Кафедра ЭВА
Отчет по курсовой работе
по дисциплине
«Системное Программное Обеспечение»
на тему
«Однопроходный/двухпроходный транслятор с языка математических выражений на язык деревьев вывода.
Интерпретатор языка деревьев вывода»
Москва 2009
Аннотация
Цель данной курсовой работы:
– изучение принципов построения трансляторов
– написание на языке C++ класса, реализующего следующие действия над математическими выражениями:
– лексический анализ
– синтаксический анализ
– вычисление значения
– написание транслятора с языка математических выражений на язык деревьев вывода
– написание интерпретатора языка деревьев вывода
Теоретическое введение
Теория построения трансляторов используется во многих областях, связанных с программным обеспечением. Важность этой темы можно проиллюстрировать на примере языка высокого уровня C++: для разработки программы на C++ требуется гораздо меньше времени, чем на языках более низкого уровня.
Формальные грамматики Формальное определение грамматики. Форма Бэкуса–Наура
Грамматика – это описание способа построения предложений некоторого языка. Иными словами, грамматика – это математическая система, определяющая язык. Фактически, определив грамматику языка, мы указываем правила порождения цепочек символов, принадлежащих этому языку. Таким образом, грамматика – это генератор цепочек языка.
Правило (или продукция) – это упорядоченная пара цепочек символов (α, β). В правилах важен порядок цепочек, поэтому их чаще записывают в виде α → β (или α::= β). Такая запись читается как «α порождает β» или «β по определению есть α».
Грамматика языка программирования содержит правила двух типов: первые (определяющие синтаксические конструкции языка) довольно легко поддаются формальному описанию; вторые (определяющие семантические ограничения языка) обычно излагаются в неформальной форме. Поэтому любое описание (или стандарт) языка программирования обычно состоит из двух частей: вначале формально излагаются правила построения синтаксических конструкций, а потом на естественном языке дается описание семантических правил.
Язык, заданный грамматикой G, обозначается как L(G).
Две грамматики G и G' называются эквивалентными, если они определяют один и тот же язык: L(G) = L(G'). Две грамматики G и G' называются почти эквивалентными, если заданные ими языки различаются не более чем на пустую цепочку символов: ![]()
Формально грамматика G определяется как четверка G (VT, VN, P, S), где:
VT – множество терминальных символов или алфавит терминальных символов;
VN – множество нетерминальных символов или алфавит нетерминальных символов;
Р – множество правил (продукций) грамматики, вида ![]() , где
, где ![]() ,
, ![]()
S – целевой (начальный) символ грамматики ![]() .
.
Алфавиты терминальных и нетерминальных символов грамматики не пересекаются: ![]() . Целевой символ грамматики – это всегда нетерминальный символ. Множество
. Целевой символ грамматики – это всегда нетерминальный символ. Множество ![]() называют полным алфавитом грамматики G.
называют полным алфавитом грамматики G.
Множество терминальных символов VT содержит символы, которые входят в алфавит языка, порождаемого грамматикой. Как правило, символы из множества VT встречаются только в цепочках правых частей правил. Множество нетерминальных символов VN содержит символы, которые определяют слова, понятия, конструкции языка. Каждый символ этого множества может встречаться в цепочках как левой, так и правой частей правил грамматики, но он обязан хотя бы один раз быть в левой части хотя бы одного правила.
Во множестве правил грамматики может быть несколько правил, имеющих одинаковые левые части, вида: ![]() . Тогда эти правила объединяют вместе и записывают в виде:
. Тогда эти правила объединяют вместе и записывают в виде: ![]() . Одной строке в такой записи соответствует сразу n правил.
. Одной строке в такой записи соответствует сразу n правил.
Такую форму записи правил грамматики называют формой Бэкуса–Наура. Форма Бэкуса–Наура предусматривает, как правило, также, что нетерминальные символы берутся в угловые скобки: < >.
Пример грамматики, определяющей язык целых десятичных чисел со знаком:
С({0,1,2. 3,4.5. 6,7.8.9.-,+}, {<число>,<чс>.<цифра>}, Р,<число>)
P:
<<число> -> <чс> | +<чс> | -<чс>
<<чс> -> <цифра> | <чс><цифра>
<<цифра> ->0|1|2|3|4|5|6|7|8|9
Рассмотрим составляющие элементы грамматики G:
· множество терминальных символов VT содержит двенадцать элементов: десять десятичных цифр и два знака;
· множество нетерминальных символов VN содержит три элемента: символы <число>, <чс> и <цифра>;
· множество правил содержит 15 правил, которые записаны в три строки (то есть имеется только три различных правых части правил);
· целевым символом грамматики является символ <число>.
