Навигация
Разработка подсистемы морфологического анализа информационной системы
71981
знак
11
таблиц
6
изображений
Введение
1. Обзор существующих решений в области разработки подсистемы синтаксического анализа
1.2 Категория 2 (Наборы словарей)
2. Общее описание морфологического анализа слова 2.1 Морфология
2.3 Общее описание морфологического анализа слова


В данном дипломном проекте ставится задача разработки алгоритмов морфологического анализа. В ходе выполнения проекта был проведен анализ существующих решений в сфере программных продуктов проверки орфографии. Был проведен анализ правил русского языка, которые используются при машинном анализе текста.
Алгоритмы спроектированы с учетом возможности их интеграции в существующие программные решения. Также алгоритмы дополняемы и расширяемы. Алгоритмы построены согласно ГОСТ 19.701–90.
1. Обзор существующих решений в области разработки подсистемы синтаксического анализа
Присутствующие сегодня на рынке программных продуктов системы проверки орфографии можно поделить на несколько условных категорий.
1.1 Категория 1 (Готовые программные комплексы)В стандартную версию MS Office обычно входят лингвистические средства для проверки нескольких языков, но не всех. Например, в английской версии – это английский, французский и испанский, в MS Office с русской локализацией – русский, украинский и английский. Системы проверки орфографии обычно поддерживают одновременную проверку правописания гораздо большего количества языков.
В продукты корпорации Microsoft с локализацией, отличной от русской, поддержка русского языка не входит. В некоторых иностранных фирмах в России, в соответствии с требованиями головного офиса, на компьютерах установлены нелокализованные версии текстовых процессоров, однако ведение части документации и переписка с российскими клиентами осуществляются на русском языке.
Большинство отдельных продуктов обладают рядом дополнительных опций, которые могут быть необходимы тем или иным специалистам, даже имеющим русские локализованные версии MS Office, а именно:
− проверка орфографии в программах, где эта функция не реализована разработчиком. Это особенно актуально для профессиональных полиграфистов, использующих такие популярные программы верстки, как PageMaker, QuarkXPress и MS Excel;
− дополнительные словари по предметным областям (техника, гуманитарные и точные науки, медицина, коммерция и др.);
− постоянное пополнение словаря новой лексикой. В MS Office XP встроен словарь 2000 года, а в более ранние версии – словарь 1996 года;
− проверка орфографии практически в любых окнах, в которых возможен ввод текста. Например, в почтовых и коммуникационных программах (в частности, в ICQ);
− толковые словари русского языка. в случае сомнений в правильности выбора какого-либо слова можно обратиться к этому словарю, который обычно содержит сотни тысяч слов;
− грамматический справочник русского языка, который содержит свод правил русской орфографии и пунктуации с примерами употребления;
− поддержка удобного формата словарей пользователя. Новое слово не придется добавлять в словарь всякий раз, как оно встретится в другой форме, поскольку слова включаются в словарь сразу со всеми словоформами;
− словари пользователя – общие для всех приложений, для которых установлена поддержка системы проверки орфографии. При работе с текстами в различных приложениях новые слова, занесенные в словарь в одном приложении, будут затем считаться правильными и в других;
− поиск и замена русских слов во всех словоформах. даже в локализованной русской версии MS Word встроенные поиск и замена во всех формах реализованы только для английского языка;
− автоматическое составление реферата. Полезная функция для тех, кто стремится создать хорошо структурированные тексты. Можно получить «выжимку» из своего текста заданного объема и составить список ключевых слов. В MS Word даже в локализованной русской версии встроенный автореферат реализован только для английского языка;
− проверка орфографии для других языков: английского, испанского, немецкого, украинского и французского;
− расстановка переносов в текстах с регулируемым уровнем качества. Можно выбирать «книжное» качество для обычных текстов или «газетное» при форматировании текста в узкие колонки.
Эти недостатки можно устранить с помощью различного ПО, например, с помощью Microsoft Office 2003 Multilingual User Interface Pack, систем проверки офрграфии, таких как «Орфо» и «Рута».
Microsoft Office 2003 Multilingual User Interface PackMicrosoft Office 2003 Multilingual User Interface Pack дополняет уже встроенные в Microsoft Office средства многоязыковой поддержки, предоставляя переведенный текст для интерфейса пользователя, справки, мастеров и шаблонов приложений Microsoft Office. С помощью пакета Office 2003 MUI Pack можно работать в версии Microsoft Office на английском языке, но при этом просматривать команды, параметры диалоговых окон, разделы справки, мастера и шаблоны на знакомом языке.
В пакет Microsoft Office 2003 MUI Pack также входят средства проверки правописания Microsoft Office 2003 Proofing Tools, куда включены шрифты, средства проверки орфографии и грамматики, списки автозамены и другие инструменты, помогающие в создании и редактировании файлов Microsoft Office на выбранном языке.
