Операционная система Windows CE
Новые тенденции встроенных ОС
Mac OS
Mac OS X
Короткая история и позиционирование системы
Средства взаимодействия
Образы
Архитектура
Файловая система
Сетевые взаимодействия
История и архитектура мейнфреймов
Операционная система VSE/ESA
Операционная система z/OS
Операционная система z/VM
Основные свойства платформы Java
Виртуальная машина Java
Многопоточность и синхронизация
Управление памятью в куче
Защита ресурсов
JavaOS и Java для тонких клиентов
Навигация
Операционная система z/OS
Операционные системы "тонких" клиентов
257667
знаков
0
таблиц
26
изображений
12.3 Операционная система z/OS
z/OS (раньше - OS/390, еще раньше - MVS) является стратегической для IBM ОС мейнфреймов [21, 24, 41]. Именно в этой ОС в первую очередь осваиваются новые свойства аппаратной платформы, именно в этой ОС в первую очередь становятся доступными новые версии стратегических продуктов промежуточного программного обеспечения, именно эта ОС рассчитана на применение в самых мощных и производительных вычислительных комплексах и sysplex'ах (тесно связанных многомашинных комплексах, которые "выглядят" с точки зрения управления и распределения нагрузки как одна вычислительная система). Последняя на сегодняшний день версия этой ОС - z/OS V1R3.
ОС OS/360 MVT, находившаяся "у истоков" этой линии, работала только с реальной памятью, создавая в ней динамические разделы по мере необходимости. В ОС MVS сложились концепции управления виртуальной памятью и другими основными ресурсами, оставшиеся в принципе неизменными и до настоящего времени. Переименование системы в OS/390 было связано с интеграцией в систему ряда программных серверов, ранее существовавших в виде отдельных программных продуктов, а в z/OS - с адаптацией к 64-разрядной z-архитектуре. Длительная история эволюционного развития MVS - OS/390 - z/OS привела к тому, что на сегодняшний день z/OS является системой настолько сложной и богатой возможностями, что описать их все даже на структурном уровне - задача невыполнимая в объеме одной книги. Тем не менее, мы попытаемся (ни в коей мере не претендуя на полноту) дать читателю некоторое представление о компонентах управления теми ресурсами, которые являются предметом нашего основного внимания.
Примерная структура системного программного обеспечения в составе z/OS показана на рисунке 12.5.
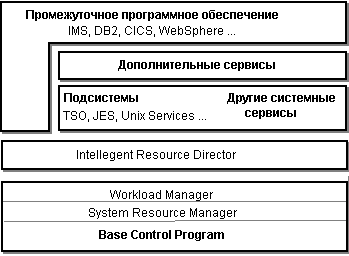
Рисунок 12.5 Структура программного обеспечения z/OS
Мы отметили, что развитие этой ОС происходило исключительно эволюционным путем. Внедрение новых возможностей управления ресурсами в ОС происходит, как правило, по следующему сценарию:
новый управляющий сервис разрабатывается и внедряется как отдельный программный продукт, продаваемый отдельно от ОС;
новый программный продукт включается в комплект поставки ОС;
новый продукт интегрируется с ядром ОС, возможно, становится частью ядра.
Хотя понятие "ядро" для z/OS точно не определено, мы называем ядром Базовую Управляющую Программу (BCP - Base Control Program), осуществляющую низкоуровневое управление такими ресурсами, как память, процессы, средства коммуникаций. Надстройки над низкоуровневым управлением (в составе самой BCP или на более высоких уровнях системного программного обеспечения) позволяют управлять политиками распределения ресурсов. Ряд системных сервисов, не входящих в состав ядра, но работающих в режиме супервизора, являются подсистемами - средами выполнения приложений. Дополнительные системные сервисы расширяют возможности сервисов, включенных в базовый комплект. Некоторые программные продукты IBM, относящиеся к классу промежуточного программного обеспечения, также можно назвать подсистемами, так как они создают собственные среды. Эти продукты также тесно интегрированы с системой, и в ядро системы включены функции поддержки этих продуктов.