Названия нетерминальных символов не обязаны быть осмысленными. Это сделано для удобства понимания правил грамматики человеком. Например, в программе на языке Pascal можно изменить имена идентификаторов, и при этом не изменится смысл программы. Для терминальных символов это неверно. Набор терминальных символов всегда строго соответствует алфавиту языка, определяемого грамматикой.
Принцип рекурсии в правилах грамматикиОсобенность рассмотренных выше формальных грамматик в том, что они позволяют определить бесконечное множество цепочек языка с помощью конечного набора правил. Приведенная выше в примере грамматика для целых десятичных чисел со знаком определяет бесконечное множество целых чисел с помощью 15 правил. В такой форме записи грамматики возможность пользоваться конечным набором правил достигается за счет рекурсивных правил. Рекурсия в правилах грамматики выражается в том, что один из нетерминальных символов определяется сам через себя. Рекурсия может быть непосредственной (явной) – тогда символ определяется сам через себя в одном правиле, либо косвенной (неявной) – тогда то же самое происходит через цепочку правил.
В рассмотренной выше грамматике G непосредственная рекурсия присутствует в правиле: <чс> ![]() <чс><цифра>.
<чс><цифра>.
Чтобы рекурсия не была бесконечной, для участвующего в ней нетерминального символа грамматики должны существовать также и другие правила, которые определяют его, минуя его самого, и позволяют избежать бесконечного рекурсивного определения (в противном случае этот символ в грамматике был бы просто не нужен). Такими правилами являются <чс>![]() <цифра> – в грамматике G.
<цифра> – в грамматике G.
В теории формальных языков более ничего сказать о рекурсии нельзя. Но чтобы полнее понять смысл рекурсии, можно прибегнуть к семантике языка – в рассмотренном выше примере это язык целых десятичных чисел со знаком. Рассмотрим его смысл.
Если попытаться дать определение тому, что же является числом, то начать можно с того, что любая цифра сама по себе есть число. Далее можно заметить, что любые две цифры – это тоже число, затем – три цифры и т.д. Если строить определение числа таким методом, то оно никогда не будет закончено (в математике разрядность числа ничем не ограничена). Однако можно заметить, что каждый раз, порождая новое число, мы просто дописываем цифру справа (поскольку привыкли писать слева направо) к уже написанному ряду цифр. А этот ряд цифр, начиная от одной цифры, тоже в свою очередь является числом. Тогда определение для понятия «число» можно построить таким образом: «число – это любая цифра либо другое число, к которому справа дописана любая цифра». Именно это и составляет основу правил грамматики G и отражено в правилах
<чс> ![]() <цифра> | <чс><цифра>. Другие правила в этой грамматике позволяют добавить к числу знак и дают определение понятию «цифра».
<цифра> | <чс><цифра>. Другие правила в этой грамматике позволяют добавить к числу знак и дают определение понятию «цифра».
Принцип рекурсии – важное понятие в представлении о формальных грамматиках. Так или иначе, явно или неявно рекурсия всегда присутствует в грамматиках любых реальных языков программирования. Именно она позволяет строить бесконечное множество цепочек языка. Как правило, в грамматике реального языка программирования содержится не одно, а целое множество правил, построенных с помощью рекурсии.
Задача разбораДля каждого языка программирования важно не только уметь построить текст программы на этом языке, но и определить принадлежность имеющегося текста к данному языку. Именно эту задачу решают компиляторы в числе прочих задач (компилятор должен не только распознать исходную программу, но и построить эквивалентную ей результирующую программу). В отношении исходной программы компилятор выступает как распознаватель, а человек, создавший программу на некотором языке программирования, выступает в роли генератора цепочек этого языка.