Смена языка интерфейса пользователя или справочной системы распространяется на все приложения Microsoft Office. Смена языка интерфейса пользователя не оказывает влияния на формат сохраняемых файлов Microsoft Office или какого-либо другого воздействия на приложения. Конвертер для открытия файлов не потребуется. Некоторые компоненты Microsoft Office не поддерживают смену языка интерфейса пользователя или справочной системы.
Office 2003 MUI Pack работает с Microsoft Office в операционной системе Microsoft Windows 2000 или более поздней версии. Microsoft Windows 2000 обеспечивает наиболее полную поддержку для большинства языков и рекомендуется при постоянной работе с несколькими языками.
Пакет Microsoft Office 2003 MUI Pack MUI Pack распространяется на компакт-диске и имеет свою собственную программу установки.
Microsoft Proofing ToolsПакет средств проверки правописания Microsoft Office 2003 Proofing Tools – это отдельный дополнительный продукт, содержащий средства, созданные корпорацией Майкрософт для более чем 30 языков, такие как шрифты, средства проверки орфографии и грамматики, списки автозамены, правила составления авторефератов (только для Microsoft Word), двуязычные словари, а также редакторы способов ввода IME. IME – программа, обеспечивающая ввод текста на восточноазиатских языках (китайский с традиционным письмом, китайский с упрощенным письмом, японский и корейский) в приложениях путем преобразования нажатий клавиш в сложные знаки этих языков. IME рассматривается как дополнительный вид раскладки клавиатуры (для азиатских языков).
«Орфо»«Орфо» – это система, предназначенная для проверки и исправления правописания текстов на семи языках. Компания-разработчик системы «Орфо» предлагает несколько вариантов комплектации:
Базовый комплект программы «Орфо»Для проверки текстов только на русском языке.
− Проверка орфографии:
· в популярных программах;
· в собственном редакторе;
· в большинстве редактируемых окон по «горячим клавишам»;
− Расстановка переносов,
− Добавление нового слова сразу во всех его формах,
− Единый морфологический словарь пользователя для всех поддерживаемых приложений (рис 1.1, 1.2),
− Возможность просмотра всех форм заданного слова и его грамматических характеристик.
По сравнению с модулем проверки орфографии русского языка в MS Office, в «Орфо» имеется возможность добавления слов во всех словоформах и показ всех форм любого слова с его грамматическими характеристиками.
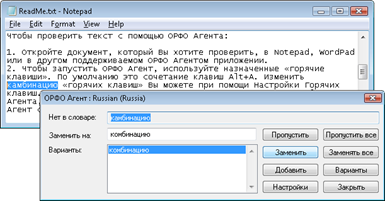
Рис. 1.1. Взаимодействие программ «Орфо» и Notepad
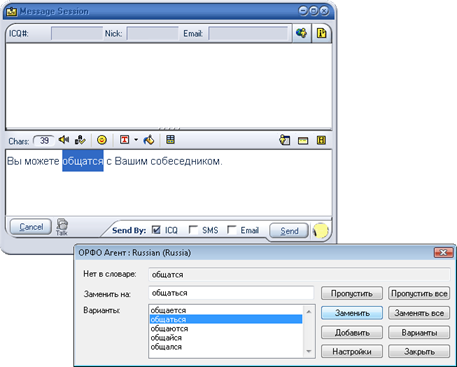
Рис. 1.2. Взаимодействие программ «Орфо» и ICQ
Профессиональный комплект программы «Орфо»Для проверки текстов только на русском языке.
− Проверка орфографии.
Проверка орфографии осуществляется: в популярных программах, в собственном редакторе и в большинстве редактируемых окон по «горячим клавишам» (рис. 1.3, 1.4).
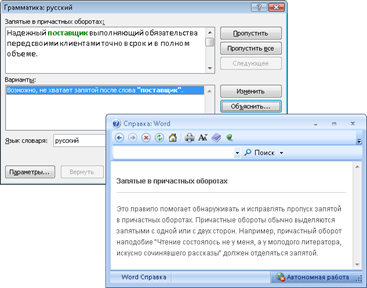
Рис. 1.3. Проверка орфографии и подсказки в программе «Орфо»

Рис. 1.4. Проверка орфографии и подсказки в программе «Орфо»
− Грамматическая и стилистическая проверка.
Усовершенствованный грамматический и стилистический корректор использует более 40 групп правил и проверяет текст с точки зрения трех основных стилей письма: строго (все правила), для деловой переписки и для обычной переписки.
− Словарь синонимов, антонимов и родственных слов.
Словарь синонимов русского языка включает более 60 000 русских слов и выражений, образующих около 10 000 групп синонимов, 3 500 антонимов и 14 000 рядов родственных слов. Словарь синонимов располагает двумя возможностями: он распознает русские слова независимо от их формы в тексте и для любого слова предлагает синоним или антоним в соответствующей грамматической форме.