Управление памятью
Управление памятью является, возможно, самым интересным свойством z/OS. Аббревиатура первого названия ОС - MVS расшифровывается как Multiply Virtual Storage и отражает именно аспект управления памятью. Каждая задача в MVS (и в ее современных наследниках) обладает собственным виртуальным АП. Размер этого АП составлял 16 Мбайт в ранних версиях ОС (24-битный адрес), 2 Гбайта, начиная с MVS/XA (31-битный адрес) и 16 эксабайт в z/OS (64-битный адрес). Мы рассмотрим сначала первые две модели адресации, а затем отдельно расскажем об "освоении" системой 64-битного адреса.
Распределение виртуального АП для 24- и 31-битого размера адреса показано на рисунке 12.6. Нижняя часть виртуального АП занята системой, она перекрывается для всех АП, но для прикладных программ недоступна. Верхняя часть виртуального 16-Мбайтного АП - общая область памяти, занимаемая объектами, совместно используемыми разными задачами. Это как разделяемые объекты данных, так и совместно используемые программные коды, например, системные сервисные службы, такие как TSO и т.п. АП между этими двумя областями является частным АП задачи. При расширении АП до 2 Гбайт дополнительная часть общей области памяти, смежная со "старой" появляется по другую сторону 16-Мбайтной границы, остальная часть дополнительного АП является дополнительным частным пространством задачи. Таким образом, задачи, в которых выполняются программы, разработанные для 24-разрядных версий MVS, видят привычную для себя структуру 16-Мбайтного АП, задачи, созданные для новых версий, видят полную структуру 2-Гбайтного АП. Размещение в памяти и выполнение программы определяется параметрами RMODE и AMODE. Первый из этих параметров определяет размещение программы в нижней или верхней части АП. Значение параметра AMODE отображается на соответствующий бит PSW и определяет режим выполнения некоторых команд процессора, при AMODE=24 команды, работающие с адресами, используют 24-битный адрес, при AMODE=31 - 31-битный адрес. Каждая программная секция характеризуется своими параметрами RMODE и AMODE, таким образом, режимы адресации могут изменяться и в ходе выполнения одной задачи.
z/OS предоставляет также приложениям возможности использовать дополнительные АП. Хотя реализации всех этих возможностей используют описанные выше регистры доступа AR, с точки зрения приложений их можно разделить на 4 направления:
коммуникации "пересечения памяти" (cross memory communications);
явное использование дополнительных АП (AR ACS mode);
пространства данных (data spaces);
гиперпространства (hiperspaces).
Коммуникации пересечения памяти позволяют программе передавать управление в другое АП. Управление передается не "напрямую", а через системный вызов (блок запроса SRB). Различают синхронные и асинхронные коммуникации пересечения памяти.
В так называемом первичном режиме AR-программа работает только с данными, расположенными в первичном АП. В режиме же управления памятью через регистры доступа в режиме ACS AR-программа может определять регистры AR, используемые для трансляции адресов и, таким образом, употреблять обычные команды обращения к данным для работы с параллельными АП. Программа, однако, не может передавать управление в другое АП, для этого режим ACS AR надо комбинировать с коммуникациями пересечения памяти.
Пространства данных и гиперпространства являются дополнительными именованными АП размером от 4 Кбайт до 2 Гбайт, используемыми только для размещения данных.
Программа, использующая пространства данных, должна работать в режиме ACS AR. Она использует системные вызовы для создания и удаления пространства данных и управления им, команды же, выполняемые в основном АП, могут непосредственно манипулировать данными в пространстве данных.
Программа, использующая гиперпространства, может работать в первичном режиме AR. Она использует системные вызовы для создания и удаления пространства данных и управления им, а также для того, чтобы пересылать данные между гиперпространством и основным АП. Обмен между первичным АП и гиперпространством ведется 4-Кбайтными блоками.
Пространства данных или гиперпространства могут содержать также и программные коды, но передавать управление на эти коды непосредственно программа не может. Для выполнения эти коды должны быть пересланы в буфер в первичном АП. Физически оба вида пространств могут размещаться как в основной, так и в расширенной памяти, но для пространства данных предпочтение отдается основной памяти, а для гиперпространства - расширенной. Для управления пространствами данных система использует те же механизмы страничного обмена, что и для первичного АП. Поскольку же манипулирование данными в гиперпространстве несколько ограничено, для управления гиперпространством используются более простые и более эффективные алгоритмы.
