продолжить прерванное занятие; быть убитой сигналом (звонок был подкреплен броском гранаты в окно);В большинстве случаев сигнал по умолчанию убивает процесс-получатель. Однако процесс может изменить это умолчание и задать свою реакцию явно. Это делается вызовом signal:
#include <signal.h>
void (*signal(int sig, void (*react)() )) ();
Параметр react может иметь значение:
SIG_IGN
сигнал sig будет отныне игнорироваться. Некоторые сигналы (например SIGKILL) невозможно перехватить или проигнорировать.
SIG_DFL
восстановить реакцию по умолчанию (обычно - смерть получателя). имя_функции Например
void fr(gotsig){ ..... } /* обработчик */
... signal (sig, fr); ... /* задание реакции */
Тогда при получении сигнала sig будет вызвана функция fr, в которую в качестве аргумента системой будет передан номер сигнала, действительно вызвавшего ее gotsig==sig. Это полезно, т.к. можно задать одну и ту же функцию в качестве реакции для нескольких сигналов:
... signal (sig1, fr); signal(sig2, fr); ...
После возврата из функции fr() программа продолжится с прерванного места. Перед вызовом функции-обработчика реакция автоматически сбрасывается в реакцию по умолчанию SIG_DFL, а после выхода из обработчика снова восстанавливается в fr. Это значит, что во время работы функции-обработчика может прийти сигнал, который убьет программу.
Приведем список некоторых сигналов; полное описание посмотрите в документации. Колонки таблицы: G - может быть перехвачен; D - по умолчанию убивает процесс (k), игнорируется (i); C - образуется дамп памяти процесса: файл core, который затем может быть исследован отладчиком adb; F - реакция на сигнал сбрасывается; S - посылается обычно системой, а не явно.
сигнал G D C F S смысл
SIGTERM + k - + - завершить процесс
SIGKILL - k - + - убить процесс
SIGINT + k - + - прерывание с клавиш
SIGQUIT + k + + - прерывание с клавиш
SIGALRM + k - + + будильник
SIGILL + k + - + запрещенная команда
SIGBUS + k + + + обращение по неверному
SIGSEGV + k + + + адресу
SIGUSR1, USR2 + i - + - пользовательские
SIGCLD + i - + + смерть потомка
Сигнал SIGILL используется иногда для эмуляции команд с плавающей точкой, что происходит примерно так: при обнаружении "запрещенной" команды для отсутствующего процессора "плавающей" арифметики аппаратура дает прерывание и система посылает процессу сигнал SIGILL. По сигналу вызывается функция-эмулятор плавающей арифметики (подключаемая к выполняемому файлу автоматически), которая и обрабатывает требуемую команду. Это может происходить много раз, именно поэтому реакция на этот сигнал не сбрасывается. SIGALRM посылается в результате его заказа вызовом alarm() (см. ниже). Сигнал SIGCLD посылается процессу-родителю при выполнении процессом-потомком сисвызова exit (или при смерти вследствие получения сигнала). Обычно процессродитель при получении такого сигнала (если он его заказывал) реагирует, выполняя в обработчике сигнала вызов wait (см. ниже). По-умолчанию этот сигнал игнорируется. Реакция SIG_IGN не сбрасывается в SIG_DFL при приходе сигнала, т.е. сигнал игнорируется постоянно. Вызов signal возвращает старое значение реакции, которое может быть запомнено в переменную вида void (*f)(); а потом восстановлено. Синхронное ожидание (сисвызов) может иногда быть прервано асинхронным событием (сигналом), но об этом ниже. Деления просессаСистемный вызов fork() (вилка) создает новый процесс: копию процесса, издавшего вызов. Отличие этих процессов состоит только в возвращаемом fork-ом значении:
0 - в новом процессе.
pid нового процесса - в исходном.
Вызов fork может завершиться неудачей если таблица процессов переполнена. Простейший способ сделать это:
main(){
while(1)
if( ! fork()) pause();
}
Одно гнездо таблицы процессов зарезервировано - его может использовать только суперпользователь (в целях жизнеспособности системы: хотя бы для того, чтобы запустить программу, убивающую все эти процессы-варвары).
Пайпы и FIFO-файлы.Процессы могут обмениваться между собой информацией через файлы. Существуют файлы с необычным поведением - так называемые FIFO-файлы (first in, first out), ведущие себя подобно очереди. У них указатели чтения и записи разделены. Работа с таким файлом напоминает проталкивание шаров через трубу - с одного конца мы вталкиваем данные, с другого конца - вынимаем их. Операция чтения из пустой "трубы" проиостановит вызов read (и издавший его процесс) до тех пор, пока кто-нибудь не запишет в FIFOфайл какие-нибудь данные. Операция позиционирования указателя - lseek() - неприме- нима к FIFO-файлам. FIFO-файл создается системным вызовом
#include <sys/types.h>
#include <sys/stat.h>
mknod( имяФайла, S_IFIFO | 0666, 0 );
где 0666 - коды доступа к файлу. При помощи FIFO-файла могут общаться даже неродственные процессы.
Разновидностью FIFO-файла является безымянный FIFO-файл, предназначенный для обмена информацией между процессом-отцом и процессом-сыном. Такой файл - канал связи как раз и называется термином "труба" или pipe. Он создается вызовом pipe:
int conn[2]; pipe(conn);
Если бы файл-труба имел имя PIPEFILE, то вызов pipe можно было бы описать как
mknod("PIPEFILE", S_IFIFO | 0600, 0);
conn[0] = open("PIPEFILE", O_RDONLY);
conn[1] = open("PIPEFILE", O_WRONLY);
unlink("PIPEFILE");
При вызове fork каждому из двух процессов достанется в наследство пара дескрипторов:
pipe(conn);
fork();
conn[0]----<---- ----<-----conn[1]
FIFO
conn[1]---->---- ---->-----conn[0]
процесс A процесс B
Пусть процесс A будет посылать информацию в процесс B. Тогда процесс A сделает:
close(conn[0]);
// т.к. не собирается ничего читать
write(conn[1], ... );
а процесс B
close(conn[1]);
// т.к. не собирается ничего писать
read (conn[0], ... );
Получаем в итоге:
conn[1]---->----FIFO---->-----conn[0]
процесс A процесс B
Обычно поступают еще более элегантно, перенаправляя стандартный вывод A в канал conn[1]
dup2 (conn[1], 1); close(conn[1]);
write(1, ... ); /* или printf */
а стандартный ввод B - из канала conn[0]
dup2(conn[0], 0); close(conn[0]);
read(0, ... ); /* или gets */
Это соответствует конструкции
$ A | B
записанной на языке СиШелл.