− Расстановка переносов.
Полная расстановка переносов с возможностью пользователю выбрать качество переноса – книжное или газетное.
− Набор толковых словарей «Русская коллекция»
Весь спектр русских словарей, объединенных в набор Русская коллекция: Толковый словарь современного языка, Толковый словарь В. Даля, Синонимы, Антонимы, Паронимы, Этимологический словарь.
− Показ всех форм заданного слова и его грамматических характеристик.
− Справочник по русскому языку, который содержит свод правил русской орфографии и пунктуации.
− Для Microsoft Word предусмотрена возможность поиска и замены слов во всех формах, создание автореферата документа и формирование списка его ключевых слов (рис 1.5).
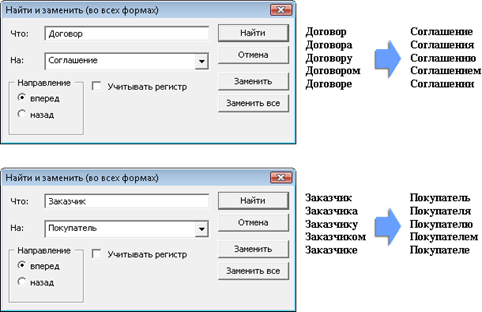
Рис. 1.5. Возможность поиска и замены слов в программе «Орфо»
Для более эффективной проверки орфографии предусмотрена возможность подключения дополнительных тематических словников по предметным областям (информационные технологии, коммерция, нефть и газ, техника, гуманитарные и точные науки, медицина и т.п.)
Дополнительные словники к программе «Орфо»Для Профессионального и Многоязычного комплектов «Орфо».
Для более качественной проверки орфографии в Профессиональном и / или Многоязычном комплектах предусмотрена возможность подключения дополнительных тематических словников по предметным областям.
− Строительный (для русского языка). Содержит термины по различным отраслям строительного дела.
− Нефть и газ (для русского языка). Содержит термины, относящиеся к геологии, добыче и хранению нефти и газа, строительству, обслуживанию скважин, разработке месторождений и соответствующему оборудованию.
− Информационные технологии (для русского языка). Словарь содержит термины по вычислительным системам и сетям, архитектуре и элементам вычислительных машин, операционным системам, программному обеспечению.
− Словник по бизнесу (для русского, английского и немецкого языка). Содержит термины по бизнесу, бухучету, финансам и праву.
− Медицинский словник (для русского, английского, немецкого и испанского языка). Содержит термины по медицинской науке и практике.
− Научный словник (для русского и английского языка). Содержит термины из области математики, физики, химии, биологии, лингвистики.
− Технический словник (для русского и английского языка). Содержит термины по различным отраслям науки и техники (машиностроение, радиоэлектроника, автомобилестроение, авиационная и ракетно-космическая техника, пищевая и парфюмерная промышленность и т.д.)
− Гуманитарный словник (для русского и английского языка). Содержит термины из области культуры, религии, политики, музыки, психологии.
Приложения, поддерживаемые программой «Орфо»Приложения, поддерживаемые программой «Орфо», с учетом версий приложений и языков, приведены в таблице 1.1.
Таблица 1.1. Приложения, поддерживаемые программой «Орфо»
| Приложение | Орфография | Грамматика и стиль | Синонимы | Расстановка переносов | Русская коллекция |
| MS Word 97/2000/XP/2003/2007 | Все языки | Русский | Русский | Русский, | Русский |
| MS Access 97/2000/XP/2003/2007 | Все языки | ||||
| MS Excel 97/2000/XP/2003/2007 | Все языки | ||||
| MS PowerPoint 97/2000/XP/2003/2007 | Все языки | ||||
| MS FrontPage 2000/XP/2003 | Все языки | Русский | |||
| MS InfoPath 2003/2007 | Все языки | ||||
| MS Outlook 97–98/2000/XP/2003/2007 | Все языки | ||||
| MS Outlook Express 4.x/5.x/6.x | Все языки | ||||
| MS Publisher 98/2000 | Все языки | ||||
| MS Publisher XP/2003/2007 | Все языки | Русский | Русский, | ||
| MS Works 4.x | Все языки | Русский | |||
| MS Internet Explorer 6.x | Все языки | ||||
| Opera 9.x | Все языки | ||||
| Mozilla FireFox 2.x | Все языки | ||||
| Adobe PageMaker 6.x/7.0 | Все языки | Русский, | |||
| Lotus WordPro 96/97/2000 | Все языки | ||||
| Corel WordPerfect 7.0/8.0 | Все языки | Русский, | |||
| Corel WordPerfect 9.0 | Все языки | ||||
| QuarkXPress 4.x/5.x | Все языки | Русский, | |||
| ОРФО Редактор | Все языки | Русский | Русский | Русский, | Русский |
| ОРФО Агент | Все языки |
В таблице 1.1 указано, в каких приложениях и для каких языков поддерживаются предлагаемые опции:
«Все языки» означает, что данная опция реализована для всех встроенных в ОРФО языков в зависимости от приобретенной версии;
«Русский» – для русского;
«Украинский» – для украинского.
