Навигация
Переходит к следующей (и последней) подцели в правиле, к сравнению
80531
знак
5
таблиц
5
изображений
7. Переходит к следующей (и последней) подцели в правиле, к сравнению
Price < 25000.
8. Проверка завершается неудачно, и Visual Prolog пытается совершить поиск с возвратом с целью найти другую машину для проверки. Отсечение предотвращает попытку решить последнюю подцель, и наше целевое утверждение завершается неудачно.
6.1.2 Предотвращение поиска с возвратом к следующему предложениюОтсечение может быть использовано, как способ сообщить Visual Prolog, что он выбрал верное предложение для определенного предиката. Например, рассмотрим следующий фрагмент:
r(1) :-
!,
а, b, с.
r(2):-
!,
d.
r(3):-
!,
с.
r(_) :-
write("This is a catchall clause.").
Использование отсечения делает предикат r детерминированным. В данном случае Visual Prolog выполняет обращение к r с единственным целым аргументом. Предположим, что произведено обращение r(l). Visual Prolog просматривает программу в поисках соответствия для обращения; он находит его с первым предложением, определяющим r. Поскольку имеется более чем одно возможное решение для данного обращения, Visual Prolog проставляет точку возврата около этого предложения.
Теперь Visual Prolog начинает обработку тела правила, проходит через отсечение и исключает возможность возвращения к другому предложению r. Это отменяет точки поиска с возвратом, повышая эффективность выполнения программы, а также гарантирует, что отлавливающее ошибки предложение будет выполнено лишь в том случае, если ни одно из условий не будет соответствовать обращению к r.
Обратите внимание, что конструкция такого типа весьма похожа на конструкцию case в других языках программирования; условие проверки записывается в заголовке правил. По возможности, всегда следует помещать проверочное условие именно в заголовок правила, — это повышает эффективность программы и упрощает ее чтение.
Детерминизм и отсечениеЕсли бы предикат r, определенный в предыдущей программе, не содержал отсечений, то это был бы недетерминированный предикат (способный производить множественные решения при помощи поиска с возвратом). В предыдущих реализациях Пролога программисты должны были обращать особое внимание на недетерминированные предложения из-за сопутствующих им дополнительных требований к ресурсам памяти. Теперь Visual Prolog сам выполняет проверку на недетерминированные предложения, облегчая вашу работу.
В Прологе существует директива компилятора check_determ. Если вставить эту директиву в самое начало программы, то Visual Prolog будет выдавать предупреждение в случае обнаружения недетерминированных предложений в процессе компиляции.
Можно превратить недетерминированные предложения в детерминированные, вставляя отсечения в тело правил, определяющих данный предикат.
Предикат notСледующая программа ch04el0.pro (рис. 5.) демонстрирует, как вы можете использовать предикат not для того, чтобы выявить успевающего студента: студента, у которого средний балл (GPA) не менее 3.5 и у которого в настоящее время не продолжается испытательный срок.
domains
name = symbol
gpa = real
predicates
honor_student(name)
student(name, gра)
probation(name)
clauses
honor_student (Name) :-
student(Name, GPA),
GPA>=3.5,
not(probation(Name)).
student ("Betty Blue", 3.5).
student ("David Smith", 2.0).
student ("John Johnson", 3.7).
probation ("Betty Blue").
probation ("David Smith").
goal
honor_student (X) .
Рис. 5. Программа ch04e10.pro
При использовании предиката not необходимо иметь в виду следующее:
Предикат not будет успешным, если не может быть доказана истинность данной подцели.
Это приводит к предотвращению связывания внутри not несвязанных переменных. При вызове изнутри not подцели со свободными переменными, Visual Prolog возвратит сообщение об ошибке: "Free variables not allowed in not or retractall" (Свободные переменные не разрешены в not или retract). Это происходит вследствие того, что для связывания свободных переменных в подцели, подцель должна унифицироваться с каким-либо другим предложением и выполняться. Правильным способом управления несвязанными переменными подцели внутри not является использование анонимных переменных.
Первый пример работает правильно:
likes (bill, Anyone) :-% Anyone — выходной аргумент
likes(sue, Anyone),
not(hates(bill, Anyone).
В этом примере Anyone связывается посредством likes (sue, Anyone) до того, как Visual Prolog делает вывод, что hates (bill, Anyone) не является истиной. Данное предложение работает корректно.