Файл, выделяемый под pipe, имеет ограниченный размер (и поэтому обычно целиком оседает в буферах в памяти машины). Как только он заполнен целиком - процесс, пишущий в трубу вызовом write, приостанавливается до появления свободного места в трубе. Это может привести к возникновению тупиковой ситуации, если писать программу неаккуратно. Пусть процесс A является сыном процесса B, и пусть процесс B издает вызов wait, не закрыв канал conn[0]. Процесс же A очень много пишет в трубу conn[1]. Мы получаем ситуацию, когда оба процесса спят:
A потому что труба переполнена, а процесс B ничего из нее не читает, так как ждет окончания A;
B потому что процесс-сын A не окончился, а он не может окончиться пока не допишет свое сообщение.
Решением служит запрет процессу B делать вызов wait до тех пор, пока он не прочитает ВСЮ информацию из трубы (не получит EOF). Только сделав после этого close(conn[0]); процесс B имеет право сделать wait.
Если процесс B закроет свою сторону трубы close(conn[0]) прежде, чем процесс A закончит запись в нее, то при вызове write в процессе A, система пришлет процессу A сигнал SIGPIPE - "запись в канал, из которого никто не читает".
Нелокальный переход.Теперь поговорим про нелокальный переход. Стандартная функция setjmp позволяет установить в программе "контрольную точку"*, а функция longjmp осуществляет прыжок в эту точку, выполняя за один раз выход сразу из нескольких вызванных функций (если надо)*. Эти функции не являются системными вызовами, но поскольку они реализуются машинно-зависимым образом, а используются чаще всего как реакция на некоторый сигнал, речь о них идет в этом разделе. Вот как, например, выглядит рестарт программы по прерыванию с клавиатуры:
#include <signal.h>
#include <setjmp.h>
jmp_buf jmp; /* контрольная точка */
/* прыгнуть в контрольную точку */
void onintr(nsig){ longjmp(jmp, nsig); }
main(){
int n;
n = setjmp(jmp); /* установить контрольную точку */
if( n ) printf( "Рестарт после сигнала %d\n", n);
signal (SIGINT, onintr); /* реакция на сигнал */
printf("Начали\n");
...
}
setjmp возвращает 0 при запоминании контрольной точки. При прыжке в контрольную точку при помощи longjmp, мы оказываемся снова в функции setjmp, и эта функция возвращает нам значение второго аргумента longjmp, в этом примере - nsig.
Прыжок в контрольную точку очень удобно использовать в алгоритмах перебора с возвратом (backtracking): либо - если ответ найден - прыжок на печать ответа, либо если ветвь перебора зашла в тупик - прыжок в точку ветвления и выбор другой альтернативы. При этом можно делать прыжки и в рекурсивных вызовах одной и той же функции: с более высокого уровня рекурсии в вызов более низкого уровня (в этом случае jmp_buf лучше делать автоматической переменной - своей для каждого уровня вызова функции).
Разделяемая памятьshmget создает новый сегмент разделяемой памяти или находит существующий сегмент с тем же ключом shmat подключает сегмент с указанным дескриптором к виртуальной памяти обращающегося процесса shmdt отключает от виртуальной памяти ранее подключенный к ней сегмент с указанным виртуальным адресом начала shmctl служит для управления параметрами, связанными с существующим сегментом После подключения сегмента разделяемой памяти к виртуальной памяти процесса, он может обращаться к соответствующим элементам памяти с использованием обычных машинных команд чтения и записи
shmid = shmget(key, size, flag);
size определяет желаемый размер сегмента в байтах если в таблице разделяемой памяти находится элемент, содержащий заданный ключ, и права доступа не противоречат текущим характеристикам процесса, то значением системного вызова является дескриптор существующего сегмента реальный размер сегмента можно узнать с помощью системного вызова shmctl иначе создается новый сегмент с размером не меньше установленного в системе минимального размера сегмента разделяемой памяти и не больше установленного максимального размера создание сегмента не означает немедленного выделения под него основной памяти откладывается до выполнения первого системного вызова подключения сегмента к виртуальной памяти некоторого процесса при выполнении последнего системного вызова отключения сегмента от виртуальной памяти соответствующая основная память освобождаетсяvirtaddr = shmat(id, addr, flags);
id - это ранее полученный дескриптор сегмента addr - желаемый процессом виртуальный адрес, который должен соответствовать началу сегмента в виртуальной памяти virtaddr - реальный виртуальный адрес начала сегмента не обязательно совпадает со значением прямого параметра addr если addr == 0, ядро выбирает наиболее удобный виртуальный адрес начала сегментаshmdt(addr);
addr - виртуальный адрес начала сегмента в виртуальной памяти, ранее полученный от системного вызова shmatshmctl(id, cmd, shsstatbuf);
cmd идентифицирует требуемое конкретное действие важна функция уничтожения сегмента разделяемой памяти СемафорыОбобщение классического механизма семафоров общего вида Диекстры
Целесообразность обобщения сомнительна
Обычно использовался облегченный вариант двоичных семафоров
Известен алгоритм реализации семафоров общего вида на основе двоичных
Семафор в ОС UNIX:
значение семафора идентификатор процесса, который хронологически последним работал с семафором число процессов, ожидающих увеличения значения семафора число процессов, ожидающих нулевого значения семафораТри системных вызова:
semget для создания и получения доступа к набору семафоров semop для манипулирования значениями семафоров semctl для выполнения управляющих операций над набором семафоровid = semget(key, count, flag);
key, flag и id - обычный смысл count - число семафоров в наборе семафоров, обладающих одним и тем же ключом индивидуальный семафор идентифицируется дескриптором набора семафоров и номером семафора в наборе если набор семафоров с указанным ключом уже существует, то число семафоров в группе можно узнать с помощью системного вызова semctloldval = semop(id, oplist, count);
id - дескриптор группы семафоров oplist - массив описателей операций над семафорами группы count - размер этого массива возвращается значение последнего обработанного семафораЭлемент массива oplist:
номер семафора в указанном наборе семафоров операция флагиЕсли проверка прав доступа проходит нормально
указанные в массиве oplist номера семафоров не выходят за пределы общего размера набора семафоров для каждого элемента массива oplist значение семафора изменяется в соответствии со значением поля "операция"Значение поля операции положительно
значение семафора увеличивается на единицу все процессы, ожидающие увеличения значения семафора, активизируются (пробуждаются)Значение поля операции равно нулю