В z/OS имеется также механизм отображения в память объектов данных (data-in-virtual), аналогичный файлам, отображаемым в память, в Unix. Этот механизм позволяет назначить "окно" виртуальных адресов, просматривать в этом окне нужную часть объекта данных и перемещать окно по мере необходимости. Отображение данных возможно (и предпочтительно) в пространство данных или в гиперпространство.
Приложение получает память в своем виртуальном АП, используя системные вызовы явного (GETMAIN или STORAGE) или неявного выделения памяти. Управление выделением памяти ведется при помощи так называемых подпулов. Подпулы состоят из 4-Кбайтных блоков памяти и формируются динамически: блоки добавляются в подпул или удаляются из него по мере необходимости. Система удовлетворяет каждый запрос на выделение памяти из одного блока (разумеется, кроме тех случаев, когда размер запроса превосходит размер блока). При размещении небольших запросов система ищет свободное место в уже выделенных блоках по принципу "самый подходящий" и лишь при невозможности удовлетворить запрос таким образом выделяет новый блок.
При создании любой задачи для нее обязательно создается подпул 0, но в задаче может быть создано и большее число подпулов. Любой подпул может использоваться только одной задачей или разделяться несколькими задачами. Подпул 0 разделяется задачей со всеми ее подзадачами, но если подпул 0 задачи определен как неразделяемый, для каждой подзадачи будет создаваться свой подпул 0. Монопольно используемые подпулы освобождаются с окончанием задачи, которая ими владеет. Разделяемые подпулы сохраняются, пока сохраняется хотя бы одна из использующих их задач.
"64-разрядная революция" аппаратуры мейнфреймов осваивается z/OS за несколько шагов.
Первый шаг, сделанный в z/OS V1R1, обеспечил 64-битное управление реальной памятью, что позволило уменьшить страничный обмен и ограничения на память для прежних 31-разрядных приложений.
Со второго шага, сделанного в z/OS V1R2, обеспечивается поддержка 64-битной адресации в одном АП. Качественно картина виртуальной памяти приложения остается такой же, как и представленная на рисунке 12.6, но выше границы 2 Гбайт, называемой "планкой" (bar) появляется дополнительная часть частного АП. Любая 31-битная программа может теперь получать виртуальную память за планкой и манипулировать данными в этой памяти. Программа по-прежнему размещается в пределах 2 Гбайт, виртуальная память выше планки предназначена только для данных. Новый язык Ассемблера включает в себя новые команды для работы с данными за планкой и манипулирования с 64-разрядными регистрами общего назначения. Системные вызовы для работы с данными за планкой включают в себя прежние механизмы выделения и освобождения памяти - для совместимости со старыми программами, но система управляет пространством выше планки как объектами данных. В новых механизмах программа создает за планкой объекты данных, размер которых кратен 1 Мбайту. В V1R2 объекты данных не могут совместно использоваться в разных АП.
Третий шаг (z/OS V1R3) состоит во внедрении AMODE=64. В сочетании с новыми возможностями Редактора Связей и Загрузчика этот режим позволяет создавать полностью 64-разрядные программы.
Четвертый шаг, который будет реализован в следующей версии z/OS, - обеспечение возможности разделения объектов данных, размещенных за планкой между разными АП.
Параллельно с введением 64-разрядных возможностей в системные сервисы и низкоуровневое программирование они внедряются и в инструментальные средства (C/C++, Java), и в основные продукты промежуточного программного обеспечения (DB2, WebSphere и др.).