Если пример изменить таким образом, что обращение к not будет выполняться первым, то получите сообщение об ошибке: "Free variable are not allowed in not" (Свободные переменные в not не разрешены).
likes(bill, Anyone):-% Это не будет работать правильно
not(hates(bill, Anyone)),
likes(sue, Anyone).
Даже если вы замените в not (hates (bill, Anyone)) Anyone на анонимную переменную, и предложение, таким образом, не будет возвращать ошибку, все равно получите неправильный результат.
likes(bill, Anyone):- % Это не будет работать правильно
not(hates(bill, _)),
likes(sue, Anyone).
Это предложение утверждает, что Биллу нравится кто угодно, если неизвестно ничего о том, кого Билл ненавидит, и если этот "кто-то" нравится Сью. Подлинное предложение утверждало, что Биллу нравится тот, кто нравится Сью, и при этом Билл не испытывает к этому человеку ненависти.
Неверное использование предиката not приведет к сообщению об ошибке или к ошибкам в логике вашей программы.Простые и составные объекты
До сих пор мы работали только основными видами объектов данных Visual Prolog, таких как числа, идентификаторы и строки. Visual Prolog может создавать не только простые, но и составные типы.
5. Простые объекты данных
Простой объект данных — это переменная или константа. Не путайте это значение слова "константа" с символьными константами, которые вы определяете в разделе constants программы. То, что мы здесь называем константой, это нечто, идентифицирующее объект, который нельзя изменять: символ (char), число (integer или real) или атом (symbol или string).
Константы включают числа, символы и атомы. Числа и символы были рассмотрены ранее.
Атомы имеют тип идентификатор (symbol) или строка (string). Отличие между ними — главным образом вопрос машинного представления и реализации, и, в основном, оно синтаксически не заметно. Когда атом передается в качестве аргумента при вызове предиката, то к какому домену принадлежит атом — symbol или string -определяется по тому, как описан этот аргумент в декларации предиката.
Visual Prolog автоматически преобразует типы между доменами string и symbol, поэтому вы можете использовать атомы symbol в доменах string и наоборот. Однако принято считать, что объект в двойных кавычках принадлежит домену string, а объект, не нуждающийся в кавычках, домену symbol. Атомы типа symbol — это имена, начинающиеся со строчной буквы и содержащие только буквы, цифры и знак подчеркивания.
Атомы типа string выделяются двойными кавычками и могут содержать любую комбинацию литер, кроме ASCII-нуля (0, бинарный нуль), который обозначает конец строки атома.
Примеры строк и идентификаторов приведены в табл. 1.
Таблица 2. Строки и идентификаторы
| Атомы-идентификаторы | Атомы-строки |
| food | "Jesse James" |
| rick_Jones_2nd | "123 Pike street" |
| fred_Flintstone_1000_Bс_Bedrock | "jon" |
| a | "a" |
| new_york | "New York" |
| pdcProlog | "Visual Prolog, by Prolog Development Center" |
Так как string/symbol взаимозаменяемы, их отличие не существенно. Однако имена предикатов и функторы для составных объектов должны соответствовать синтаксическим соглашениям домена symbol.
6. Составные объекты данных и функторы
Составные объекты данных позволяют интерпретировать некоторые части информации как единое целое таким образом, чтобы затем можно было легко разделить их вновь. Возьмем, например, дату "октябрь 15, 1991". Она состоит из трех частей информации — месяц, день и год. Представим ее на рис. 1, как древовидную структуру.
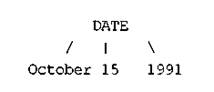
Рис. 6. Древовидная структура даты
Можно объявить домен, содержащий составной объект date:
domains
date_cmp = date(string,unsigned,unsigned)
а затем просто записать:
D = date("0ctober",15,1991) .
Такая запись выглядит как факт Пролога, но это не так — это объект данных, который вы можете обрабатывать наряду с символами и числами. Он начинается с имени, называемого функтором (в данном случае date), за которым следуют три аргумента.
Функтор в Visual Prolog — не то же самое, что функция в других языках программирования; это просто имя, которое определяет вид составного объекта данных и объединяет вместе его аргументы. Функтор не обозначает, что будут выполнены какие-либо вычисления.
Аргументы составного объекта данных могут сами быть составными объектами. Например, вы можете рассматривать чей-нибудь день рождения (рис. 2), как информацию со следующей структурой:
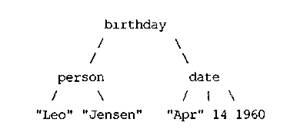
Рис. 2. древовидная структура даты рождения.