1.2 Категория 2 (Наборы словарей)
К этой категории отнесены библиотеки для проверки орфографии.
HunspellHunspell – это формат словарей Hunspell и файлов аффиксов.
Для проверки орфографии Hunspell требуется два файла. Первый файл – словарь, содержащий слова, второй – файл аффиксов, который определяет значения специальных меток (флагов) в словаре.
Файл словаря (.dic) содержит список слов, по одному слову в строке. В первой строке словарей (за исключением персональных словарей) указывается приблизительное количество слов в словаре (для оптимального распределения памяти). После каждого слова может следовать слэш («/») и один или более флагов, соответствующих аффиксам и атрибутам. Слова в словаре также могут содержать слэши, экранированные «». По умолчанию, флаг представляет собой один (обычно, алфавитный) символ. В файле словаря Hunspell также может существовать поле для морфологического описания, отделяемое табуляцией.
Формат морфологического описания определяется пользователем.
Файл аффиксов (.aff) может содержать необязательные атрибуты. Например, SET для определения кодировки символов файлов аффиксов и словаря. TRY определяет заменяемые символы для предлагаемых замен. REP определяет таблицу замен для исправлений нескольких символов. PFX и SFX определяют классы префиксов и суффиксов, обозначенных флагами аффиксов.
Следующий образец файла аффиксов определяет кодировку символов UTF-8. Предлагаемые замены TRY отличаются от неправильного слова на одну букву или апостроф. С помощью этих флагов REP, Hunspell предлагает правильное слово, если вместо f напечатано ph или наоборот.
SET UTF-8
TRY esianrtolcdugmphbyfvkwzESIANRTOLCDUGMPHBYFVKWZ’
REP 2
REP f ph
REP ph f
PFX A Y 1
PFX A 0 re.
SFX B Y 2
SFX B 0 ed [^y]
SFX B y ied y
В этом файле определено 2 класса аффиксов. Класс A определяет префикс re– Класс B – два суффикса – ed: один для слов, оканчивающихся не на y и второй – для оканчивающихся на y. Эти классы аффиксов используются следующим файлом словаря.
В этом случае, правильными словами являются: hello, try, tried, work, worked, rework, reworked.
ruSpellСистема проверки орфографии ruSPELL для Mac OS X.
Компания Apple IMC представляет новый дополнительный сервис для русскоязычных пользователей – ruSPELL, разработанный совместно с компанией ABBYY Software House. Это программа работает под Mac OS X и позволяет проверять орфографию в большинстве программ с которыми рядовой пользователь сталкивается ежедневно. Разработка данного продукта является очередным этапом реализации новой модели бизнеса, ориентированной на конечного заказчика.
Программа ruSPELL разработана для работы под управлением Mac OS X и состоит из двух компонентов: модуля проверки орфографии Russian Spelling for Ms Office и сервиса ABBYYspeller.
Модуль проверки орфографии Russian Spelling for Ms Office предоставляет возможность проверять орфографию русских текстов в следующих программах: Word v.X, Excel v.X, PowerPoint v.X. Каждая из этих программ предоставляет свой собственный диалог Spelling (правописание), с помощью которого можно находить русские слова, написанные с ошибками, создавать и пополнять собственные словари. Сервис проверки орфографии ABBYYspeller предоставляет возможность проверять орфографию русских текстов во всех программах, работающих со стандартным пакетом AppleSpell операционной системы Mac OS X.
2. Общее описание морфологического анализа слова 2.1 Морфология
Морфология (от греч. morphe – форма, logos – учение) – это раздел науки о языке, рассматривающий грамматические формы и грамматические значения частей речи.
Морфология рассматривает отдельные слова, но, в отличие от лексикологии, исследующей лексические значения слов, морфология изучает грамматические свойства слов.
2.2 Классификация частей речи в русском языке
Части речи – это группы слов, объединенных на основе общности их признаков.
Признаки, на основании которых происходит разделение слов на части речи, не однородны для разных групп слов.
Так, все слова русского языка можно разделить на междометия и немеждометные слова. Междометия – это неизменяемые слова, обозначающие эмоции (ах, увы, черт побери), волеизъявления (стоп, баста) или являющиеся формулами речевого общения (спасибо, привет). Особенность междометий заключается в том, что они не вступают с другими словами в предложении ни в какие синтаксические связи, всегда обособлены интонационно и пунктуационно.