Управление процессами
АП в z/OS создается для задания. Как и в VSE, задание в z/OS состоит из нескольких последовательно выполняющихся программ - шагов задания. Для каждого шага задания создается задача (процесс). Структурой, представляющей задачу в системе, является блок управления задачей TCB (Task Control Block). Задача может порождать новые задачи (подзадачи) при помощи системных вызовов ATTACH (подзадача выполняется в первичном режиме AR) или ATTACHX (подзадача выполняется в режиме ASC AR). Порождаемые таким образом подзадачи имеют собственные блоки TCB и, таким образом, представляются как полноценные задачи, но все они выполняются в том же АП, что и породившая их задача. Порожденная подзадача выполняется параллельно с породившей и может порождать собственные подзадачи. Между задачей и ее подзадачами устанавливаются отношения "предок - потомок". Задача и ее подзадачи выполняются асинхронно, но выполнение задачи-предка может быть и синхронизировано с завершением задачи-потомка. Подзадача может порождаться с параметрами ECB или/и EXTR. Первый параметр назначает для подзадачи Блок Управления Событием (Event Control Block), в котором делается отметка о завершении подзадачи. Если подзадача создается с параметром ECB, ее TCB не удаляется с ее завершением, а сохраняется до тех пор, пока информация о завершении не будет востребована задачей-предком. Задача-предок может ожидать завершения потомка и получить информацию о его завершении, применяя системный вызов WAIT, параметром которого является ECB потомка. Параметр EXTR позволяет определить в задаче-предке процедуру, которая автоматически выполняется при завершении данного потомка.
Приоритеты выполнения определяются на двух уровнях:
приоритет АП;
приоритеты задач и подзадач.
Приоритет АП, как правило, определяется ОС из соображений обеспечения наилучшей загрузки системы (см. ниже). Однако этот приоритет может быть назначен и пользователем в операторах языка управления заданиями. Приоритет пользователя назначается дифференцированно для каждого шага задания. Приоритет АП, установленный пользователем для шага задания, во время выполнения шага изменяться в программе не может, но может меняться ОС.
Создавая задачу для шага задания, ОС присваивает ей диспетчерский (текущий) и граничный приоритеты. Подзадача по умолчанию наследует приоритеты своего родителя, но ей могут быть назначены и собственные приоритеты. Приоритеты подзадач могут меняться в программе системным вызовом CHAP. Приоритеты задач/подзадач, однако, никак не влияют на то, в каком порядке выбираются на выполнение программы - этот порядок определяется только приоритетом АП. Приоритеты же подзадач влияют на порядок их выборки на выполнение в пределах процессорного обслуживания, выделяемого для АП. В этих пределах приоритеты подзадач являются абсолютными: на выполнение выбирается подзадача с наивысшим приоритетом, текущая активная подзадача немедленно вытесняется, если подзадача с более высоким приоритетом приходит в состояние готовности.
Средства взаимодействия
Выше мы упомянули о блоках ECB, используемых для синхронизации выполнения задачи и ее подзадач. Однако блоки ECB являются более универсальным средством синхронизации выполнения. ECB используется с системными вызовами WAIT, POST и EVENTS. Системный вызов POST сигнализирует о совершении события, системные вызовы WAIT и EVENTS задерживают выполнение задачи до совершения одного или нескольких событий.
Для взаимного исключения доступа к ресурсам из разных программ используются системные вызовы ENQ и DEQ. В первом приближении их можно считать эквивалентным семафорным операциям P и V соответственно. При употреблении этих системных вызовов задается имя ресурса и масштаб. Имя (оно состоит из двух частей) в документации IBM называется именем ресурса, но на самом деле это скорее имя семафора, имена в операциях ENQ/DEQ назначаются произвольно и не имеют никакой связи с действительными именами ресурсов. Масштаб определяет область видимости ресурса:
масштаб STEP означает, что ресурс доступен только в данном АП;
масштаб SYSTEM означает, что ресурс доступен во всех АП, но только в данной вычислительной системе;
масштаб SYSTEMS означает, что ресурс доступен во всех АП всех вычислительных систем sysplex'а.
Комбинация имени ресурса и масштаба должна быть уникальной.
В отличие от обычных семафорных операций, системный вызов ENQ может выполняться в монопольном или разделяемом режиме, что соответствует классической задаче "читатели-писатели". Любое число задач может одновременно получать доступ к ресурсу в разделяемом режиме, только одна задача может иметь доступ к ресурсу в монопольном режиме.