На языке Пролог это выглядит следующим образом:
birthday(person("Leo","Jensen"),date("Apr",14,1960))
7. Унификация составных объектовСоставной объект может быть унифицирован с простой переменной или с составным объектом (возможно, содержащим переменные в качестве частей во внутренней структуре), который ему соответствует. Это означает, что составной объект можно использовать для того, чтобы передавать целый набор значений как единый объект, и затем применять унификацию для их разделения. Например:
date("April",14,I960)
сопоставляется с X и присваивает X значение date ("April", 14,1960). Также
date("April",14,I960)
сопоставляется с date (Mo, Da, Yr) и присваивает переменным Мо = "April", Da=14 и Yr = 1960.
8. Использование нескольких значений как единого целого
Составные объекты могут рассматриваться в предложениях Пролога как единые объекты, что сильно упрощает написание программ. Рассмотрим, например, факт:
owns(john, book(“From Here to Eternity", "James Jones")).
в котором утверждается, что у Джона есть книга "From Here to Eternity" (Отсюда в вечность), написанная James Jones (Джеймсом Джонсом). Аналогично можно записать:
owns (john, horse (blacky) ) .
что означает:
John owns a horse named blacky.(У Джона есть лошадь Блеки.)
Если вместо этого описать только два факта:
owns (john, "From Here to Eternity"), owns(john, blacky).
то нельзя было бы определить, является ли blacky названием книги или именем лошади.
9. Объявление составных доменовРассмотрим, как определяются составные домены. После компиляции программы, которая содержит следующие отношения:
owns(john, book("From Here to Eternity", "James Jones")).
и
owns (John, horse (blacky) ).
вы можете послать системе запрос в следующем виде:
owns (John, X)
Переменная Х может быть связана с различными типами объектов: книга, лошадь и, возможно, другими объектами, которые вы определите. Отметим, что теперь вы не можете более использовать старое определение предиката owns:
owns (symbol, symbol)
Второй элемент более не является объектом типа symbol. Вместо этого вы можете дать новое определение этого предиката
owns(name, articles)
Домен articles в разделе domains можно описать так
domains
articles = book(title, author); horse(name)
Точка с запятой читается как "или" В этом случае возможны два варианта книга будет определяться своим заглавием и автором, а лошадь будет распознаваться своим именем Домены title, author и name имеют стандартный тип symbol.
К определению домена легко могут быть добавлены другие варианты.
10. Многоуровневые составные объектыVisual Prolog позволяет конструировать составные объекты на нескольких уровнях. Например:
domains
articles = book(title, author);%Первый уровень
author= author(first_name, last_name) %Второй уровень
title, first_name, last_name = symbol%Третий уровень
При использовании составных объектов со многими уровнями часто помогает такое "дерево" (рис. 7):
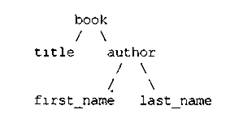
Рис. 7. Дерево многоуровневого составного объекта
Повтор и рекурсия
Компьютеры способны повторять одно и то же действие снова и снова, Visual Prolog может выражать повторение как в процедурах, так и в структурах данных. Идея повторяющихся структур данных может показаться странной, но Пролог позволяет создавать структуры данных, размер которых не известен во время создания.
11. Процесс повторенияПрограммисты на языках Pascal, Basic или С, которые начинают использовать Visual Prolog, часто испытывают разочарование, обнаружив, что язык не имеет конструкций for, while или repeat. В Прологе не существует прямого способа выражения повтора. Пролог обеспечивает только два вида повторения
· откат, с помощью которого осуществляется поиск многих решений в одном запросе,
· и рекурсию, в которой процедура вызывает сама себя.
Однако этот недостаток не снижает мощи Пролога. Фактически, Visual Prolog распознает специальный случай рекурсии — хвостовую рекурсию — и компилирует ее в оптимизированную итерационную петлю. Это означает, что хотя программная логика и выражается рекурсивно, скомпилированный код так же эффективен, как если бы программа была написана на Pascal или Basic.
Использование поиска с возвратом для организации повторовКогда выполняется процедура поиска с возвратом (откат), происходит поиск другого решения целевого утверждения. Это осуществляется путем возврата к последней из проверенных подцелей, имеющей альтернативное решение, использования следующей альтернативы этой подцели и новой попытки движения вперед (см. пример ch06e01). Очень часто для этого используется директива fail.
predicates
country(symbol)
print_countries
clauses
country("England").
country("France").
country("Germany").
country("Denmark").
print_countries:-
country(X),
write(X),% записать значение Х
nl,% начать новую строку
fail.
print_countries.
goal
print__countnes.