Немеждометные слова можно разделить на самостоятельные и служебные. Различие между ними заключается в том, что самостоятельные слова могут выступать в речи без служебных, а служебные без самостоятельных формировать предложение не могут. Служебные слова неизменяемы и служат для передачи формально-смысловых отношений между самостоятельными словами. К служебным частям речи относятся предлоги (к, после, в течение), союзы (и, как будто, несмотря на то что), частицы (именно, только, вовсе не).
Самостоятельные слова могут быть разделены на знаменательные и местоименные. Знаменательные слова называют предметы, признаки, действия, отношения, количество а местоименные слова указывают на предметы, признаки, действия, отношения, количество, не называя их и являясь заместителями знаменательных слов в предложении (ср.: стол – он, удобный – такой, легко – так, пять – сколько). Местоименные слова формируют отдельную часть речи – местоимение.
Знаменательные слова разделяются на части речи с учетом следующих признаков:
1) обобщенное значение,
2) морфологические признаки,
3) синтаксическое поведение (синтаксические функции и синтаксические связи).
Выделяют не менее пяти знаменательных частей речи: имя существительное, имя прилагательное, имя числительное (группа имен), наречие и глагол.
Таким образом, части речи – это лексико-грамматические классы слов, т.е. классы слов, выделенные с учетом их обобщенного значения, морфологических признаков и синтаксического поведения. (Табл. 2.1.)
Таблица 2.1. Знаменательные части речи
| немеждометные слова | междометные | ||||||||
| самостоятельные слова | служебные слова | межд. | |||||||
| знаменательные слова | местоименные | предл. | союз | част. | |||||
| сущ. | прил. | числ. | глаг. | нар. | мест. | ||||
| имена | |||||||||
В комплексе 3 выделяется 10 частей речи, объединяемых в три группы:
1. Самостоятельные части речи:
– существительное,
– прилагательное,
– числительное,
– местоимение,
– глагол,
– наречие.
2. Служебные части речи:
– предлог,
– союз,
– частица.
3. Междометие.
При этом каждая самостоятельная часть речи определяется по трем основаниям (обобщенное значение, морфология, синтаксис), например: существительное – это часть речи, которая обозначает предмет, имеет род и изменяется по числам и падежам, в предложении выполняет синтаксическую функцию подлежащего или дополнения.
Однако значимость оснований при определении состава той или иной части речи различна: если существительное, прилагательное, глагол определяются по большей части по своим морфологическим признакам (говорится, что существительное обозначает предмет, но специально оговаривается, что это такой «обобщенный» предмет), то есть две части речи, выделенных на основании значения, – местоимение и числительное.
В местоимение, как часть речи объединены морфологически и синтаксически разнородные слова, которые «не называют предмета или признака, а указывают на него». Грамматически же, местоимения разнородны, и соотносятся с существительными (я, кто), прилагательными (этот, какой), числительными (сколько, несколько).
В числительное как часть речи объединены слова, которые имеют отношение к числу: обозначают количество предметов или их порядок при счете. При этом грамматические (морфологические и синтаксические) свойства слов типа три и третий различны.
Комплекс 1 (его последние издания) и комплекс 2 предлагают выделять большее число частей речи. Так, причастие и деепричастие в них рассматриваются не как формы глагола, а как самостоятельные части речи. В этих комплексах выделены слова состояния (нельзя, нужно); в комплексе 1 они описываются как самостоятельная часть речи – категория состояния. В комплексе 3 статус этих слов четко не определен. С одной стороны, их описание завершает раздел «Наречие». С другой стороны, про слова состояния сказано, что они «по форме похожи на наречия», из чего, видимо, должно следовать, что наречиями они не являются. Кроме того, в комплексе 2 расширено местоимение за счет включения в него незнаменательных слов, грамматически соотносимых с наречиями (там, зачем, никогда и др.).
Вопрос о частях речи в лингвистике является дискуссионным. Части речи – это результат определенной классификации, зависящей от того, что принять за основание для классификации. Так, в лингвистике существуют классификации частей речи, в основании которых лежит только один признак (обобщенное значение, морфологические признаки или синтаксическая роль). Есть классификации, использующие несколько оснований. Школьная классификация именно такого рода. Количество частей речи в разных лингвистических работах различно и составляет от 4 до 15 частей речи.
В русском языке есть слова, не попадающие ни в одну из частей речи, выделенных школьной грамматической. Это слова-предложения да и нет, вводные слова, не использующиеся в других синтаксических функциях (итак, итого) и некоторые другие слова.
1. Разработка алгоритма морфологического анализаРассматривается ASCII-кодировка для представления кириллических символов. Кодовая таблица Windows-1251. Кириллические символы кодируются числами с 192 по 255 включительно. В таблице 3.2 голубым цветом выделены кириллические символы.