Системный вызов ENQ может также выполняться и с условием. Предусмотренные для ENQ условия могут обеспечивать:
проверку состояния ресурса без его захвата;
захват ресурса только в том случае, если он немедленно доступен;
изменение режима захвата с разделяемого на монопольный;
захват ресурса только в том случае, если программа еще им не владеет.
Задачи, задержанные при выполнении операции ENQ, образуют очереди к ресурсам, которые обслуживаются по дисциплине FCFS. Размер такой очереди может быть, однако, ограничен, в этом случае попытка выполнения запроса ENQ, который переполнит очередь, приводит не к блокированию программы, а к завершению запроса с признаком ошибки.
Попытка захвата ресурса, которым программа уже владеет, приводит к аварийному завершению программы. Ответственность за обход тупиков лежит на программисте.
Системные вызовы в z/OS выполняются системными сервисными процедурами. Такая процедура представляется в системе Блоком Сервисной Процедуры SRB (Service Routine Block). SRB во многом аналогичен TCB, но SRB не может владеть АП. Однако SRB может получать и использовать память в АП вызвавшей его задачи и в системном АП. После вызова процедуры и создания для нее SRB сервисная процедура может выполняться параллельно с вызвавшей ее программой (даже с реальным параллелелизмом - на разных процессорах). Все системные процедуры являются реентерабельными и, следовательно, могут быть прерваны в ходе своего выполнения.
Подсистемы и управление ресурсами
Прежде чем рассмотреть принципы распределения ресурсов в системе, дадим краткие характеристики некоторым (далеко не всем) подсистемам в составе z/OS.
Подсистема ввода заданий JES (Job Entry Subsystem) обеспечивает выполнение пакетных заданий. Ее функции во многом аналогичны подсистеме POWER в VSE. JES интерпретирует операторы языка управления заданиями JCL и управляет очередями. В системе могут быть запущены несколько копий JES, каждая из которых создает свой системный образ. Имеются две версии JES - JES2 и JES3, которые различаются тем, что в JES2 выполняется независимое управление каждой запущенной копией, в JES3 осуществляется централизованное управление всеми копиями.
Подсистема разделения времени TSO/E (Time Sharing Option/Extention) - основной интерактивный интерфейс z/OS. TSO/E обеспечивает для конечных пользователей, программистов и администраторов набор команд и полноэкранных возможностей для подготовки программ, подготовки и выполнения заданий, выполнения управления системой. Как обязательная часть z/OS, TSO/E является базой для ряда других системных сервисов, таких как Book Manager, Hardware Configuration Definition и другие.
z/OS UNIX System Services обеспечивают использование z/OS как сверхмощного Unix-сервера. Службы приложений z/OS UNIX System Services включают в себя командный интерпретатор shell, утилиты и отладчик. Набор команд и утилит полностью соответствует спецификациям стандарта Single Unix Specification, известного также как Unix 95. Это позволяет программистам и пользователям, даже не знающим команд z/OS, взаимодействовать с z/OS как с Unix-системой. Отладчик предоставляет программистам набор команд для интерактивной отладки программ, написанных на языке C. Этот набор подобен аналогичным командам, существующим в большинстве Unix-систем. Службы ядра z/OS UNIX System Services совместно с языковыми средами обеспечивают соответствующий Single Unix Specification API для программирования на языке C, многопоточность и средства разработки клиент/серверных приложений. Это обеспечивает возможность программирования для z/OS как для Unix и переноса в z/OS приложений, созданных для Unix.
Еще MVS прошла сертификацию по стандартам POSIX, Single Unix Specification и OSF/1. Таким образом, z/OS соответствует Unix-ориентированным стандартам лучше, чем большинство систем, относящихся к семейству Unix, и является наилучшим Unix-суперсервером.