Грамматики и распознаватели – два независимых метода, которые реально могут быть использованы для определения какого-либо языка. Однако при создании компилятора для некоторого языка программирования возникает задача, которая требует связать между собой эти методы задания языков. Разработчиков компиляторов интересуют, прежде всего, синтаксические конструкции языков программирования. Для этих конструкций доказано, что задача разбора для них разрешима. Более того, для них найдены формальные методы ее решения. Поскольку языки программирования не являются чисто формальными языками и несут в себе некоторый смысл (семантику), то задача разбора для создания реальных компиляторов понимается несколько шире, чем она формулируется для чисто формальных языков. Компилятор должен не просто установить принадлежность входной цепочки символов заданному языку, но и определить ее смысловую нагрузку. Для этого необходимо выявить те правила грамматики, на основании которых цепочка была построена.
Если же входная цепочка символов не принадлежит заданному языку – исходная программа содержит ошибку, – разработчику программы не интересно просто узнать сам факт наличия ошибки. В данном случае задача разбора также расширяется: распознаватель в составе компилятора должен не только установить факт присутствия ошибки во входной программе, но и по возможности определить тип ошибки и то место во входной цепочке символов, где она встречается.
Виды рекурсий и разбораПравила, имеющие вид
1) T-> T * A
2) T-> A * T
Называются леворекурсивными и праворекурсивными соответственно.
Разбор входной программы может быть как нисходящим так и восходящим. При нисходящем разборе недопустима левая рекурсия в правилах, т. к. она приводит к бесконечному зацикливанию. Левую рекурсию можно преобразовать в эквивалентую праворекурсивную форму следующим образом:
T-> A M
M-> * A | M
При восходящем разборе в правилах недопустима правая рекурсия. Аналогичным образом преобразовываются правила с правой рекурсией в правила с левой рекурсией.
Классификация языков и грамматикЧем сложнее язык программирования, тем выше вычислительные затраты компилятора на анализ цепочек исходной программы, написанной на этом языке, а следовательно, сложнее сам компилятор и его структура. Для некоторых типов языков в принципе невозможно построить компилятор, который бы анализировал исходные тексты на этих языках за приемлемое время на основе ограниченных вычислительных ресурсов (именно поэтому до сих пор невозможно создавать программы на естественных языках, например на русском или английском).
Классификация грамматик по ХомскомуСогласно классификации, предложенной американским лингвистом Ноамом Хомским, формальные грамматики классифицируются по структуре их правил. Если все без исключения правила грамматики удовлетворяют некоторой заданной структуре, то такую грамматику относят к определенному типу.
Хомский выделил четыре типа грамматик.
Тип 0: грамматики с фразовой структуройНа структуру их правил не накладывается никаких ограничений: для грамматики вида G (VT, VN, P, S), ![]() правила имеют вид:
правила имеют вид: ![]() , где
, где ![]() .
.
Это самый общий тип грамматик. В него подпадают все без исключения формальные грамматики, но часть из них, к общей радости, может быть также отнесена и к другим классификационным типам. Дело в том, что грамматики, которые относятся только к типу 0 и не могут быть отнесены к другим типам, являются самыми сложными по структуре.
Практического применения грамматики, относящиеся только к типу 0, не имеют.
Тип 1: контекстно-зависимые (КЗ) и неукорачивающие грамматикиВ этот тип входят два основных класса грамматик:
Контекстно-зависимые грамматики G (VT, VN, P, S), ![]() имеют правила вида:
имеют правила вида:
![]() , где
, где ![]()
Неукорачивающие грамматики G (VT, VN, P, S), ![]() имеют правила вида:
имеют правила вида:
![]() , где
, где ![]()
Структура правил КЗ-грамматик такова, что при построении предложений заданного ими языка один и тот же нетерминальный символ может быть заменен на ту или иную цепочку символов в зависимости от того контекста, в котором он встречается. Именно поэтому эти грамматики называют «контекстно-зависимыми». Цепочки ![]() и
и ![]() в правилах грамматики обозначают контекст (
в правилах грамматики обозначают контекст (![]() – левый контекст, а
– левый контекст, а ![]() - правый контекст), в общем случае любая из них (или даже обе) может быть пустой. Неукорачивающие грамматики имеют такую структуру правил, что при построении предложений языка, заданного грамматикой, любая цепочка символов может быть заменена на цепочку символов не меньшей длины. Отсюда и название «неукорачивающие».
- правый контекст), в общем случае любая из них (или даже обе) может быть пустой. Неукорачивающие грамматики имеют такую структуру правил, что при построении предложений языка, заданного грамматикой, любая цепочка символов может быть заменена на цепочку символов не меньшей длины. Отсюда и название «неукорачивающие».
