Индивидуальное задание по Теории информации
Подготовил В.С. Прохоров
Построить групповой корректирующий код объёмом 9 слов. Код должен обеспечивать исправление одиночных и обнаружение двойных ошибок.
Разработать функциональные, а затем построить принципиальные электрические схемы кодирующего и декодирующего устройств для технической реализации сформированного кода.
Определим число информационных разрядов кода из соотношения
![]() ,
,
где Q – требуемый объём кода. В нашем случае Q=9, поэтому
![]()
Отсюда получаем ![]() .
.
![]()
![]()
![]()
Далее находим число n из неравенства
![]()
Подставляем ![]() и подбором находим минимальное n, удовлетворяющее неравенству. В нашем случае
и подбором находим минимальное n, удовлетворяющее неравенству. В нашем случае ![]() .
.
![]()
![]()
![]()
Далее мы должны составить таблицу опознавателей. Для этого необходимо ввести понятие вектора ошибок и опознавателя. Вектор ошибок это n-разрядная двоичная последовательность, имеющая единицы во всех разрядах, подвергшихся искажению, и нули в остальных разрядах. (Пример: искажению подверглись два младших разряда 6-разрядного сообщения - тогда вектор ошибки будет выглядеть как 000011), а опознаватель – некоторая сопоставленная этому вектору контрольная последовательность символов. В нашем случае векторы ошибок имеют разрядность 7 бит, так как ![]() , опознаватели имеют разрядность 3 бит, так как
, опознаватели имеют разрядность 3 бит, так как ![]() . Опознаватели рекомендуется записывать в порядке возрастания (нулевую комбинацию не используем).
. Опознаватели рекомендуется записывать в порядке возрастания (нулевую комбинацию не используем).
| Векторы ошибок | Опознаватели | |
| 1 | 0000001 | 001 |
| 2 | 0000010 | 010 |
| 3 | 0000100 | 011 |
| 4 | 0001000 | 100 |
| 5 | 0010000 | 101 |
| 6 | 0100000 | 110 |
| 7 | 1000000 | 111 |
Теперь необходимо определить проверочные равенства и сформулировать правила построения кода, способного исправлять все одиночные ошибки.
Выбираем из таблицы строки, где опознаватели имеют в первом (младшем) разряде единицу. Это строки 1, 3, 5 и 7. Тогда первое проверочное равенство будет выглядеть так:
![]()
Теперь выбираем строки, где опознаватели имеют во втором разряде единицу.
Это строки 2, 3, 6, 7.
Тогда второе проверочное правило выглядит так:
![]()
И, наконец выбираем строки, где опознаватели имеют единицу в третьем разряде. Это строки 4, 5, 6, 7. Следовательно третье проверочное равенство выглядит так:
![]()
Далее нужно отобрать строки, где опознаватели имеют всего одну единицу. В нашем случае это строки 1, 2 и 4. Возвращаемся к полученным ранее уравнениям. В левой части оставляем члены с выбранными нами только что индексами, а остальные переносим в правую часть:
![]()
![]()
![]()
Эти три уравнения и называются правилами построения кода. Код, построенный по этим правилам, может исправить все одиночные ошибки. Но нам необходимо, чтобы код также мог обнаруживать двойные ошибки. Для этого добавим к трём уравнениям, полученным ранее, ещё одно:
![]()
Мы получили окончательные правила построения кода, способного исправлять все одиночные и обнаруживать двойные ошибки:
Используя правила построения корректирующего кода (*), построим таблицу разрешённых комбинаций группового кода объёмом 9 слов, способного исправлять все одиночные и обнаруживать двойные ошибки. В колонку «безызбыточный код» записываем девять (по заданию Q=9) комбинаций по возрастанию (нулевую комбинацию не используем).