если значение семафора равно нулю, выбирается следующий элемент массива oplist иначе число процессов, ожидающих нулевого значения семафора, увеличивается на единицу обратившийся процесс переводится в состояние ожидания (усыпляется)Значение поля операции отрицательно
(1) его абсолютное значение меньше или равно значению семафора
это отрицательное значение прибавляется к значению семафора если значение семафора стало нулевым, то ядро активизирует все процессы, ожидающие нулевого значения этого семафора(2) значение семафора меньше абсолютной величины поля операции
число процессов, ожидающих увеличения значения семафора увеличивается на единицу текущий процесс откладываетсяСтремление добиться возможности избегать тупиковых ситуаций
Системный вызов semop выполняется как атомарная операция
Флаг IPC_NOWAIT заставляет ядро ОС UNIX не блокировать текущий процесс
лишь сообщать в ответных параметрах о возникновении ситуации, приведшей бы к блокированию процессаsemctl(id, number, cmd, arg);
id - это дескриптор группы семафоров number - номер семафора в группе cmd - код операции arg - указатель на структуру, содержимое которой интерпретируется в зависимости от операцииМожно уничтожить индивидуальный семафор в указанной группе
Очереди сообщенийЧетыре системных вызова:
msgget для образования новой очереди сообщений или получения дескриптора существующей очереди msgsnd для посылки сообщения (его постановки в очередь сообщений) msgrcv для приема сообщения (выборки сообщения из очереди) msgctl для выполнения управляющих действийmsgqid = msgget(key, flag);
Сообщения хранятся в виде связного списка
Декскриптор очереди сообщений - индекс в массиве заголовков очередей сообщений
В заголовке очереди хранятся:
указатели на первое и последнее сообщение в данной очереди число сообщений общий размер в байтах сообщений, находящихся в очереди идентификаторы процессов, которые последними послали или приняли сообщение через данную очередь временные метки последних выполненных операций msgsnd, msgrsv и msgctlmsgsnd(msgqid, msg, count, flag);
msg - это указатель на структуру, содержащую целочисленный тип сообщения и символьный массив· count - задает размер сообщения в байтах
flag определяет действия ядра при выходе за пределы допустимых размеров внутренней буферной памятиУсловия успешной постановки сообщения в очередь:
процесс должен иметь право на запись в очередь длина сообщения не должна превосходить верхний предел общая длина сообщений не должна превосходить установленного предела тип сообщения должен быть положительным целым числомПроцесс продолжает свое выполнение
Ядро активизирует (пробуждает) все процессы, ожидающие поступления сообщений из очереди
Превышается верхний предел суммарной длины сообщений
обратившийся процесс откладывается до разгрузки очереди но есть флаг IPC_NOWAIT (как для семафоров)count = msgrcv(id, msg, maxcount, type, flag);
msg - указатель на структуру данных в адресном пространстве пользователя для размещения принятого сообщения maxcount - размер области данных (массива байтов) в структуре msg type специфицирует тип сообщения, которое желательно принять flag указывает ядру, что следует предпринять, если в указанной очереди сообщений отсутствует сообщение с указанным типом count - реальное число байтов, переданных пользователюЗначением параметра type является нуль
выбирается первое сообщение копируется в заданную пользовательскую структуру данных процессы, отложенные по причине переполнения очереди сообщений, активизируются если значение параметра maxcount оказывается меньше реального размера сообщения, ядро не удаляет сообщение из очереди и возвращает код ошибки если задан флаг MSG_NOERROR, то выборка сообщения производится, и в буфер пользователя переписываются первые maxcount байтов сообщенияЗначение type есть положительное целое число
выбирается первое сообщение с таким же типомЗначение type есть отрицательное целое число
выбирается первое сообщение, значение типа которого меньше или равно абсолютному значению typeВ очереди отсутствуют сообщения, соответствующие спецификации type
процесс откладывается до появления в очереди требуемого сообщения но есть флаг IPC_NOWAITmsgctl(id, cmd, mstatbuf);
опрос состояния описателя очереди сообщений изменение его состояния уничтожение очереди сообщений4.1 Старт системы
4.2 run levels
4.3 Остановка системы
4.4 Конфигурирование ядра системы
4.5 Инсталирование периферии на примере ленточного накопителя.
4.6 Инсталирование софта
4.7 Управление процессами
7. Старт системы.В самом начале, после включения питания выполяется последовательность команд записанная в Boot ROM машины. Boot ROM выполняет общую диагностику и проводит инициализацию устройств необходимую для дальнейшей загрузки операционной системы. В задачи Boot ROM кода входит:
· Определение типа процессора
· Инициализация и тест таймеров
· Нахождение и инициализация видео консоли
· Загрузка конфигурации с EEPROM
· Инициализации системы ввода-вывода включая пользовательский интерфейс и аудио
· Распечатка на консоли copyright и других баннеров, типа процессора EEPROM статуса, количества памяти
· Тестирование памяти и распечатка общего количества памяти и найденных в результате теста ошибок
· Тест и инициализация системы прямого доступа к памяти (DMA)
· Поиск и распечатка информации о встроенных интерфейсных платах
· Тест и инициализация SCSI интерфеса и интерфейса локольной сети
· Предложение о выборе вариантов загрузки
При этом возможен вариант запгрузки как с SCSI устройства (диск, CDROM, лента, …) так и через локальную сеть. Загрузочный диск должен быть предварительно сконфигурирован. Так как обьем Boot ROM не может быть большим, в его задачи входит загрузка вторичного загрузчика операционной системы. Для этого загрузочный диск должен быть инициализирован определенным образом. Помимо стандартной файловой системы он еще должен содержать так называемы LIF (Logical Interchange Fomat) раздел в котором записан вторичный загрузчик и ряд необходимых утилит. Посмотреть состав LIF блока можно с помощью команды lifls принимающей в качестве аргумента имя блочного устройства диска:
lifls /dev/dsk/c0t5d0
ISL AUTO HPUX LABEL
Для создания LIF области используется команда lifinit (инициализируються только диски которые не являются подмонтированными файловыми системами). Для записи в или копирования из LIF области используется утилита lifcp .Например, команда:
lifcp /dev/dsk/c0t5d0:ISL a
копирует файл ISL из LIF области в файл с именем а. Во время инсталяции LIF область создается автоматически и необходимости работы с ней практически не появляется, за исключением случаев сбоев.