Доказано, что эти два класса грамматик эквивалентны.
При построении компиляторов такие грамматики не применяются, поскольку синтаксические конструкции языков программирования, рассматриваемые компиляторами, имеют более простую структуру и могут быть построены с помощью грамматик других типов. Что касается семантических ограничений языков программирования, то с точки зрения затрат вычислительных ресурсов их выгоднее проверять другими методами, а не с помощью контекстно-зависимых грамматик.
Тип 2: контекстно-свободные (КС) грамматикиКонтекстно-свободные (КС) грамматики G (VT, VN, P, S), ![]() имеют правила вида:
имеют правила вида:![]() , где
, где ![]() . Такие грамматики также иногда называют неукорачивающими контекстно-свободными (НКС) грамматиками (видно, что в правой части правила у них должен всегда стоять как минимум один символ). Существует также почти эквивалентный им класс грамматик – укорачивающие контекстно-свободные (УКС) грамматики G (VT, VN, P, S),
. Такие грамматики также иногда называют неукорачивающими контекстно-свободными (НКС) грамматиками (видно, что в правой части правила у них должен всегда стоять как минимум один символ). Существует также почти эквивалентный им класс грамматик – укорачивающие контекстно-свободные (УКС) грамматики G (VT, VN, P, S), ![]() , правила которых могут иметь вид:
, правила которых могут иметь вид: ![]() , где
, где![]() .
.
Разница между этими двумя классами грамматик заключается лишь в том, что в УКС-грамматиках в правой части правил может присутствовать пустая цепочка (X), а в НКС-грамматиках – нет. Доказано, что эти два класса грамматик почти эквивалентны.
КС-грамматики широко используются при описании синтаксических конструкций языков программирования. Синтаксис большинства известных языков программирования основан именно на КС-грамматиках.
Внутри типа КС-грамматик кроме классов НКС и УКС выделяют еще целое множество различных классов грамматик, и все они относятся к типу 2.
Тип 3: регулярные грамматикиК типу регулярных относятся два эквивалентных класса грамматик: леволинейные и праволинейные.
Леволинейные грамматики G (VT, VN, P, S), ![]() могут иметь правила двух видов:
могут иметь правила двух видов: ![]() или
или ![]() , где
, где ![]() .
.
В свою очередь, праволинейные грамматики G (VT, VN, P, S), ![]() могут иметь правила тоже двух видов:
могут иметь правила тоже двух видов: ![]() или
или ![]() , где
, где![]() .
.
Эти два класса грамматик эквивалентны и относятся к типу регулярных грамматик.
Регулярные грамматики используются при описании простейших конструкций языков программирования: идентификаторов, констант, строк, комментариев и т.д. Эти грамматики исключительно просты и удобны в использовании, поэтому в компиляторах на их основе строятся функции лексического анализа входного языка.
Соотношения между типами грамматикТипы грамматик соотносятся между собой особым образом. Из определения типов 2 и 3 видно, что любая регулярная грамматика является КС-грамматикой, но не наоборот. Также очевидно, что любая грамматика может быть отнесена к типу 0, поскольку он не накладывает никаких ограничений на правила. В то же время существуют укорачивающие КС-грамматики (тип 2), которые не являются ни контекстно-зависимыми, ни неукорачивающими (тип 1), поскольку могут содержать правила вида ![]() , недопустимые в типе 1.
, недопустимые в типе 1.
Одна и та же грамматика в общем случае может быть отнесена к нескольким классификационным типам (например, как уже было сказано, все без исключения грамматики могут быть отнесены к типу 0). Для классификации грамматики всегда выбирают максимально возможный тип, к которому она может быть отнесена. Сложность грамматики обратно пропорциональна номеру типа, к которому относится грамматика.
Трансляторы Формальное определение транслятора
Транслятор – это программа, которая переводит программу на исходном (входном) языке в эквивалентную ей программу на результирующем (выходном) языке.
С точки зрения преобразования предложений входного языка в эквивалентные им предложения выходного языка транслятор выступает как переводчик.
Результатом работы транслятора будет результирующая программа, но только в том случае, если текст исходной программы является правильным – не содержит ошибок с точки зрения синтаксиса и семантики входного языка. Если исходная программа неправильная (содержит хотя бы одну ошибку), то результатом работы транслятора будет сообщение об ошибке.