Рис. 8. Программа ch06e01.pro
Предварительные и последующие операции
Отметим, что программа, которая находит решения для целевого утверждения, может выполнять какие-либо предварительные или завершающие операции. Например, в нашем примере программа могла бы:
1. Напечатать
Some delightful places to live are... (Некоторые восхитительные места для проживания...).
2. Напечатать все решения для country (X).
3. Завершить печать фразой And maybe others (Могут быть и другие).
Заметьте, что print_countries, определенное в предыдущем примере, уже содержит предложение вывести на печать все решения country (X) и отпечатать завершающее сообщение.
Первое предложение для print_countries соответствует шагу 2 и выводит на печать все решения. Его второе предложение соответствует шагу 3 и просто успешно завершает целевое утверждение (потому что первое предложение всегда в режиме fail — "неудачное завершение").
Можно было бы изменить второе предложение в программе ch06e01.pro.
print_countnes :-
write("And maybe others."), nl.
которое выполнило бы шаг 3, как указано.
А что можно сказать о шаге 1? В нем нет смысла, когда print_countnes содержал только 2 предложения. Но в предикате может быть и три предложения:
print_countries :-
write("Some delightful places to live are"), nl,
fail.
pnnt_countnes :-
country(X),
write(X),nl,
fail.
print_countries :-
write("And maybe others."), nl.
Наличие fail в первом предложении важно, поскольку он обеспечивает после выполнения первого предложения возврат и переход ко второму предложению Кроме того, это важно, потому что предикаты write и nl не образуют альтернатив Строго говоря, первое предложение проверяет все возможные решения перед тем, как завершиться неуспехом.
Такая структура из трех предложений более удобна по сравнению с общепринятым подходом.
Использование отката с петлямиПоиск с возвратом является хорошим способом определить все возможные решения целевого утверждения Но, даже если ваша задача не имеет множества решений, можно использовать поиск с возвратом для выполнения итераций Просто определите предикат с двумя предложениями
repeat
repeat - repeat
Этот прием демонстрирует создание структуры управления Пролога (см листинг на рис. 2.), которая порождает бесконечное множество решений. Цель предиката repeat — допустить бесконечность поиска с возвратом (бесконечное количество откатов)
/* Использование repeat для сохранения введенных символов и печатать их до тех пор, пока пользователь не нажмет Enter (Ввод)*/
predicates
repeat
typewriter
clauses
repeat.
repeat -repeat.
typewriter :-
repeat,
readchar(C),% Читать символ, его значение присвоить С
write(С),
С = '\r',% Символ возврат каретки (Enter)? или неуспех
goal
typewriter (), nl.
Рис. 9. Листинг 13.2. Программа ch06e02.pro
Программа ch06e02 pro показывает, как работает repeat Правило typewriter - описывает процесс приема символов с клавиатуры и отображения их на экране, пока пользователь не нажмет клавишу <Enter> (<Return>)
Правило typewriter работает следующим образом
1 Выполняет repeat (который ничего не делает, но ставит точку отката).
2 Присваивает переменной с значение символа.
3 Отображает С.
4 Проверяет, соответствует ли с коду возврата каретки.
5 Если соответствует, то — завершение. Если нет — возвращается к точке отката и ищет альтернативы, так как ни write, ни readchar не являются альтернативами,
12. Рекурсивные процедуры Понятие рекурсии
Одним из способов организации повторений — рекурсия. Рекурсивная процедура — это процедура, которая вызывает сама себя. В рекурсивной процедуре нет проблемы запоминания результатов ее выполнения, потому что любые вычисленные значения можно передавать из одного вызова в другой как аргументы рекурсивно вызываемого предиката.
Логика рекурсии проста для осуществления. Представьте себе ЭВМ, способную "понять":
Найти факториал числа N:
Если N равно 1, то факториал равен 1
Иначе найти факториал N-1 и умножить его на N.
Этот подход означает следующее:
первое («закручиваете» стек), чтобы найти факториал 3, вы должны найти факториал 2, а чтобы найти факториал 2, вы должны вычислить факториал 1. факториал 1 ищется без обращения к другим факториалам, т.к. он равен 1, поэтому повторения не начнутся.
второе («раскручиваете» стек), если у вас есть факториал 1, то умножаете его на 2, чтобы получить факториал 2, а затем умножаете полученное на 3, чтобы получить факториал 3.