Планированием распределения ресурсов занимается Менеджер Системных Ресурсов - SRM (System Resource Manager), являющийся компонентом BCP. SRM определяет, какие АП получат доступ к системным ресурсам, и ту долю системных ресурсов, которая будет выделена каждому АП. SRM распределяет ресурсы между АП в соответствии с приоритетными требованиями, заданными в параметрах инсталляции, и стремится достичь оптимального использования ресурсов с точки зрения производительности системы. При определении параметров функционирования SRM работы, выполняемые в системе, разбиваются на группы, называемые доменами. Домены характеризуются общими характеристиками работы, и общим для домена показателем важности. Каждое выполняющееся АП попадает в тот или иной домен - пакетное задание, транзакция IMS, транзакция DB2, короткая или длинная команда TSO и т.д. Управление доменами дает возможность:
гарантировать доступ к системным ресурсам хотя бы минимальному количеству АП, принадлежащих к определенному типу работы;
ограничивать количество АП, имеющих доступ к ресурсам, для каждого типа работ;
назначать степень важности для каждого типа работ.
Управление характеристиками выполнения позволяет дифференцировать выполняемые работы, например, установить приоритет коротких транзакций над длинными, приоритет времени реакции над пропускной способностью и т.д.
Управление доменами позволяет установить, какие АП получают доступ к системным ресурсам. Диспетчеризация управляет долей системных ресурсов, получаемых каждым из допущенных АП. После того, как АП включено в мультипрограммный набор (набор АП, размещенных в основной памяти и допущенных к использованию ресурсов), все АП конкурируют за обладание ресурсами независимо от доменов, к которым они принадлежат. Диспетчеризация ведется по приоритетному принципу: работа с наивысшим приоритетом получает ресурс первой. Всего в системе имеется 256 уровней приоритетов, которые разбиты на 16 наборов по 16 уровней в каждом. Внутри каждого набора АП может иметь переменный или фиксированный приоритет. Фиксированные приоритеты более высокие, чем переменные. Фиксированный приоритет просто назначается АП в соответствии с параметрами, указанными в настройках SRM для домена. Переменные приоритеты периодически перевычисляются по алгоритму минимизации среднего времени ожидания.
SRM управляет использованием ресурсов в пределах всей системы и постоянно ищет пути преодоления дисбаланса - перегрузки ресурса или его простоя. Это достигается путем периодического пересмотра уровня мультипрограммирования - количества АП, которые находятся в основной памяти и готовы к диспетчеризации. Когда характеристики использования показывают, что ресурсы системы используются не полностью, SRM выбирает домен и увеличивает число допущенных АП в этом домене. Если показатели использования говорят о перегрузке системы, SRM уменьшает уровень мультипрограммирования.
Для уменьшения интенсивности страничного обмена SRM применяет так называемый "логический свопинг". Страничные кадры АП, подвергающегося логическому свопингу, сохраняются в основной памяти на время, не превышающее некоторого порогового значения, устанавливаемого SRM. Пороговое значение для логического свопинга перевычисляется динамически и зависит от текущей потребности системы в основной памяти.
SRM автоматически определяет наилучший состав АП в мультипрограммном наборе и количество основной памяти, выделяемое каждому АП, наиболее эффективное в рамках принятого уровня мультипрограммирования. При этом управление страничным обменом и использованием ЦП в рамках всей системы сочетается с индивидуальным управлением рабочим набором каждого АП. Таким образом, показатели свопинга определяются общесистемными показателями страничного обмена и требованиями рабочего набора, причем последние имеют некоторый приоритет.
SRM также определяет приоритеты АП в очередях ввода-вывода. По умолчанию эти приоритеты такие же, как и диспетчерские приоритеты, но в параметрах SRM для доменов могут быть назначены приоритеты ввода-вывода выше или ниже их диспетчерских приоритетов.
SRM управляет распределением дисковых устройств и контролирует использование таких ресурсов, как вторичная память (дисковые области, используемые для свопинга - они не входят в дисковое пространство, управляемое файловой системой), область системных очередей и ресурс страничных кадров. При нехватке этих ресурсов SRM предпринимает меры, сводящиеся к уменьшению уровня мультипрограммирования.