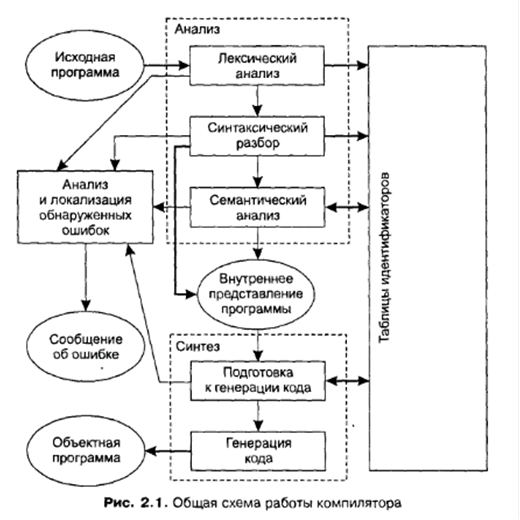
Этапы трансляции. Общая схема работы транслятораНа рис. 2.1 представлена общая схема работы компилятора. Из нее видно, что в целом процесс компиляции состоит из двух основных этапов – анализа и синтеза. На этапе анализа выполняется распознавание текста исходной программы, создание и заполнение таблиц идентификаторов. Результатом его работы служит некое внутреннее представление программы, понятное компилятору. На этапе синтеза на основании внутреннего представления программы и информации, содержащейся в таблице идентификаторов, порождается текст результирующей программы. Результатом этого этапа является объектный код. Кроме того, в составе компилятора присутствует часть, ответственная за анализ и исправление ошибок, которая при наличии ошибки в тексте исходной программы должна максимально полно информировать пользователя о типе ошибки и месте ее возникновения. В лучшем случае компилятор может предложить пользователю вариант исправления ошибки.
Эти этапы, в свою очередь, состоят из более мелких этапов, называемых фазами компиляции. Состав фаз компиляции на рис. 2.1 приведен в самом общем виде, их конкретная реализация и процесс взаимодействия могут, конечно, различаться в зависимости от версии компилятора.
Компилятор в целом, с точки зрения теории формальных языков, выполняет две основные функции:
– распознавание языка исходной программы
– генерация результирующей программы на заданном языке.
Далее дается перечень основных фаз (частей) компиляции и краткое описание их функций.
Лексический анализатор (сканер) – это часть компилятора, которая читает литеры программы на исходном языке и строит из них слова (лексемы) исходного языка. На вход лексического анализатора поступает текст исходной программы, а выходная информация передается для дальнейшей обработки компилятором на этапе синтаксического разбора. С теоретической точки зрения лексический анализатор не является обязательной, необходимой частью компилятора. Однако существуют причины, которые определяют его присутствие практически во всех компиляторах.
Синтаксический анализатор – это основная часть компилятора на этапе анализа. Она выполняет выделение синтаксических конструкций в тексте исходной программы, обработанном лексическим анализатором. На этой же фазе компиляции проверяется синтаксическая правильность программы. Синтаксический разбор играет роль распознавателя текста входного языка программирования.
Семантический анализатор – это часть компилятора, проверяющая правильность текста исходной программы с точки зрения семантики входного языка. Кроме непосредственно проверки семантический анализ должен выполнять преобразования текста, требуемые семантикой входного языка (например, такие, как добавление функций неявного преобразования типов). В различных реализациях компиляторов семантический анализ может частично входить в фазу синтаксического разбора, частично – в фазу подготовки к генерации кода.
Подготовка к генерации кода – это фаза, на которой компилятором выполняются предварительные действия, непосредственно связанные с синтезом текста результирующей программы, но еще не ведущие к порождению текста на выходном языке. Обычно в эту фазу входят действия, связанные с идентификацией элементов языка, распределением памяти и т.п.
Генерация кода – это фаза, непосредственно связанная с порождением команд, составляющих предложения выходного языка и в целом текст результирующей программы. Это основная фаза на этапе синтеза результирующей программы. Кроме непосредственного порождения текста результирующей программы генерация обычно включает в себя также оптимизацию – процесс, связанный с обработкой уже порожденного текста. Иногда оптимизацию выделяют в отдельную фазу компиляции, так как она оказывает существенное влияние на качество и эффективность результирующей программы.