Информация хранится в области памяти, называемой стековым фреймом (stack frame) или просто стеком (stack), который создается каждый раз при вызове правила. Когда выполнение правила завершается, занятая его стековым фреймом память освобождается (если это не недетерминированный откат), и выполнение продолжается в стековом фрейме правила-родителя.
Преимущества рекурсииРекурсия имеет три основных преимущества:
· она может выражать алгоритмы, которые нельзя удобно выразить никаким другим образом;
· она логически проще метода итерации;
· она широко используется в обработке списков.
Рекурсия — хороший способ для описания задач, содержащих в себе подзадачу такого же типа. Например, поиск в дереве (дерево состоит из более мелких деревьев) и рекурсивная сортировка (для сортировки списка, он разделяется на части, часть сортируются и затем объединяются вместе).
Логически рекурсивным алгоритмам присуща структура индуктивного математического доказательства. Приведенная выше рекурсивная программа вычисления факториала описывает бесконечное множество различных вычислений с помощью всего лишь двух предложений. Это позволяет легко увидеть правильность этих предложений. Кроме того, правильность каждого предложения может быть изучена независимо от другого.
Пример рекурсивного определения правилДавайте добавим к программе о родственных связях еще одно отношение - предок. Определим его через отношение родитель. Все отношение можно выразить с помощью двух правил. Первое правило будет
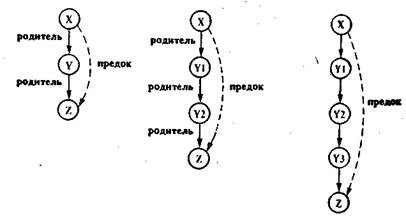
определять непосредственных (ближайших) предков, а второе - отдаленных. Будем говорить, что некоторый X является отдаленным предком некоторого Z, если между X и Z существует цепочка людей, связанных между собой отношением родитель-ребенок, как показано на рис.1.. В нашем примере на рис. 1. Том - ближайший предок Лиз и отдаленный предок Пат.
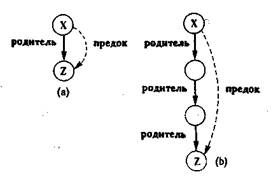
Рис. 10. Пример отношения предок:(а) X - ближайший предок Z; (b) X - отдаленный предок Z.
Первое правило простое и его можно сформулировать так:
Для всех X и Z,
X - предок Z, если X - родитель Z.
Это непосредственно переводится на Пролог как
предок( X, Z) :.-родитель( X, Z).
Второе правило сложнее, поскольку построение цепочки отношений родитель может вызвать некоторые трудности. Один из способов определения отдаленных родственников мог бы быть таким, как показано на рис. 2. В соответствии с ним отношение предок определялось бы следующим множеством предложений:
предок( X, Z) :-
родитель( X, Z).
предок( X, Z) :-
родитель( X, Y), родитель( Y, Z).
предок( X, Z) :-
родитель( X, Y1),
родитель( Y1, Y2),
родитель( Y2, Z).
предок (X, Z) :-
родитель( X, Y1),
родитель( Y1, Y2),
родитель( Y2, Y3),
родитель( Y3, Z).
Рис. 11. Пары предок-потомок, разделенных разным числом поколений.
Эта программа длинна и, что более важно, работает только в определенных пределах. Она будет обнаруживать предков лишь до определенной глубины фамильного дерева, поскольку длина цепочки людей между предком и потомком ограничена длиной наших предложений в определении отношения.
Существует, однако, корректная и элегантная формулировка отношения предок - корректная в том смысле, что будет работать для предков произвольной отдаленности. Ключевая идея здесь - определить отношение предок через него самого. Рис. 3 иллюстрирует эту идею:
Для всех X и Z,
X - предок Z, если существует Y, такой, что
(1) X - родитель Y и
(2) Y - предок Z.
Предложение Пролога, имеющее тот же смысл, записывается так:
предок( X, Z) :-
родитель ( X, Y), предок( Y, Z).
Теперь мы построили полную программу для отношения предок, содержащую два правила: одно для ближайших предков и другое для отдаленных предков. Здесь приводятся они оба вместе:
предок( X, Z) :-
родитель( X, Z).
предок( X, Z) :-
родитель( X, Y),
предок( Y, Z).
Рис. 12.
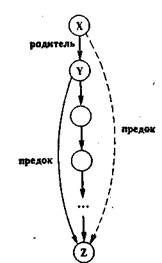 |
Рекурсивная формулировка отношения предок.