Таблица 3.1. Символы с кодами 128–255 (Кодовая таблица 1251 – MS Windows)
| Код | Символ | Код | Символ | Код | Символ | Код | Символ |
| 128 | Ђ | 160 | 192 | А | 224 | а | |
| 129 | Ѓ | 161 | Ў | 193 | Б | 225 | б |
| 130 | ‚ | 162 | ў | 194 | В | 226 | в |
| 131 | ѓ | 163 | Ј | 195 | Г | 227 | г |
| 132 | « | 164 | ¤ | 196 | Д | 228 | д |
| 133 | … | 165 | Ґ | 197 | Е | 229 | е |
| 134 | † | 166 | ¦ | 198 | Ж | 230 | ж |
| 135 | ‡ | 167 | § | 199 | З | 231 | з |
| 136 | ? | 168 | Ё | 200 | И | 232 | и |
| 137 | ‰ | 169 | © | 201 | Й | 233 | й |
| 138 | Љ | 170 | Є | 202 | К | 234 | к |
| 139 | ‹ | 171 | « | 203 | Л | 235 | л |
| 140 | Њ | 172 | ¬ | 204 | М | 236 | м |
| 141 | Ќ | 173 | - | 205 | Н | 237 | н |
| 142 | Ћ | 174 | ® | 206 | О | 238 | о |
| 143 | Џ | 175 | Ї | 207 | П | 239 | п |
| 144 | ђ | 176 | ° | 208 | Р | 240 | р |
| 145 | ‘ | 177 | ± | 209 | С | 241 | с |
| 146 | ’ | 178 | І | 210 | Т | 242 | т |
| 147 | « | 179 | і | 211 | У | 243 | у |
| 148 | » | 180 | ґ | 212 | Ф | 244 | ф |
| 149 | • | 181 | μ | 213 | Х | 245 | х |
| 150 | – | 182 | ¶ | 214 | Ц | 246 | ц |
| 151 | – | 183 | · | 215 | Ч | 247 | ч |
| 152 | _ | 184 | ё | 216 | Ш | 248 | ш |
| 153 | ™ | 185 | № | 217 | Щ | 249 | щ |
| 154 | љ | 186 | є | 218 | Ъ | 250 | ъ |
| 155 | › | 187 | » | 219 | Ы | 251 | ы |
| 156 | њ | 188 | ј | 220 | Ь | 252 | ь |
| 157 | ќ | 189 | Ѕ | 221 | Э | 253 | э |
| 158 | ћ | 190 | ѕ | 222 | Ю | 254 | ю |
| 159 | џ | 191 | ї | 223 | Я | 255 | я |
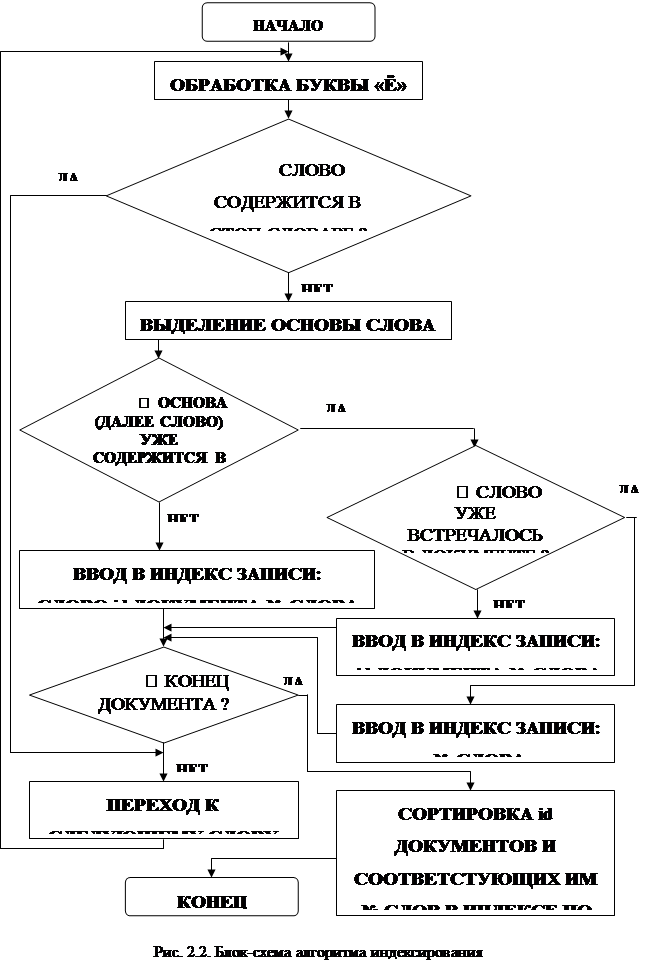
Алгоритм морфологического разбора состоит из двух частей:
1) Поиск слова в словаре.
2) В случае, если слово не найдено, производится попытка найти в этом слове ошибку.
