База данных
Модель данных
Реляционная модель
Общая интерпретация реляционных операций
Реляционное исчисление
Целостность реляционных данных
Проектирование базы данных
РАЗРАБОТКА БАЗЫ ДАННЫХ
РАЗРАБОТКА ПРИЛОЖЕНИЯ-КЛИЕНТА
Реализация приложения
Модуль данных DataModule1 и модуль DBUnit
Форма DeleteForm и модуль Delete
Форма AboutBox и модуль About
Расчет сметы затрат на проведение НИР
ОХРАНА ТРУДА
Производственная санитария
Техника безопасности
³ 1.3*40=56 А – условие выполняется
Охрана окружающей среды
Навигация
РАЗРАБОТКА БАЗЫ ДАННЫХ
Разработка базы данных
192006
знаков
8
таблиц
14
изображений
4. РАЗРАБОТКА БАЗЫ ДАННЫХ
4.1 Предметная область базы данных
База данных предназначена для хранения информации об электронных источниках литературы в виде файлов, упакованных в архивы. Файлы архивов физически располагаются на сервере предприятия и не упорядочены между собой. Названия файлов архивов и файлов источников могут не иметь семантической связи с тематикой источников. Пользователями БД являются работники предприятия, которым требуется тот или иной источник литературы или группа источников по заданной тематике.
Анализ запросов на литературу показывает, что для поиска подходящих источников (по тематике, названию, автору) и отбора нужного следует выделить следующие атрибуты источников литературы:
1) автор (фамилия и имена (инициалы) или псевдоним каждого автора источника литературы);
2) название (заглавие) источника литературы;
3) язык, на котором написан источник;
4) список тем (разделов), с которыми связан данный источник литературы.
К объектам и атрибутам, позволяющим охарактеризовать место расположение файлов источников, можно отнести:
1) полное файловое имя (путь и имя файла) архива источника литературы;
2) название основного (первого) файла источника литературы.
4.2 Построение инфологической модели
Анализ определенных выше объектов и атрибутов позволяет выделить сущности проектируемой базы данных и, приняв решение о создании реляционной базы данных, построить ее инфологическую модель на языке "Таблицы-связи" (рис. 4.1). Для того, чтобы БД сохраняла целостность при любых операциях над ней (вставка, удаление, изменение кортежей), все отношения в ней нормализованы (БД приведена к третей нормальной форме).
Выделены следующие сущности:
1) “Авторы” (“Код автора”, “Автор”) – эта сущность отводится для хранения сведений об авторах литературных источников. Так как фамилия и имена (инициалы) автора (группы авторов) могут быть достаточно громоздкими и будут многократно встречаться в разных источниках, то их целесообразно нумеровать и ссылаться на эти номера. Для этого вводится целочисленный атрибут "Код автора", который будет автоматически наращиваться на единицу при вводе в базу данных нового автора. Самой же информации об авторе соответствует атрибут “Автор”.
2) “Заглавия” (“Код заглавия”, “Заглавие”). Выделение этой сущности позволит сократить объем данных и снизить вероятность возникновения противоречивости. Как и сущность “Авторы”, данная сущность характеризуется двумя атрибутами – целочисленным "Код заглавия", который будет автоматически наращиваться на единицу при вводе в базу данных нового заглавия и “Заглавие”, непосредственно отражающий заглавие источника литературы.
3) “Языки” (“Код языка”, “Язык”) – эта сущность отражает информацию об языке, на котором написан источник литературы. Данная сущность также включает в себя два атрибута: “Код языка” – целочисленный автоматически увеличивающийся и “Язык” –название языка источника литературы.
4) “Книги” (“Код книги”, “Код автора”, “Код заглавия”, “Код языка”, “Темы”, “Архив”, “Файл”) – эта сущность отражает информацию о конкретных источниках литературы.