После завершения всех тестов и выполнения поиска возможных устройств загрузки в и в случае если параметр SECURE записанный в EEPROM равен OFF возможен вход в меню загрузки boot ROM при нажатии на клавишу ESC. Если SECURE=OFF и процесс загрузки не прерывался нажатием ESC а также EEPROM параметр AUTOBOOT=ON, boot ROM попытается загрузить из LIF области вторичный загрузчик ISL. Устройство загрузки при этом выбирается из EEPROM параметра PRIMARY BOOT PATH. В случае неудачной загрузки, boot ROM будет грузить ISL из устройства имя которого записано в EEPROM параметре ALTERNATE BOOT PATH. Если не удается загрузиться и от туда, система выйдет в boot ROM меню. Для поиска всех возможных устройств загрузки boot ROM имеет команду SEARCH. Для загрузки с какогото конкретного устройства найденого командой SEARCH используется команда BOOT:
boot [device_path] [isl]
запущеная без аргументов она приводит к загрузке системы из устройства адрес которого содержится в PRIMARY BOOT PATH. Если указан аргумент isl то система загрузит вторичный загрузчик ISL в интерактивный режим. Основные случаи когда необходима загрузка не с основного устройства перечислены ниже:
· На основном диске нет загрузочного ядра
· LIF область диска повреждена
· Корневая файловая система ОЧЕНЬ сильно запорчена
Примечание: В том случае если SECURE=ON (безопасный режим) нет никакой возможности попасть в boot ROM меню за исключением как физически отключить устройства первичной и вторичной загрузки.
Если был выбран интерактивный режим загрузки ISL то последний после загрузки, не станет автоматически загружать ядро системы а перейдет в диалоговый режим. В этом режиме есть ряд команд влияющих на загрузку системы. Например по команде 700SUPPORT возможна загрузка с CDROM специальной версии ядра системы предназначеной для восстановления системы в том случае если ядро основной системы не загружается. Список утилит которые доступны для запуска ISL можно увидеть по команде LS. Основная утилита – HPUX, предназначенная для загрузки ядра системы. Для того чтоб посмоьреть содержимое директории /stand на устройстве загрузки по умолчанию нужно воспользоваться командой:
ISL> HPUX ll disk (;0) /stand/
При загрузке ядра возможно указание файла ядра отличного от того что используется по умолчанию (/stand/vmunix) для загрузки а также запустить ядро с определенными параметрами. Например команда:
ISL> hpux /stand/vmunix.prev
загружает ядро с именем /stand/vmunix.prev (эту команду используют в тех случаях когда вновь собранное ядро не хочет по какимто причинам запускаться и нужно загрузить старое ядро).
А команда:
ISL> hpux –is /stand/vmunix
загружает ядро с именем /stand/vmunix в однопользовательский режим. Ситуации прикоторых необходима загрузка в однопользовательский режим:
· забыт пароль администратора и его нужно изменить
· поврежден файл /etc/inittab
· какой то из загрузочных скриптов по каким то причинам зависает
Сразу же после получения управления ядро системы выполняет две задачи:
· Находит и монтирует корневую файловую систему
· Запускает процесс init и если ядру не было указано дополнительных аргументов относительно run-level то init переводит систему на default run-level (обычно это многопорльзовательский режим работы)
8. Run-levels.После успешного монтирования корневой файловой системы ядро запускает процесс init. Отличительной особенностью этого процесса является то что его создает непосредственно ядро,он имеет PID=1 и не имеет родительского процесса, в отличии от остальных процессов получающихся в следствие системного вызова fork(). Конфигурациооный файл программы init называется /etc/inittab. Приведем его формат:
Id:run-levels:action:process
где
id От одно до четырехбуквенный индекс который идентифицирует
строку файла inittab.
run-level определяет run-level.в одной строке может быть несколько run-levels.
run-levels определяются как цифры от 0 до 6. Когда boot init пытается измнить run-level, все процессы которые не имеют run-level поля равному изменяемому run-level получают предупреждающий сигнал (SIGTERM) и те которые не завершили работу по истечению 20-ти секундного интервала получат сигнал (SIGKILL).Если run level не определен, то это подразумевает все run levels, с 0 до 6.
Это поле также может принимать три других значения “a”, “b” и “c”.
Строки имеющие эти значения в поле run-level выполняются только
когда пользовательский init процесс запрашивает их. (независимо от
текущего run level системы).
Они в корне отличается от run levels в которые boot init никогда не
входит a, b, or c. Также выполнение процессов из этих run-levels
никогда не меняет текущий run level системы.