На первом этапе используется словарь, состоящий из основ слов с префиксами и соответствующих этой основе окончаний. Поиск производится перебором. Одной словоформе может соответствовать много морфологических интерпретаций. Например, у словоформы стали две интерпретации:
· {СТАЛЬ, C, «но», («жр, ед, рд», «жр, ед, дт», «жр, мн, им», «жр, мн, вн»)};
· {СТАТЬ, Г, «нп, св», («мн, дст, прш»)}.
Второй этап выполняется, если слово не было найдено в словаре. В таком случае подразумевается, что слово содержит ошибку, и подсистема пытается определить, в каком месте слова допущена ошибка.
Если и на втором этапе не удалось найти словоформу, то считается, что слова нет в словаре.
2.4 Алгоритм поиска слова в словареПри выборе структуры словаря были рассмотрены модели русского языка, а так же учитывались рекомендации. Потому в качестве основы был выбран словарь. Он содержит примерно 124000 корней, что позволяет покрыть достаточно большую часть русского языка (около 300000 слов).
Общим подходом словарь похож на корневую часть словаря и представляет собой текстовый файл в особом формате. Первая секция представляет набор моделей. Моделью называется совокупность пар префикса и постфикса. Ещё одна секция представляет набор корней с указателями соответствующую модель. Таким образом, достигается хороший процент сжатия словаря по сравнению с простым перечислением словоформ.
Лучше всего словарь можно представить в виде реляционной базы данных.
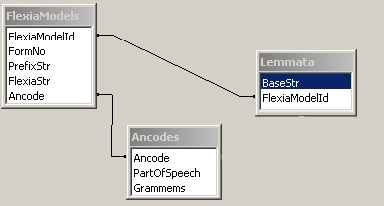
Словарь состоит из трёх частей: набор основ слов (Lemmata), набор возможных постфиксов (FlexiaModels) и набора дескрипторов (Ancodes). Взаимодействие этих частей показано на рисунке 3.1.
Рисунок 3.1. Схема морфологического словаря
Было рассмотрено несколько алгоритмов:
1) Расстояние Левенштейна.
2) Метод полных обратных преобразований.
3) Поиск максимальной подпоследовательности.
Расстояние Левенштейна и метод поиска максимальной подпоследовательности дают очень хорошие результаты при коррекции, однако имеют сложность зависимости от словаря больше линейной. Поэтому в работе был использован метод полных обратных преобразований. Для описания алгоритма необходимо дать несколько определений.
Определение: Отображение ошибки категории z = 1, 2 данной словоформы – множество словоформ, порождаемых этой словоформой в результате всех возможных ошибок категории z.
Выделяют два типа случайных ошибок:
1. удвоение символа (клаввиатура);
2. перестановка двух соседних символов (аглоритм).
Определение: Полное отображение одиночной ошибки данной словоформы – множество словоформ, порождаемых этой словоформой в результате всех возможных ошибок четырех категорий.
Таким образом, если через Г1 (словоформа) обозначить множество словоформ, порождаемых данной словоформой в результате ошибки категории 1 (отображение ошибки категории 1), через Г2 – отображение ошибки категории 2, через Г3 – отображение ошибки категории 3 и через Г4 – отображение ошибки категории 4, то полное отображение одиночной ошибки Г (словоформа) есть объединение всех четырех множеств.
Определение: Полное обратное отображение одиночной ошибки данной словоформы – множество словоформ, порождающих данную словоформу в результате одиночной ошибки из двух категорий.
Описание метода полных обратных преобразований:
1. Вносим в буквенную цепочку полное обратное преобразование.
2. Каждый из получившихся токенов проверяем на наличие в словаре.
3. Если токен имеется в словаре, то он добавляется в список корректных кандидатов.
Таким образом обеспечивается 100% вероятность коррекции ошибок, если корректное слово имеется в словаре. Однако данный алгоритм обладает неустранимой особенностью – все обрабатываемые токены никак не оцениваются, а потому невозможно выбрать наиболее подходящий вариант для исправления ошибки, т.е. требуется вмешательство оператора.
Для успешного процесса коррекции важны эффективные алгоритмы диагностики грамматических ошибок. В общем случае все сводится к определению принадлежности последовательности символов (токена) к данному естественному языку.
Таким образом, исправление опечаток определенных классов, в том числе однобуквенных, является практически важной задачей. Алгоритмы исправления ошибок в русских словах должны учитывать особенности русского языка как высоко флективного.
2.6 Описание программной реализацииДля работы алгоритмов АМА необходимы следующие массивы:
1) Массив base (содержит основы слов),
2) Массив flex (содержит постфиксы),
3) Массив mrf (содержит морфологические признаки).