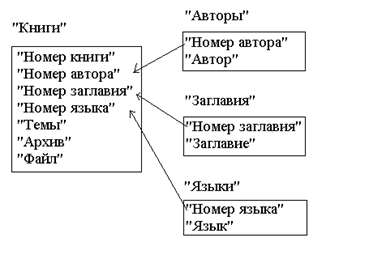
Рисунок 4.1 Инфологическая модель БД
4.3 Проектирование базы данных
Для физической реализации БД использовалась СУБД InterBase версии 6.0. Эта СУБД была выбрана по ряду причин:
1) поддержка данной СУБД реляционных и распределённых баз данных;
2) высокая надёжность;
3) наличие реализации СУБД для ОС Linux (кроссплатформенность продукта);
4) соответствие встроенного языка SQL стандарту ANSI SQL-92;
5) малые требования к дисковому пространству и памяти;
6) свободное распространение СУБД в открытых кодах.
Полный листинг кода создания БД на языке SQL (встроенный в InterBase) находится в приложении 20. Поэтапно рассмотрим физическую реализацию БД. Зададим 3 диалект БД и русскую кодировку символов WIN1251. Создаём пустую БД от лица суперпользователя SYSDBA со стандартным паролем “masterkey”. Размер страница БД установлен равным размеру кластера в файловой системе NTFS 4048 байт. Для удаления из строк пробелов и преобразования строк к верхнему регистру были декларированы внешние функции Upper и Trim. Они реализованы на языке программирования Delphi и физически расположены в динамически связуемой библиотеке (DLL) Str.dll.
Каждая из полученных сущностей должна быть представлена базовой таблицей:
Таблица Authors – информация об авторах источников, состоящая из следующих полей:
1) NumAut – числовое автоинкрементное поле, содержащее номер автора и являющееся ключевым полем отношения;
2) Author – строковое поле, содержащее фамилию и инициалы автора (группы авторов), являющееся уникальным.
Таблица Titles – информация об названиях источников состоящая из следующих полей:
1) NumTit – числовое автоинкрементное поле, содержащее номер заглавия и являющееся ключевым полем отношения;
2) Titles – строковое поле, содержащее название источника и являющееся уникальным.
Таблица Languages – языки источников, состоящая из следующих полей:
1) NumLan – числовое автоинкрементное поле, содержащее номер языка и являющееся ключевым полем отношения;
2) Language - строковое поле, содержащее язык источника и являющееся уникальным полем.
Таблица Books – информация об источниках литературы, состоящая из следующих полей:
1) NumBook – числовое автоинкрементное поле, содержащее номер книги и являющееся ключевым полем отношения;
2) NumAut – числовое поле, содержащее код (номер) автора в таблице Authors;
3) NumTit - числовое поле, содержащее код (номер) названия в таблице Titles;
4) NumLan - числовое поле, содержащее код (номер) языка в таблице Languages;
5) Sections – текстовое (мемо) поле, содержащее список тем, связанных с источником;
6) Atchive – строковое поле, содержащее полное файловое имя архива источника;
7) MainFile – строковое поле, содержащее имя главного файла источника.
Таблица Books связана с таблицами Authors, Titles, Languages типом связи “один-ко-многим” посредством внешних ключей NumAut, NumTit и NumLan.
Создаём таблицу Authors с непустыми полями NumAut типа INTEGER и Author типа VARCHAR длиной 50 символов, поле NumAut является первичным ключом, а Author уникальным полем. Аналагично создаём таблицу Titles с непустыми полями NumTit типа INTEGER и Title типа VARCHAR длиной 200 символов, поле NumTit является первичным ключом, а Title уникальным полем. Также создаём таблицу Languages с непустыми полями NumLan типа INTEGER и Language типа VARCHAR длиной 20 символов, поле NumLan является первичным ключом, а Language уникальным полем. Наконец создаём таблицу Books с полями NumLan – непустое поле типа INTEGER, являющееся первичным ключом таблицы; NumAut - поле типа INTEGER; NumTit - поле типа INTEGER; NumLan - поле типа SMALLINT; Sections – поле типа BLOB подтипа TEXT; Archive – непустое поле типа VARCHAR длиной 32765 байт и MainFile – непустое поле типа VARCHAR длиной 255 байт. Также на таблицу Books накладываются ограничения, посредством задания внешних ключей NumAut, NumTit и NumLan, которые связаны с аналогичными полями в таблицах Authors, Titles и Languages.