Более того, процессы запущенные с rul-level a, b, или c не терминируются когда boot init изменяет run-level системы. Процессы терминируются лишь когда соответствующая строка inittab помечена как off в поле action или полностью удалена из inittab или система загружается в однопользовательский режим.
action определяет действия этой строки файла, которые могут принимать следующие значения:
boot выполнять процесс только во время чтения inittab исключительно при загрузке системы. Boot init стартует процесс не дожидаясь его окончания и по его завершении не рестартует его заново.
bootwait выполнять процесс только во время чтения inittab исключительно при загрузке системы. Boot init стартует процесс дожидается его окончания и по его завершении не рестартует его заново.
initdefault процесс выполняется только во время начальной
загрузки. Boot init использует эту строку если она существует для того чтобы определить в какой run-level входить в самом начале. Если в этой строке указано несколько run-levels то запускается с наибольшим номером. Если run-level не указан то стартует по умолчанию run-level c номером 6. Если строка initdefaul не найдена в /etc/inittab то при старте системы будет запрошено на какой run-level запускать систему.
off если процесс асоцированный с этой строкой в данный момент запущен то послать ему предупреждающий сигнал (SIGTERM) и подождать 20 секунд его завершения, после чего принудительно завершить его сигналом SIGKILL. Если процесс не запущен – игнорировать эту строку.
once Когда boot init стартует run level который совпадает с указанным в этой строке он не дожидается его окончания и после окончания не запускает его вновь. Если boot init запускает новый run level но процесс все еще в запущеном состоянии от предыдущего run-level то процесс не перестартовывается.
ondemand Эта инструкция есть синоним инструкции respawn за исключением того что она используется только с “a”, “b”, или “c” значениями run-level.
powerfail Запустить процесс асоциированный с этой строкой только в том случае если boot init получит сигнал power-fail signal (SIGPWR).
powerwait Запустить процесс асоциированный с этой строкой
только в случае если boot init получит power-fail signal (SIGPWR) и ждать пока процесс завершит работу перед запуском любых других процессов из inittab.
respawn Если процесс не запущен, то запустить его не дожидаясь окончания (прподолжив сканирование inittab). После завершения процесса запустить его заново. Если процесс запущен – то ничего не делать продолжив сканирование inittab.
sysinit процессы содержащиеся в строках этого типа будут запускаться перед тем как boot init попытается получить доступ к системной консоли. Это подразумевает что процессы будут запускаться только для инициализации устройств на которых boot init может получать run level информацию. Boot init ожидает завершение процессов запущенных с этим параметром.
wait Когда boot init запускает run-level с этим параметром, он ждет завершения процесса. Любые сканирования файла inittab пока boot init находится на томже run level являються причиной игнорирования этой строки в файле inittab.
process это шелл скрипт который запускается из шела созданного системным вызовом fork() как "sh -c 'exec command'.
Запуск init может сопровождаться следующими аргументами:
/sbin/init [0|1|2|3|4|5|6|S|s|Q|q|a|b|c]
агрументы означают следующее:
0-6 перевод системы на уровень от 0 до 6
a|b|c выполнение действий из файла из строк inittab eкоторые помечены как
специальный run-level a, b, или c без изменения значения текущего run-level.
Q|q реинициализация файла inittab без изменения значения текущего run-level
S|s перевод системы в однопользовательский режим, при этом логическая
системная консоль /dev/syscon изменяется на тот терминал с которого была
запущена команда.
Остановка системыДля остановки системы Вы должны иметь права администратора (пользователь с UID=0). Различают два вида остановки системы, первый это перевод системы в однопользовательский режим, при котором все пользовательские и системные процессы работающие в многопользовательском режиме завершаются, и доступ к машине остается лишь через логическую системную консоль (тот терминал с которого была запущена команда). Такой режим часто бывает необходим во время бэкапа или восстановления данных, при установке нового оборудования или програмного обеспечения. После этого для возврата назад в многопользовательский режим нужно воспользоваться командой init. Второй вид остановки системы – это полная остановка системы с последующим выключением питания. Остановка системы может быть произведена как с применением команд hpux, так и с использованием SAM. При использовании SAM в разделе Routine Tasks выбрать пункт System shutdown а затем тип шатдауна:
· Halt system - полная остановка системы
· Reboot - перезагрузка системы
· Go to single user state - перевод системы в однопользовательский режим
При использовании hpux комманд необходимо выполнить переход в корневой каталог (т.к. нельзя размонтировать файловые системы которые используются просцессами), а затем выполнить команду shutdown с одним из параметров:
· cd /
· shutdown –h now - немедленная остановка системы
· shutdown –r now - немедленная перезагрузка системы
· shutdown - немедленный перевод системы в
однопользовательский режим
· shutdown –h 300 - остановка системы через пять минут.
При этом раз в всем залогиненым пользователям
будет посылаться уведомление о предстоящей
остановке системы.
Команда shutdown переключает логическую системную консоль /dev/syscon изменяется на тот терминал с которого была запущена команда. shutdown использует программу /usr/sbin/wall для посылки сообщения о остановке или перезагрузки системы на все терминалы на которых есть асктивные пользователи. По умолчанию лишь администратор системы обладает правами на остановку системы, однако существует файл /etc/shutdown.allow который позволяет выполнять остановку системы (но не перевод в однопользовательский режим) пользователям не имеющих администраторских прав. В этом файле указывается имя пользователя и имя системы (для случая кластеров) которую пользователь может остановить. Симвод # исполдьзуется для комментариев, символ + обозначает любое имя. Например:
# пользователь user1 может останавливать систему systemA и systemB
systemA user1
systemB user1
# администратор может останавливать все системы
+ root
# любой пользователь может остановить систему systemC
systemC +
Отсутствие файла /etc/shutdown.allow или отсутствие в нем администратора (root) не может помешать администратору остановить систему.
После запуска, shutdown выполняет:
· сброс на диск всех суперблоков файловых систем находящихся в памяти
· установку real UID в 0
· широковещательную посылку сообщения всем пользователям
· запуск /sbin/rc для выполнения корректного завершения всех основных системных и пользовательских программ
· выполнение пргораммы reboot для реальной остановки или перезагрузки системы.
Так же как и при старте, во время остановки системы используется скрипт /etc/rc . Если стартовый скрипт линк (например /sbin/rcN.d/S123test) в последовательности N имеет стоп действие, соответствующий остановочный скрипт должен быть помещен в последовательность
N-1 (/sbin/rcN-1.d/K200test). Действия запущенные на уровне N должны быть остановлены на уровне N-1. Поэтому остановка системы (т.е., переход с уровня 3 напрямую в уровень 0) приведет к корректному завершению всех подсистем путем вызова соответствующих остановочных скриптов.