Ключевым моментом в данной формулировке было использование самого отношения предок в его определении. Такие определения называются рекурсивными. Логически они совершенно корректны и понятны. Рекурсия - один из фундаментальных приемов программирования на Прологе. Без рекурсии с его помощью невозможно решать задачи сколько-нибудь ощутимой сложности.
Оптимизация хвостовой рекурсииУ рекурсии есть один большой недостаток — она «съедает» память. Всякий раз, когда одна процедура вызывает другую, информация о выполнении вызывающей процедуры должна быть сохранена для того, чтобы она (вызывающая процедура) могла, после выполнения вызванной процедуры, возобновить выполнение на том же месте, где остановилась. Это означает, что если процедура вызывает себя 100 раз, то 100 различных состояний должно быть записано одновременно (состояния выполнения решения сохраняются в стековом фрейме). Максимальный размер стека у 16-битных платформ, таких как IBM PC, работающая под DOS, составляет 64 Кбайт, что позволяет разместить максимум 3000 или 4000 стековых фреймов. На 32-битных платформах стек теоретически может возрасти до нескольких гигабайт; но здесь проявятся другие системные ограничения, прежде чем стек переполнится. Что же можно сделать, чтобы избежать использования столь большого стекового пространства?
Рассмотрим специальный случай, когда процедура может вызвать себя без сохранения информации о своем состоянии. Что, если вызывающая процедура не собирается возобновлять свое выполнение после завершения вызванной процедуры?
Предположим, что процедура вызывается последний раз, т. е. когда вызванная процедура завершит работу, вызывающая процедура не возобновит свое выполнение. Это значит, что вызывающей процедуре не нужно сохранять свое состояние, потому что эта информация уже не понадобится. Как только вызванная процедура завершится, работа процессора должна идти в направлении, указанном для вызывающей процедуры после ее выполнения.
Например, допустим, что процедура А вызывает процедуру В, а В — С в качестве своего последнего шага. Когда В вызывает С, В не должна больше ничего делать. Поэтому, вместо того чтобы сохранить в стеке процедуры В информацию о текущем состоянии С, мы можем переписать старую сохраненную информацию о состоянии В (которая больше не нужна) на текущую информацию о С, сделав соответствующие изменения в хранимой информации. Когда С закончит выполнение, она будет считать, что она вызвана непосредственно процедурой А.
Предположим, что на последнем шаге выполнения процедура В вместо процедуры С вызывает себя. Получается, что когда В вызывает В, стек (состояние) для вызывающей в должен быть заменен стеком для вызванной В. Это очень простая операция, просто аргументам присваиваются новые значения и затем выполнение процесса возвращается на начало процедуры В. Поэтому, с процедурной точки зрения, происходящее очень похоже на всего лишь обновление управляющих переменных в цикле
Эта операция называется оптимизацией хвостовой рекурсии (tail recursion optimization) или оптимизацией последнего вызова (last-call optimization) Обратите внимание, что по техническим причинам оптимизация последнего вызова неприменима к рекурсивным функциям.
Как задать хвостовую рекурсиюЧто означает фраза "одна процедура вызывает другую, выполняя свои самый последний шаг"? На языке Пролог это значит.
П вызов является самой последней подцелью предложения,
О ранее в предложении не было точек возврата
Ниже приводится удовлетворяющий обоим условиям пример
count (N) : -write(N), nl, NewN = N+l, count(NewN) .
Эта процедура является хвостовой рекурсией, которая вызывает себя без резервирования нового стекового фрейма, и поэтому не истощает запас памяти Как показывает программа ch06e04 pro (листинг 13 4), если вы дадите ей целевое утверждение
count (0) .
то предикат count будет печатать целые числа, начиная с 0, и никогда не остановится В конечном счете произойдет целочисленное переполнение, но остановки из-за истощения памяти не произойдет
Листинг 13.4. Программа ch06e04.pro
/* Программа с хвостовой рекурсией, которая не истощает память */ predicates count(ulong)
clauses
count(N):-
write('\r',N), NewN = N+l, count(NewN).
GOAL nl, count(0).
13. Определение спискаВ Прологе список — это объект, который содержит конечное число других объектов. Списки можно грубо сравнить с массивами в других языках, но, в отличие от массивов, для списков нет необходимости заранее объявлять их размер.
Список, содержащий числа 1, 2 и 3, записывается так:
[1, 2, 3]
Каждая составляющая списка называется элементом. Чтобы оформить списочную структуру данных, надо отделить элементы списка запятыми и заключить их в квадратные скобки. Вот несколько примеров:
[dog, cat, canary]
["valerie ann", "jennifer caitlin", "benjamin thomas"]
14. Объявление списковЧтобы объявить домен для списка целых, надо использовать декларацию домена, такую как:
domains
integerlist = integer*
Символ (*) означает "список чего-либо"; таким образом, integer* означает "список целых".