Настройка SRM производится при инсталляции ОС и продолжается в ходе ее эксплуатации. Это процесс итеративный и, возможно, бесконечный, так как в ходе эксплуатации характеристики выполняемого системой потока работ могут уточняться и меняться. Мы уже отмечали в нашей книге, что мейнйфреймы обладают весьма высоким показателем производительность/стоимость, но реально высоким этот показатель может быть только тогда, когда производительность будет востребована в полном объеме. Эффективность работы SRM существенно зависит от параметров, заданных при его настройке, а гарантировать правильность определения пользователем большого числа параметров, многие из которых могут находиться в сложной зависимости друг от друга, невозможно. Поэтому возникла необходимость переложить планирование нагрузки в вычислительной системе или sysplex'е на ОС. В настоящее время надстройка над SRM, осуществляющая это планирование - Менеджер Нагрузки (WLM - Workload Manager) - включена в ядро ОС. WLM требует от администратора нагрузки задания определения сервиса и сам реализует это определение в рамках системы или sysplex'а. Определение сервиса производится не в терминах системных параметров, как для SRM, а в терминах пользователя. Таким образом, WLM требует от пользователя определение того, что нужно сделать, а не того, как это делать. Как это делать, WLM решает сам, учитывая конфигурацию системы и требования всех используемых подсистем, обеспечивающих собственные среды выполнения - как входящих в состав ОС (TSO, JES, Unix System Services и др.), так и отдельных программных продуктов (CICS, DB2, MQSeries и др.).
Определение сервиса включает в себя:
Политику сервиса - набор бизнес-целей управления, таких как время реакции и максимальная задержка выполнения. Каждой цели придается также весовой коэффициент, характеризующий важность достижения этой цели.
Классы сервиса, которые разбиваются на "периоды" - группы работ с одинаковыми целями и требованиями к ресурсам.
Группы ресурсов, которые определяют границы процессорной мощности в sysplex'е. Назначая классу сервиса группу ресурсов, администратор загрузки определяет минимальный и максимальный объем процессорного обслуживания для работы.
Правила классификации, которые определяют, как отнести поступившую работу к тому или иному классу сервиса.
Прикладные среды - группы прикладных функций, которые выполняются в АП сервера и могут быть вызваны клиентом. WLM в соответствии с определенными целями автоматически активизирует или останавливает АП сервера.
Среды планирования - списки ресурсов (первичных и вторичных) с отражением их состояния, которые позволяют гарантировать, что система (в составе sysplex'а) обладает достаточным ресурсом для выполнения работы.
Классы отчетности, используемые для получения более подробной информации о производительности внутри класса сервиса.
В соответствии с определением сервиса WLM обеспечивает распределение нагрузки между процессорами одной вычислительной системы и системами всего sysplex'а, управление временем задержки работы после прихода ее в состояние готовности, управление анклавами (транзакциями, например, DB2, выполняющимися параллельно в разных АП, возможно, на разных системах sysplex'а), управление запросами клиентов к серверами и получение информации о состоянии. Управление ведется WLM с динамической обратной связью, с учетом нагрузки в каждый текущий момент, а также распределения нагрузки на предыдущем интервале времени.
Следующим шагом в оптимизации использования ресурсов мейнфреймов и их sysplex'ов стало внедрение Интеллектуального Распорядителя Ресурсами IRD (Intellegent Resource Director). IDR обеспечивает возможность управлять несколькими образами операционной системы, выполняющимися на одном сервере (в разных логических разделах), как одним вычислительным ресурсом с динамическим управлением нагрузкой и балансировкой физических ресурсов - процессоров и каналов ввода-вывода - между многими виртуальными серверами. Система динамически перераспределяет эти ресурсы в соответствии с определенными бизнес-приоритетами с тем, чтобы удовлетворить непредсказуемые требования задач электронного бизнеса. IRD включает в себя три основных компонента:
LPAR CPU Management - логические разделы (LPAR) на одном z-сервере объединяются в виртуальные sysplex-кластеры и управляются в соответствии с бизнес-целями и их важностью, сформулированными для WLM;
Dynamic Channel Path Management - дает возможность динамически переключать канальные пути (через переключатель ESCON Director) от одного контроллера к другому, таким образом, WLM получает возможность обеспечивать раздел большей или меньшей пропускной способностью по вводу-выводу - в соответствии с требованиями и важностью выполняемой в нем задачи;
Channel Subsystem Priority Queuing - распространяет возможности приоритетной диспетчеризации ввода-вывода на весь LPAR-кластер: если важная задача не может обеспечить выполнение своих целей из-за нехватки пропускной способности ввода-вывода, раздел, выполняющий эту задачу, получает дополнительные каналы ввода-вывода.