Помомо команды shutdown существует команда rebooot которая выполняет похожие действия. Например reboot –h вызывает остановку системы а reboot без параметров перезагрузку. Между командами reboot и shutdown есть принципиальная разница. reboot всем процессам в системе (кроме самой себя J) посылает 9-й сигнал, который процесс не может перехватить или обработать и после этого вызывает остановку или перезагрузку системы. Поэтому не рекомендуется использовать эту команду в системах где есть критически важные приложения (например сервера баз данных) которые требуют корректной остановки.
Конфигурирование ядра системы
Для большинства систем вполне хватает стандартной конфигурации ядра, однако в ряде случаев оговоренных ниже возникает необходимость переконфигурирования ядра. К этим случаям можно отнести:
· Добавление или удаление периферии (драйверов устройств) а также псевдодрайверов. В случае удаления периферии удалять драйвер устройства из ядра совсем не обязательно, но крайне желательно, т.к. в этом случае ядро будет меньше по обьему и будет работать более эффектино. Прежде чем удалять драйвер устройства убедитесь не зависят ли от него драйвера других устройств проверив файлы в директории /usr/conf/master.d в таблицах зависимости в секции DRIVER_DEPENDENCY. Особое внимание следует обратить на файл core-hpux.
· Изменение системных параметров (tunable parameters). В тех случаях когда система работает с большим количеством пользователей часто возникает необходимость изменения стандартных системных параметров. Эти параметры определяются в секции TUNABLE в файлах /usr/conf/master.d. Большинство из них находится в файле core-hpux.
· Инсталирование специализированного програмного обеспечения HP (подсистем). Если вы добавляете в систему специализированное програмное обеспечение например поддержку LAN, ATM, FDDI и.т.п в этом случае также требуется модификация ядра.
· Добавление файловых систем отлдичных от HFS.
· Добавление, удаление или модификация swap и (или) dump областей, устройства консоли или корневой файловой системы.
Драйвера по своим возможностям а также по методу доступа и управлению ими можно разделить на три основных типа:
· Символьные драйвера. Работа с этими драйверами происходит в побайтном режиме без использования буферного кэша. К таким драйверам можно отнести драйвера таких устройств как драйвера последовательных портов, терминалов, магнитных лент …
· Блочные драйвера. Этот тип драйверов позволяет проводить обмен блоками данных. Так например обмен с диском происходит фиксироваными блоками (секторами), даже в том случае если идет операция с данными количество которых меньше размера блока всеравно физически будет прочитан или записан один блок. При работе эти драйвера используют системный буферный кэш.
· Драйвера низкого уровня (raw drivers) Этот тип драйверов производит обмен с блочными устройствами напрямую минуя буферный кэш с ситемы.
Кроме драйверов устройств существует множество других драйверов не имеющих непосредственного отношения к периферии компьютера. Такие драйвера называются псевдодрайверами. Вот примеры некоторых из них:
/dev/kmem обеспечивает доступ к физической памяти компьютера
/dev/mem обеспечивает доступ к виртуальной памяти ядра
/dev/null нулевое устройство. Призаписи в него данные удаляются, а при чтении считывается 0 байт
lvm (Logical Volume Manager) обеспечивает построение и доступ к логическим дискам
Драйвера адресуются старшим номером устройства (major number). Помимо него также существует младший номер (minor number) для адресации одного из клонов драйвера. Например в случае с драйвером диска младший номер может означать номер диска.
$ ls -l /dev/dsk/
total 0
brw-r--r-- 1 root sys 31 0x002000 Jun 10 1996 c0t2d0
brw-r--r-- 1 root sys 31 0x005000 Jun 10 1996 c0t5d0
brw-r--r-- 1 root sys 31 0x006000 Jun 10 1996 c0t6d0
$ ls -l /dev/rdsk/
total 0
crw-r----- 1 root sys 188 0x002000 Jun 10 1996 c0t2d0
crw-r----- 1 root sys 188 0x005000 Jan 3 16:47 c0t5d0
crw-r----- 1 root sys 188 0x006000 Jun 10 1996 c0t6d0
Первая команда выводит файлы блочных дисковых устройств, вторая файлы raw дисковых устройств. Как создаются файлы устройств будет показано чуть позже. Доступ к драйверу осуществляется через специальную структуру данных называемою коммутатором устройств каждый элемент которой содержит указатели на соответствующие функции драйвера (d_open(), d_close(), d_strategy(), d_read(), d_write(), d_ioctl, d_xpoll(), d_intr(), …), так называемые точки входа. Старший номер является указателем на элемент коммутатора устройств. Блочные и символьные устройства имеют свои собственные коммутаторы. Список драйверов можно посмотреть воспользовавшись программой lsdev.
9. Изменение системных параметровК одним из основных системных параметров относится параметр MAXUSERS который является макросом на основании которого вычисляются множество других параметров (например nproc вычисляется как 20+8*MAXUSERS). Этот параметр не указывает, как может показаться на первый взгляд на максимальное число пользователей в системе. На системах с небольшим количеством пользователей (рабочие станции) он обычно равен 32, на больших системах (T500) его значение может превышать 200. Перечислим краткий список основных системных параметров:
| Параметр | Значение по умолчанию | Описание |
| dbc_max_pct | 50 | Максимальный размер буферного кэша в процентах от обьема RAM |
| maxdsiz | 67108864 | Максимальный размер сегмента данных |
| maxssiz | 8388608 | Максимальный размер стека |
| maxtsiz | 67108864 | Максимальный размер сегмента кода |
| maxfiles | 60 | Максимальное количество открытых файлов на процесс |
| maxuprc | 75 | Максимальное число процессов пользователя |
| maxusers | 32 | Макрос через который определяются большинство других параметров |
| nfile | 2172 | Максимальное число открытых файлов в системе |
| nflock | 200 | Максимальное количество заблокированных файлов |
| npty | 60 | Максимальное количество псевдотерминалов в системе |
| semmns | 128 | Максимальное количество семафоров |
| shmmax | 67108864 | Максимальный обьем разделяемой памяти |
| shmmni | 200 | Максимальное количество идентификаторов разделяемой памяти |
| shmseg | 120 | Максимальное количество сегментов разделяемой памяти на процесс |
Для изменения системных параметров можно воспользоваться утилитой SAM либо выполнить изменения конфигурационных файлов и пересобрать ядро вручную. При использовании SAM после запуска sam необходимо:
· Открыть меню “SAM Kernel Configuration”
· Выбрать “Configurable parameters”
· Выбрать нужный параметр из списка
· Активировать пункт меню “Actions->Modify Configurable Parameter”
· Ввести новое значения параметра
После выхода из раздела “Configurable parameters” SAM предложит создать новое ядро и перезагрузить систему.