Элементы списка могут быть любыми, включая другие списки. Однако все его элементы должны принадлежать одному домену. Декларация домена для элементов должна быть следующего вида:
domains
elementlist = elements*
elements = ....
Здесь elements имеют единый тип (например: integer, real или symbol) или являются набором отличных друг от друга элементов, отмеченных разными функторами. В Visual Prolog нельзя смешивать стандартные типы в списке. Например, следующая декларация неправильно определяет список, составленный из элементов, являющихся целыми и действительными числами или идентификаторами:
elementlist = elements*
elements = integer; real; symbol/* Неверно */
Чтобы объявить список, составленный из целых, действительных и идентификаторов, надо определить один тип, включающий все три типа с функторами, которые покажут, к какому типу относится тот или иной элемент. Например:
elementlist = elements*
elements = i(integer); r(real); s(symbol)% функторы здесь i,r и s
15. Головы и хвостыСписок является рекурсивным составным объектом. Он состоит из двух частей — головы, которая является первым элементом, и хвоста, который является списком, включающим все последующие элементы. Хвост списка — всегда список, голова списка — всегда элемент. Например:
голова [а, b, с] есть а
хвост [а, b, с] есть [b, с]
Что происходит, когда вы доходите до одноэлементного списка? Ответ таков:
голова [с] есть с
хвост [с] есть []
Если выбирать первый элемент списка достаточное количество раз, вы обязательно дойдете до пустого списка []. Пустой список нельзя разделить на голову и хвост.
В концептуальном плане это значит, что список имеет структуру дерева, как и другие составные объекты. Структура дерева [а, b, с, d] представлена на рис. 1.
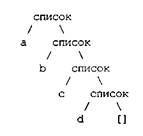
Рис. 1. Структура дерева
Одноэлементный список, как, например [а], не то же самое, что элемент, который в него входит, потому что [а] на самом деле — это составная структура данных.
16. Работа со спискамиВ Прологе есть способ явно отделить голову от хвоста. Вместо разделения элементов запятыми, это можно сделать вертикальной чертой "|". Например:
[а, b, с] эквивалентно [а| [b, с]] и, продолжая процесс,
[а| [b, с] ] эквивалентно [а| [b| [с] ]], что эквивалентно [а| [b| [с| [] ] ] ]
Можно использовать оба вида разделителей в одном и том же списке при условии, что вертикальная черта есть последний разделитель. При желании можно набрать
[а, b, с, d] как [а, b|[с, d]].
В табл. 1. приведены несколько примеров на присвоение в списках.
Таблица 1. Присвоение в списках
| Список 1 | Список 2 | Присвоение переменным |
| [X, Y, Z] | [эгберт, ест, мороженое] | Х=эгберг, У=ест, Z=мороженое |
| [7] | [X | Y] | Х=7, Y=[] |
| [1, 2, 3, 4] | [X, Y | Z] | X=l, Y=2, Z=[3,4] |
| [1, 2] | [3 | X] | fail% неудача |
Список является рекурсивной составной структурой данных, поэтому нужны алгоритмы для его обработки. Главный способ обработки списка — это просмотр и обработка каждого его элемента, пока не будет достигнут конец.
Алгоритму этого типа обычно нужны два предложения. Первое из них говорит, что делать с обычным списком (списком, который можно разделить на голову и хвост), второе — что делать с пустым списком.
18. Печать списковЕсли нужно напечатать элементы списка, это делается так, как показано в листинге 1.
Листинг 1. Программа ch07e01.pro;
domains
list = integer*% Или любой тип, какой вы хотите
predicates
write_a_list(list)
clauses
write_a_list([ ]),% Если список пустой — ничего не делать
write_a_list([Н|Т]):-% Присвоить Н-голова,Т-хвост, затем...
write(H),nl,
write_a_list(Т).
goal
write_a_list([1, 2, 3]).
Вот два целевых утверждения write_a_list, описанные на обычном языке:
Печатать пустой список — значит ничего не делать.
Иначе, печатать список — означает печатать его голову (которая является одним элементом), затем печатать его хвост (список) .
19. Подсчет элементов списка
Рассмотрим, как можно определить число элементов в списке. Что такое длина списка? Вот простое логическое определение:
Длина [] — 0.