IRD является частью широкомасштабного проекта IBM eLiza, целью которого является создания фундамента для информационных систем с уменьшенной сложностью и стоимостью эксплуатации, использования, администрирования. Хотя проект eLiza не ориентирован на единственную аппаратную платформу и операционную среду, по вполне понятным причинам z-серверы и z/OS являются "передним краем" его реализации. Цели проекта eLiza сформулированы как: самооптимизация (self-optimization), самоконфигурирование (self-configuration), самовосстановление (self-healing) и самозащита (self-protection).
Самооптимизация заключается в свойствах WLM и IRD эффективно перераспределять ресурсы в условиях непредсказуемой рабочей нагрузки. В z/OS V2 планируется распространить возможности IRD на разделы, выполняющие ОС, отличные от z/OS (z/VM, Linux).
Самоконфигурирование поддерживается такими средствами, как msys for Setup (обеспечение простой для пользователя установки программного обеспечения) и z/OS Wizards - web-базированные диалоговые средства настройки системы.
Самовосстановление поддерживается:
множеством функций контроля и восстановления оборудования (Hardware RAS), среди которых - определение различных сбоев и в ряде случаев - автоматическое переключение и восстановление, plug and play и "горячее" переключение ввода-вывода и др.;
дуплексной передачей структур соединения (System-Managed CF Structure Duplexing) - устойчивым механизмом, позволяющим обеспечить неразрывное соединение;
msys for Operations - обеспечением лучшей работоспособности приложений за счет большей информации о ресурсах и самовосстановления критических ресурсов, а также снижения вероятности и облегчения восстановления из-за ошибок оператора;
System Automation for OS/390 - продуктом, обеспечивающим восстановление приложений, ресурсов системы и sysplex'а - на базе принятой политики обслуживания.
Самозащита обеспечивается:
Intrusion Detection Services - средством, позволяющим обнаруживать атаки на систему и выбирать механизмы защиты;
Public Key Infrastructure - встроенной в z/OS системой аутентификации и авторизации на основе открытого ключа;
средствами безопасности, являющимися промышленными стандартами: LDAP, Kerberos, SSL, цифровые сертификаты и т.д.
Часть описанных средств уже имеется в составе z/OS, в рамках проекта eLiza предполагается их интеграция, расширение их возможностей в новых версиях, создание новых средств и перенос их на другие аппаратные платформы и в другие ОС IBM.
Похожие работы
... , выдачей и приёмом лицензий). В условиях крупных сетей рекомендуется выделение под сервер лицензий отдельного компьютера (или нескольких - для резервирования). 1.1 Архитектура терминальных устройств В компьютерных технологиях трёхуровневая архитектура, синоним трёхзвенная архитектура (по англ. three-tier или Multitier architecture) предполагает наличие следующих компонентов приложения: ...
... ФС в разделе MS-DOS. Это конфигурационный файл в котором содержится информация о драйверах используемых в процессе запуска ФС. Пункт доступен супервизору или его эквивалентам. «Система учета» NetWare обладает очень гибкой системой учета ресурсов, предоставляемых в общее пользование. Используя данный пункт меню можно просмотреть, а так же имея определенные права настроить плату за использование ...
... числе на промышленных предприятиях, больше подходят клиент-серверные СУБД. Мы рассмотрим особенности таких распространенных СУБД, как Oracle и MS SQL Server. Глава 4. Язык SQL в системах управления базами данных SQL (англ. Structured Query Language — язык структурированных запросов) — универсальный компьютерный язык, применяемый для создания, модификации и управления данными в реляционных ...
... ОС Windows 95, необходимость выбора тех конкретных объектов, к которым необходимо ограничить доступ. Настоящая работа посвящена разработке программы защиты объектов операционной системы WINDOWS95 работающей в многопользовательском режиме под управлением сервера Novell NetWare (Windows NT, Unix), позволяющей проводить защиту объектов ОС на уровне пользователя. Под защитой объектов ОС Windows 95 ...
0 комментариев