Конфигурирование ядра с использованием команд HP-UX.
Для этого необходимо выполнить следующую последовательность действий:
· cd /stand/buil
· /usr/lbin/sysadm/system_prep –v –s system
Этот скрипт сосздает файл system являющийся шаблоном конфигурационного файла ядра
· vi system
Редактируем файл ядра
· mk_kernel –s system
Компилируем ядро. Новое ядро будет содержаться в файле /stand/build/vmunix_test
· mv /stand/vmunix /stand/vmunix.prev
mv /stand/system /stand/system.prev
Создаем резервные копии старого ядра и конфигурационного файла
· mv /stand/build/vmunix_test /stand/vmunix
mv /stand/build/system /stand
Перемещаем ядро в директорию из которой идет загрузка
· shutdown –r now
выполняем перезагрузку системы
Инсталирование периферии
Файлы устройств
Обычно файлы устройств располагаются в каталоге /dev и cуществует специальное соглашение по поводу их имен. Имена файлов устройств как правило маркируются в соответствии со следующим соглашением: c#t#d#[s#] :
c# представляет класс интерфейса или интерфейсной карты.
t# адрес устройства на шине. Обычно он выставляется физически
переключателями расположеными на устройстве.
d# номер устройства. (для SCSI устройств это логический номер устройства LUN)
s# необязательный параметр показывающий номер секции устройства. Например для дисков он показывает номер портиции, 0 – указывает на целый диск.
Утилиты lssf и ioscan могут помочь в определении интерфейса к которому подключено то или иное устройство. Например:
bash-2.04$ lssf /dev/dsk/c0t6d0
sdisk card instance 0 SCSI target 6 SCSI LUN 0 section 0 at address 2/0/1.6.0 /dev/dsk/c0t6d0
bash-2.04$ lssf /dev/null
pseudo driver mm minor 0x000002 /dev/null
Системная конфигурация
Утилита ioscan является одной из наиболее полезных утилит для просмотра системной информации. Ее можно использовать для построения аппаратного адреса устройства. В простейшем виде ioscan показывает аппартный путь (адрес), класс устройства и описание. Опции –u (используемые устройства) или –k (структуры ядра) дают быстрый результат без сканирования оборудования.
# /usr/sbin/ioscan
H/W Path Class Description
=============================================
bc
1 graphics Graphics
2 ba Core I/O Adapter
2/0/1 ext_bus Built-in SCSI
2/0/1.2 target
2/0/1.2.0 disk TOSHIBA CD-ROM XM-5401TA
2/0/1.5 target
2/0/1.5.0 disk SEAGATE ST32151N
2/0/1.6 target
2/0/1.6.0 disk SEAGATE ST32151N
2/0/1.7 target
2/0/1.7.0 ctl Initiator
2/0/2 lan Built-in LAN
2/0/4 tty Built-in RS-232C
2/0/6 ext_bus Built-in Parallel Interface
2/0/8 audio Built-in Audio
2/0/10 pc Built-in Floppy Drive
2/0/11 ps2 Built-in Keyboard
4 ba EISA Adapter
5 ba Core I/O Adapter
5/0/1 hil Built-in HIL
5/0/2 tty Built-in RS-232C
8 processor Processor
9 memory Memory
#
Использование ключа –f приводит к выдаче полной информации включая номер интерфейса или интерфейсной карты.
Class I H/W Path Driver S/W State H/W Type Description
================================================================
bc 0 root CLAIMED BUS_NEXUS
graphics 0 1 graph3 CLAIMED INTERFACE Graphics
ba 0 2 bus_adapter CLAIMED BUS_NEXUS Core I/O Adapter
ext_bus 0 2/0/1 c720 CLAIMED INTERFACE Built-in SCSI
target 0 2/0/1.2 tgt CLAIMED DEVICE
disk 0 2/0/1.2.0 sdisk CLAIMED DEVICE TOSHIBA CD-ROM XM-5401TA
target 1 2/0/1.5 tgt CLAIMED DEVICE
disk 1 2/0/1.5.0 sdisk CLAIMED DEVICE SEAGATE ST32151N
target 2 2/0/1.6 tgt CLAIMED DEVICE
disk 2 2/0/1.6.0 sdisk CLAIMED DEVICE SEAGATE ST32151N
target 3 2/0/1.7 tgt CLAIMED DEVICE
ctl 0 2/0/1.7.0 sctl CLAIMED DEVICE Initiator
lan 0 2/0/2 lan2 CLAIMED INTERFACE Built-in LAN
tty 0 2/0/4 asio0 CLAIMED INTERFACE Built-in RS-232C
ext_bus 1 2/0/6 CentIf CLAIMED INTERFACE Built-in Parallel Interface
audio 0 2/0/8 audio CLAIMED INTERFACE Built-in Audio
pc 0 2/0/10 fdc CLAIMED INTERFACE Built-in Floppy Drive
ps2 0 2/0/11 ps2 CLAIMED INTERFACE Built-in Keyboard
ba 2 4 eisa CLAIMED BUS_NEXUS EISA Adapter
ba 1 5 bus_adapter CLAIMED BUS_NEXUS Core I/O Adapter
hil 0 5/0/1 hil CLAIMED INTERFACE Built-in HIL
tty 1 5/0/2 asio0 CLAIMED INTERFACE Built-in RS-232C
processor 0 8 processor CLAIMED PROCESSOR Processor
memory 0 9 memory CLAIMED MEMORY Memory
Использование ключа –n приводит к тому что ioscan дополнительно выдает информацию о файле устройства:
target 0 2/0/1.2 tgt CLAIMED DEVICE
disk 0 2/0/1.2.0 sdisk CLAIMED DEVICE TOSHIBA CD-ROM XM-5401TA
/dev/dsk/c0t2d0 /dev/rdsk/c0t2d0
target 1 2/0/1.5 tgt CLAIMED DEVICE
disk 1 2/0/1.5.0 sdisk CLAIMED DEVICE SEAGATE ST32151N
/dev/dsk/c0t5d0 /dev/rdsk/c0t5d0
В том случае когда драйвер устройства не может быть автоматически сконфигурирован и соответствующий файл устройства оказывается несозданным приходится создавать его вручную с помощью команд mkfs или mknod. Ядро взаимодействует с аппаратным обеспечением ассоциируя имя драйвера и аппаратный адрес. Стандартный интерфейс HP-UX к драйверам поставляется вместе с библиотекой /usr/conf/lib/libhp-ux.a. Ядро распознает интерфейсные драйвера и драйвера устройств через младшие и старшие нгомера “прошитые“ в файлах устройств.