|
| (*) |
Все колонки, кроме ![]() ,
, ![]() ,
, ![]() и
и ![]() , содержимое которых определяется формулами (*), заполняем цифрами из безызбыточного кода:
, содержимое которых определяется формулами (*), заполняем цифрами из безызбыточного кода:
| слово | безызбыточный код | код | |||||||
|
|
|
|
|
|
|
|
| ||
|
| 0001 | 0 | 0 | 0 | 1 | ||||
|
| 0010 | 0 | 0 | 1 | 0 | ||||
|
| 0011 | 0 | 0 | 1 | 1 | ||||
|
| 0100 | 0 | 1 | 0 | 0 | ||||
|
| 0101 | 0 | 1 | 0 | 1 | ||||
|
| 0110 | 0 | 1 | 1 | 0 | ||||
|
| 0111 | 0 | 1 | 1 | 1 | ||||
|
| 1000 | 1 | 0 | 0 | 0 | ||||
|
| 1001 | 1 | 0 | 0 | 1 | ||||
Чтобы заполнить колонки ![]() ,
, ![]() ,
, ![]() и
и ![]() , подставляем значения необходимых переменных в соответствующие уравнения из (*). Например, для строки 9 (слово
, подставляем значения необходимых переменных в соответствующие уравнения из (*). Например, для строки 9 (слово ![]() ) получаем следующее:
) получаем следующее:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
| слово | безызбыточный код | избыточный код | |||||||
|
|
|
|
|
|
|
|
| ||
|
| 0001 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 |
|
| 0010 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 |
|
| 0011 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 |
|
| 0100 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 |
|
| 0101 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 |
|
| 0110 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 |
|
| 0111 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 |
|
| 1000 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 |
|
| 1001 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 |
Перейдём к построению функциональной схемы кодирующего устройства (см. соответствующий рисунок ниже). Назначение кодирующего устройства – внесение избыточности в код по заданным нами правилам. Схему строим на основании равенств (*). На схеме используется логический элемент «сумматор по модулю два», обозначенный М2. На схеме имеются два регистра, построенные на D-триггерах. Один из них содержит безызбыточный код и имеет разрядность 4 бит, так как ![]() , а другой содержит избыточный код и имеет разрядность 8 бит, так как
, а другой содержит избыточный код и имеет разрядность 8 бит, так как ![]() . Принцип работы схемы таков: по сигналу синхронизации на k-разрядный регистр поступает кодовая комбинация, подлежащая кодированию. Затем с помощью сумматоров эта комбинация кодируется (вносится избыточность). Сумматор С1 реализует первое равенство из (*), сумматор С2 – второе, С3 – третье, а С4 – четвёртое. И, наконец, по сигналу синхронизации полученный избыточный код записывается в 8-разрядный регистр. Далее начинается кодирование следующей комбинации.
. Принцип работы схемы таков: по сигналу синхронизации на k-разрядный регистр поступает кодовая комбинация, подлежащая кодированию. Затем с помощью сумматоров эта комбинация кодируется (вносится избыточность). Сумматор С1 реализует первое равенство из (*), сумматор С2 – второе, С3 – третье, а С4 – четвёртое. И, наконец, по сигналу синхронизации полученный избыточный код записывается в 8-разрядный регистр. Далее начинается кодирование следующей комбинации.
Далее рассмотрим функциональную схему декодирующего устройства (см. соответствующий рисунок ниже). В ней также используются два регистра на D-триггерах. Один из них содержит переданное слово и имеет разрядность 8 бит, так как ![]() , а другой содержит декодированные информационные символы и имеет разрядность 4 бит, так как
, а другой содержит декодированные информационные символы и имеет разрядность 4 бит, так как ![]() . Для построения схемы вспомним проверочные равенства, найденные ранее:
. Для построения схемы вспомним проверочные равенства, найденные ранее:
|
| (**) |
Обозначим буквой ![]() признак одиночной ошибки. Если
признак одиночной ошибки. Если ![]() , то имела место одиночная ошибка, если же
, то имела место одиночная ошибка, если же ![]() , то одиночной ошибки не было. Через
, то одиночной ошибки не было. Через ![]() обозначим результат общей проверки на чётность.
обозначим результат общей проверки на чётность.
![]()
Запишем алгоритм декодирования, пренебрегая возможностью возникновения ошибок кратности 3 и выше.
|
|
| Вывод |
| 0 | 0 | ошибок нет |
| 0 | 1 | ошибка в 8-ом разряде |
| 1 | 0 | двойная ошибка (повторная передача) |
| 1 | 1 | одиночная ошибка (исправление) |
Принцип работы дешифратора таков. На приёмный регистр поступает кодовая комбинация, которая может содержать ошибку. Сумматор С1 реализует первое равенство из (**), С2 – второе, а С3 – третье. Если ошибок не было, то на выходах этих трёх сумматоров будут нули. Если же имела место ошибка, то в этом случае на выходах сумматоров появится опознаватель ошибки. Этот опознаватель передаётся в дешифратор ошибок ДС, который на основании переданного в него опознавателя выдаёт соответствующий вектор ошибки. Его схема строится по следующей таблице истинности:
| Вход (опознаватель) | Выход (вектор ошибки) | ||||||||
| 1 | 2 | 3 | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
Чтобы восстановить верный сигнал нам необходимо сложить по модулю два сигнал дешифратора с соответствующим разрядом кодовой комбинации. Эта операция выполняется на сумматорах С5-С8. Таким образом мы исправляем одиночные ошибки.