Длина любого другого списка — 1 плюс длина его хвоста.
Можно ли применить это? В Прологе — да. Для этого нужны два предложения (листинг 2).
Листинг 2. Программа ch07e02.pro
domains
list = integer*
predicates
length_of(list,integer)
clauses
length_of ( [ ] , 0).
length_of ( [ _|T],L) :-
length_of(T,TailLength),
L = TailLength + 1.
Посмотрим сначала на второе предложение. Действительно, [_|T] можно сопоставить любому непустому списку, с присвоением т хвоста списка. Значение головы не важно, главное, что оно есть, и компьютер может посчитать его за один элемент.
Таким образом, целевое утверждение
length_of([1, 2, 3], L).
подходит второму предложению при T=[2, 3]. Следующим шагом будет подсчет длины T. Когда это будет сделано (не важно как), TailLength будет иметь значение 2, и компьютер добавит к нему 1 и затем присвоит L значение 3.
Итак, как компьютер выполнит промежуточный шаг? Это шаг, в котором определяется длина [2, 3] при выполнении целевого утверждения
length_of([2, 3], TailLength).
Другими словами, length_of вызывает сама себя рекурсивно.
[1] Имеются и другие стандартные домены.
Похожие работы

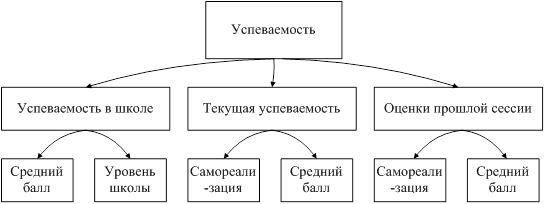
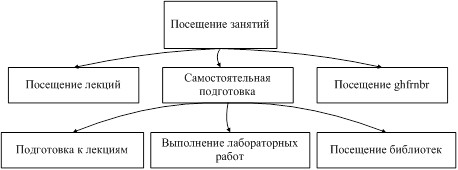
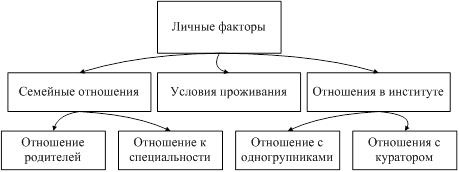
... отдаетесь учебе? YTS · Yes · No На основе этих данных построим базу знаний продукционной модели с помощью простой конструкции : Если (условие), то (действие), Набор правил для экспертной системы прогнозирования сдачи сессии студентами на основании текущей успеваемости: 3. If LIO=”Yes” and LIK=”Yes” then LI = “Yes” 4. If LIO=”Yes” and LIK=”No” then LI = “Yes” 5. If LIO=”No” ...

... названием "Prolog", а внутри него ярлык на файл "Prolog.exe" с названием "Prolog with databases", ярлык на help-файл и на файл "readme.txt". 3.3 Руководство пользователя программы интерпретатора языка Пролог 3.3.1 Запуск программы Запуск программы можно произвести несколькими способами. Нажать кнопку "Пуск", выбрать в меню пункт "Программы", выбрать пункт "Prolog". После того, как ...
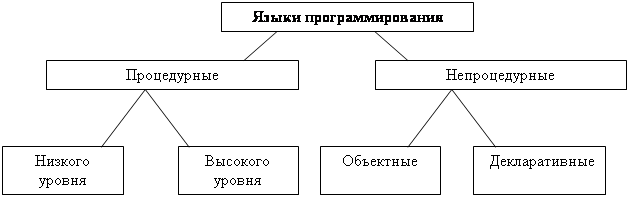
... проектирование и программирование 0.8 Структурное проектирование включает в себя: - нисходящее проектирование ("сверху вниз"), - модульное программирование, - структурное программирование. 0.8.1.Нисходящее проектирование Метод предполагает последовательное разложение функции обработки данных на простые функциональные элементы ("сверху ...

... набор процедур и функций языков программирования Basic и Pascal, позволяют управлять графическим режимом работы экрана, создавать разнооборазные графические изображения и выводить на экран текстовые надписи. ГЛАВА 2. ГРАФИЧЕСКИЕ ВОЗМОЖНОСТИ ЯЗЫКА ПРОГРАММИРОВАНИЯ В КУРСЕ ИНФОРМАТИКИ БАЗОВОЙ ШКОЛЫ (НА ПРИМЕРЕ BASIC И PASCAL) 2.1 Разработка мультимедиа курса «Графические возможности языков ...
0 комментариев