Для того, чтобы поля таблиц NumBook, NumAut, NumTit и NumLan автоматически увеличивались при добавлении новой записи необходимо задать создать генераторы. Назовём их GenBook, GenAut, GenTit и GenLan для соответственно. Для их увеличения созданы триггеры InsBook, InsAut, InsTit и InsLan, которые активизируются перед занесением новой записи в соответствующую таблицу и выполняют увеличение генераторов на единицу посредством вызова встроенной процедуры GEN_ID.
Создадим представление (VIEW), которое состоит из следующих полей Number, Author, Title, Language, Sections, Archive и File. Они являются результатом выборки следующих полей таблиц Books.NumBook, Authors.Author, Titles.Title, Languages.Language, Books.Sections, Books.Archive, Books.MainFile, при условии
Books.NumAut=Authors.NumAut AND
Books.NumTit=Titles.NumTit AND
Books.NumLan=Languages.NumLan.
Это представление предназначено для скрытия реальной структуры БД от пользователя и облегчения использования БД прикладными программистами.
Для добавления, изменения и удаления записей из таблиц БД и других целей предусмотрены ряд хранимых процедур:
· DeleteAll – очистка всей БД (удаление всех записей во всех таблицах) и обнуление генераторов;
· DeleteBook – удаление заданного источника;
· InsertBook – вставка нового источника;
· SearchBook – поиск источника по заданным атрибутам с учётом регистра символов;
· SearchUpBook - поиск источника по заданным атрибутам без учёта регистра символов;
· UpdateAuthor – изменение автора источника;
· UpdateBook – изменение атрибутов источника;
· UpdateTilte – изменение названия источника;
· UpdateLanguage – изменение языка источника;
· IsWriter – проверка прав пользователя на изменение БД.
Для управления безопасностью БД созданы три роли:
· Admin – имеет права на любые действия с БД (чтение, изменение структуры и данных);
· Writer – имеет права на чтение и изменение данных БД, но не имеет прав на изменение структуры БД;
· Reader – имеет права только на чтение данных БД.
Эти роли, исходя из выше сказанного, наделены соответствующими правами на соответствующие таблицы и хранимые процедуры.
Похожие работы
... Таблица «Счет» Таблица «Товар» Таблица «Товар по счету» Таблица «Товарные группы» Лабораторная работа № 2. Разработка запросов отбора данных и вычислений Цель работы приобретение навыков в описании запросов к базе данных на языке QBE (Query by Example). Выборка неоплаченных счетов Результат выполнения: Выборка поставок Результат выполнения: Поиск ...
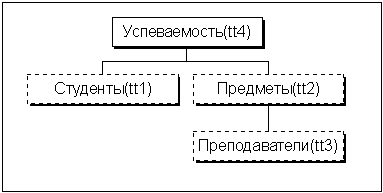




... : pered=record st:array[1..12] of string; m:byte; {количество строк в меню} end; temr,tt1,tt2,tt3,tt4:cc – Таблицы базы данных. Тут tt1 – таблица с данными о студентах, tt2 – предметы, tt3 – преподаватели, tt4 – оценки (успеваемость). Temr – временная таблица. Все эти переменные являются динамическими списками. Они описаны в файле tips.pas: tabl2=record {Сама ...

... от используемых в дальнейшем программных средств [1]. Для описания инфологической модели были использованы графические средства. Описание связи «объект-свойство» изображено на рис. 2.2.1 графического материала. База данных «Кадры» разрабатывается для хранения текстовой информации (хотя для удобства ввода некоторые поля таблиц – числовые), поэтому в приложении не будут применены вычисления ...
... проекта 1. Введение. Целью данного курсового проекта является структурирование данных и разработка пользовательского интерфейса. В курсовом проекте рассмотрены следующие теоретические вопросы и практические задания: ü проведен системно-комплексный анализ выбранного объекта автоматизации ü разработана структура пользовательского интерфейса автоматизированной системы &# ...
0 комментариев