Чтобы обнаружить двойную ошибку, мы предусматриваем следующее. Сумматор С4 проверяет последнее равенство из (**) – на его выходе мы имеем ![]() . В случае возникновения двойной ошибки на выходе этого сумматора появится ноль, так как две единицы не изменят чётности (
. В случае возникновения двойной ошибки на выходе этого сумматора появится ноль, так как две единицы не изменят чётности (![]() ). Элемент ИЛИ проверяет признак одиночной ошибки (
). Элемент ИЛИ проверяет признак одиночной ошибки (![]() ). На этот элемент подаётся вектор ошибки с дешифратора. А если вектор ошибки содержит хотя бы одну единицу (а это значит, что имела место ошибка), то на выходе элемента ИЛИ появится единица. Таким образом, если на выходе С4 мы получили ноль, а на выходе элемента ИЛИ единицу, мы можем говорить, что имела место двойная ошибка. В этом случае блокируем генератор тактовых импульсов, триггеры устанавливаются в ноль, а на специально предусмотренный выход ER подаём единицу.
). На этот элемент подаётся вектор ошибки с дешифратора. А если вектор ошибки содержит хотя бы одну единицу (а это значит, что имела место ошибка), то на выходе элемента ИЛИ появится единица. Таким образом, если на выходе С4 мы получили ноль, а на выходе элемента ИЛИ единицу, мы можем говорить, что имела место двойная ошибка. В этом случае блокируем генератор тактовых импульсов, триггеры устанавливаются в ноль, а на специально предусмотренный выход ER подаём единицу.
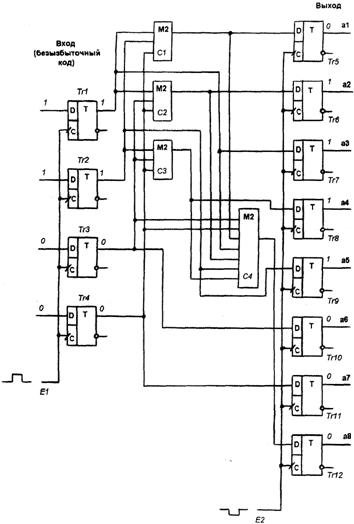
Функциональная схема кодирующего устройства

Функциональная схема декодирующего устройства
Далее по функциональным схемам строим принципиальные электрические схемы. Для построения принципиальных схем используем программный пакет Multisim.
Начнём со схемы кодирующего устройства. Сначала расположим источник питания и генератор тактовых импульсов. Установим значение напряжения 15В, а частоту импульсов – 1Гц. Затем поместим на схему D-триггеры. Нам требуется 4 триггера на вход и 8 триггеров на выход – всего 12. Мы можем использовать 3 микросхемы 74175N, каждая из которых содержит по 4 D-триггера. Помещаем триггеры на схему, к входу CLR подключаем источник питания, ко входу CLK – генератор тактовых импульсов. Для выходных триггеров сигнал от генератора необходимо пропустить через инвертор, так как для формирования выходных импульсов необходимо время и мы должны «задержать» импульс синхронизации. Далее нам необходимы три трёхвходовых элемента для сложения по модулю два. Эти элементы можно синтезировать с помощью двухвходовых элементов 7486N так, как показано на рисунке. Семивходовый элемент для сложения по модулю два также можно синтезировать с помощью двухвходовых элементов 7486N. Теперь просто соединяем полученные части в соответствии с функциональной схемой. Получаем принципиальную электрическую схему кодирующего устройства. Для проверки правильности работы схемы на вход можно направить данные из Word Generator’а, который будет по очереди генерировать все 9 слов, а на выходы подключить 8 сигнализаторов. Принципиальную схему смотри на развороте.
Перейдём к схеме декодирующего устройства.
Сначала, так же, как и в схеме кодирующего устройства, располагаем источник питания и генератор. Устанавливаем для них те же параметры. Устанавливаем те же D-триггеры. Здесь нам понадобится 8 триггеров для входа, и 4 для выхода. Также используем 3 микросхемы 74175N, каждая из которых содержит по 4 D-триггера. Триггеры подключаем аналогично. Нам потребуются 3 четырёхвходовых и один восьмивходовый элемент для сложения по модулю 2. Их синтезируем так же, как и при составлении схемы кодирующего устройства. Семивходовый элемент ИЛИ синтезируем по тому же принципу. Теперь по известной нам схеме истинности необходимо синтезировать схему дешифратора ошибок. Её можно синтезировать, используя такой логический элемент, как дешифратор. В нашем случае мы можем использовать микросхему 74154N. Эта схема является дешифратором-мультиплексором с 4-мя входами и 16-ю выходами. Её подключаем так, как показано на рисунке (к выходам подключены инверторы 7404N). При таком подключении мы получим схему дешифратора ошибок. Внимание! Использовать нужно именно те входы, которые показаны на рисунке. Далее просто соединяем полученные части согласно функциональной схеме. Принципиальную схему смотри на развороте.
0 комментариев