Старший номер (major number)
Старший номер, как уже было сказано раньше является индексом в таблице переключателя устройств ядра. Для нахождения правильного старшего номера можно воспользоваться программой lsdev. Она считывает заголовки и список драйверов сконфигурированных в ядре с ихними блочными и символьными старшими номерами. Номера выводятся в десятичной форме, -1 означает либо то что устройство является модулем, драйвер несконфигурирован либо драйвер не поддерживает какогото из режимов (блочного или символьного).
Младший номер (minor number)
Младший номер определяет собой: расположение устройства и его драйвер-зависимые характеристики. Некоторые примеры младших номеров файлов устройств приведено ниже. Более полную информацию можно почерпнуть из руководства “Configuring HP-UX for Peripherals”.
SCSI Disk device. Рассмотрим что означает младший номер 0x023000 у SCSI устройства.
| bits | 8-11 | 12-15 | 16-19 | 20-23 | 24-27 | 28-31 |
| Binary | 0000 | 0010 | 0011 | 0000 | 0000 | 0000 |
| hex | 0 | 2 | 3 | 0 | 0 | 0 |
0000 0010 Первые восемь бит идентифицируют интерфейс или интерфейсную карту
0011 SCSI адрес диска
оставшиеся биты нулевые.
SCSI ленточный накопитель.
|
| Bits 16-19 | 20-23 | 24-27 | 28-31 |
| Binary | SCSI номер | SCSI LUN | 24 – поведение как у BSD систем при закрытии 25 – без перемотки 26 – конфигурационный метод (если 1 то биты от 27 до 31 означают индекс, если 0 то плотность записи) 27-31 Индекс/плотность записи | |
Создавать файлы устройств можно с помощью команды mknod. Она имеет следующий синтаксис:
mknod file_name [c|b] major minor
например
mknod /dev/null c 3 0x000002
Похожие работы
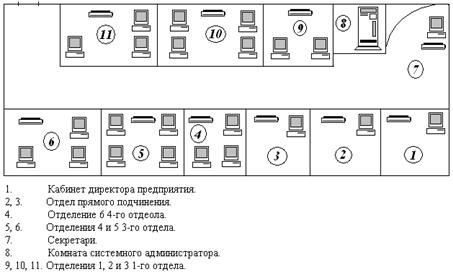
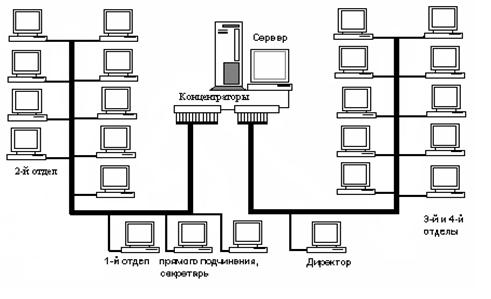
... доступа к информации. Поэтому очень важно, чтобы сети были защищены от постороннего вмешательства. Построение локальных сетей предусматривает создание программно-аппаратных решений с целью защиты информации от кражи. Для этого производится установка, настройка и обслуживание фаерволов, маршрутизаторов и коммутаторов. Обслуживание локальных компьютерных сетей должно проводиться непрерывно. ...
... надёжность системы, данный стандарт с успехом применяется в магистральных каналах связи. Сравнительный анализ существующих технологий представлен в Приложении А. 2. АНАЛИЗ И КОМПЛЕКС МЕРОПРИЯТИЙ ПО ОБСЛУЖИВАНЮ ЛОКАЛЬНОЙ СЕТИ СЛУЖБЫ ПО ДЕЛАМ ДЕТЕЙ СЕВЕРОДОНЕЦКОЙ ГОРОДСКОГО СОВЕТА 2.1 Административные, технические и программные характеристики Службы по делам детей Северодонецкой городской рады ...
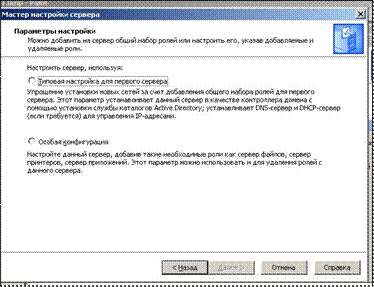
... концентратора, требуется также сетевой кабель, так называемый двужильный провод Ethernet RJ-45 (10BaseT или 100BaseT), который немного больше обычного телефонного кабеля. 3. Создание локальной сети 1. Обнаружение параметров сети. 2. Выбираем параметры настроек. 3. Задание корня DNS-имени ZALMAN. local. 4. Настраиваем IP-адрес и адрес DNS-сервера. 5. Локальные ...




... разнообразием активного коммутационного оборудования, которое применяется для локальных и глобальных связей. В данном разделе были рассмотрены стандарты беспроводного доступа к сети Интернет. Так же был рассмотрен вопрос о назначении локальной сети. 2. Конструкторская часть 2.1 Выбор и обоснование технологий построения ЛВС Исходя из технического задания, для связи рабочих станций в ...
0 комментариев