Данные массивы заполняются на основе словарей morphologi.dic
и rgramtab.dic
Для поиска по массивам и анализа ошибок используются следующие методы:
3) s_basean
4) s_flexan
5) s_mrf
6) first_err
7) sec_err
Массив baseМассив base – двумерный динамический массив содержащий основы слов и указатель на строку из массива flex.
Примеры строк из массива base:
ВЗ 519
В данном примере набор символов ВЗ является основой слова. Число 519 – указатель номера строки в массиве flex, содержащей набор окончаний ассоциированных с данной основой.
Массив flexМассив flex – двумерный динамический массив, содержащий наборы окончаний. Данный массив является зависимым от массива base, также этот массив содержит указатель на строки массива mrf, идентифицирующие морфемные свойства слова.
Пример части строки из массива flex
%БИТЬСЯ*ка % БИЛСЯ*кз%
Набор символов «БИТЬСЯ» является формой постфикса, для определённой в массиве base основы. Набор символов «ка» является идентификатором строки с дескрипторами массива mrf.
Массив mrfМассив mrf – двумерный динамический массив, содержащий наборы дескрипторов, которые описывают морфемные свойства анализируемого слова.
Пример строки из массива mrf:
ка a ИНФИНИТИВ дст
В данной строке указано, что словоформа является Инфинитивом (начальной формой глагола), и является действительным.
Набор частей речи массива mrf указан в таблице 3.2.
Таблица 3.2. Описание частей речи массива mrf
| Часть речи в системе Диалинг | Пример | Расшифровка |
| C | мама | существительное |
| П | красный | прилагательное |
| МС | он | местоимение-существительное |
| Г | идет | глагол в личной форме |
| ПРИЧАСТИЕ | идущий | причастие |
| ДЕЕПРИЧАСТИЕ | идя | деепричастие |
| ИНФИНИТИВ | идти | инфинитив |
| МС-ПРЕДК | нечего | местоимение-предикатив |
| МС-П | всякий | местоименное прилагательное |
| ЧИСЛ | восемь | числительное (количественное) |
| ЧИСЛ-П | восьмой | порядковое числительное |
| Н | круто | наречие |
| ПРЕДК | интересно | предикатив |
| ПРЕДЛ | под | предлог |
| СОЮЗ | и | союз |
| МЕЖД | ой | междометие |
| ЧАСТ | же, бы | частица |
| ВВОДН | конечно | вводное слово |
| КР_ПРИЛ | красива | краткое прилагательное |
| КР_ПРИЧАСТИЕ | построена | краткое причастие |
Ниже перечислены все используемые граммемы:
мр, жр, ср – мужской, женский, средний род;
од, но – одушевленность, неодушевленность;
ед, мн – единственное, множественное число;
им, рд, дт, вн, тв, пр, зв – падежи: именительный, родительный, дательный, винительный, творительный, предложный, звательный;
2 – обозначает второй родительный или второй предложный падежи;
св, нс – совершенный, несовершенный вид;
пе, нп – переходный, непереходный глагол;
дст, стр. – действительный, страдательный залог;
нст, прш, буд – настоящее, прошедшее, будущее время;
пвл – повелительная форма глагола;
Похожие работы
... ресурсы и на последнем этапе проведена оценка эффективности прототипа ИС, которая показала, что внедрение проекта целесообразно. Заключение Целью дипломного проекта являлась разработка подсистемы учета гематологических анализов для КДЛ ГБСМП-2 г. Ростова. Первым этапом дипломного проекта являлась определение цели и задач дипломного проекта. Был проведен анализ существующих систем. В первом ...
... , практически, не используются. Проблема информатизации Минторга может быть решена путем создания Автоматизированной Информационной системы Министерства Торговли РФ (АИС МТ РФ) в соответствии с настоящим Техническим предложением. ГЛАВА 2. МАТЕМАТИЧЕСКОЕ ОБЕСПЕЧЕНИЕ КОМПЛЕКСА ЗАДАЧ "СИСТЕМА ДОКУМЕНТООБОРОТА УЧЕРЕЖДЕНИЯ”. функции поиска и архивации 2.1. Постановка задачи и её спецификация ...
... уровня. В общем случае в качестве вариантов решений можно использовать классы стратегий, предлагаемых в экономической литературе. 16. Особенности проектирования интеллектуальной экономической информационной системы Проектирование ИИС начинается с обследования предметной области. Современные технологии такого обследования базируются на концепции и программных средствах реинжиниринга бизнес- ...
... сетям, что позволяет иметь более полную информацию о рынке труда в целом и даже об отдельных работниках - их прошлых мест работы, специализации, квалификации и т.п. 2. Анализ информационно-технического обеспечения системы управления персоналом ООО "БТСП" 2.1 Краткая характеристика предприятия ООО "БТСП" ООО "БТСП" - это предприятие по перевозке пассажиров, грузов и ремонту прочих ...
0 комментариев