Проход транслятора – процесс последовательного чтения компилятором данных из памяти, их обработки и помещёния результата в память. В компиляторе может быть реализовано несколько проходов, например проходы лексического и синтаксического анализатора. В некоторых случаях проходы могут быть объединены в один проход.
ИнтерпретаторыИнтерпретатор – программа, воспринимающая исходную программу на входном (исходном) языке и выполняющая ее.
Интерпретатор, также как и транслятор, анализирует текст исходной программы, но он не порождает результирующую программу, а сразу выполняет исходную в соответствии с ее смыслом, заданным семантикой ее языка.
Lex и Yacc Обзор генераторов кода
Системы GNU/Linux поставляются с несколькими программами для написания программ. Возможно наиболее популярны:
· Flex, генератор лексического анализатора
· Bison, генератор синтаксического анализатора
· Gperf, развитый генератор хэш-функции
Эти программы генерируют тексты для языка C. Вы можете удивиться, почему они реализованы в виде генераторов кода, а не в виде функций. Тому есть несколько причин:
· Входные параметры для этих функций являются очень сложными и их непросто выразить в виде, корректном для C-кода.
· Эти программы вычисляют и генерируют много статических таблиц преобразования для операции, следовательно, лучше сгенерировать эти таблицы один раз перед компиляцией, чем при каждом запуске программы.
· Многие аспекты функционирования этих систем настраиваются произвольным кодом, помещаемым на отдельные позиции. Этот код может впоследствии использовать переменные и функции, являющиеся частью сгенерированной структуры, построенной генератором кода, без необходимости определять и извлекать все переменные вручную.
Каждое из этих инструментальных средств предназначено для создания конкретного типа программ. Bison используется для генерирования синтаксических анализаторов; Flex – для генерирования лексических анализаторов. Другие средства посвящены, в основном, автоматизации конкретных аспектов программирования.
Например, интегрирование методов доступа к базе данных в императивные языки программирования часто является рутинной работой. Для ее облегчения и стандартизации предназначен Embedded SQL – система метапрограммирования, используемая для простого комбинирования доступа к базе данных и C.
Хотя существует немало доступных библиотек, позволяющих обращаться к базам данных в C, использование такого генератора кода как Embedded SQL делает комбинирование C и доступа к базе данных намного более легким путем объединения SQL-сущностей в C в качестве расширения языка. Многие реализации Embedded SQL, однако, в основном являются простыми специализированными макропроцессорами, генерирующими обычные C-программы. Тем не менее, использование Embedded SQL делает для программиста доступ к базе данных более естественным, интуитивным и свободным от ошибок по сравнению с прямым использованием библиотек. При помощи Embedded SQL запутанность программирования баз данных маскируется макроязыком
Совместное использование Lex и YaccДо 1975 года процесс написания компиляторов занимал очень много времени. Затем Lesk[1975] и Johnson[1975] опубликовали труды по lex и yacc. Эти утилиты сильно упростили написание компиляторов. Детали реализации могут быть найдены у Aho[1986]
Шаблоны кода помещаются на вход Lex. Lex читает шаблоны и генерирует C код для лексического анализатора или сканера.
Лексический анализатор ищет совпадение строк во входных данных, основываясь на заданных шаблонах, и преобразует строки в токены.
Токены являются числовым представлением строк упрощающим обработку.
Когда лексический анализатор находит идентификаторы во входном потоке, они вносятся в таблицу символов. Таблица символов также может содержать другую информацию такую, как тип данных (целый или вещественный) и место переменной в памяти. Все последующие ссылки на идентификаторы ссылаются на соответствующий индекс таблицы символов.
Код грамматики подаются на вход yacc. Yacc читает грамматику и генерирует C код для синтаксического анализатора или разборщика. Синтаксический анализатор использует грамматические правила, которые позволяют ему анализировать токены из лексического анализатора и создать синтаксическое дерево. Синтаксическое дерево устанавливает иерархичскую структуру токенов. Например, оператор precedence и ассоциативности (associativity) показаны в синтаксическом дереве. Следующий шаг, генерация кода, осуществляется с помощью обхода синтаксического дерева. Некоторые компиляторы создают машинный код, когда как некоторые – программу на языках ассемблера.
Команды для создания компилятора, bas.exe, приведены ниже:
yacc – d bas.y # create y.tab.h, y.tab.c
lex bas.l # create lex.yy.c
cc lex.yy.c y.tab.c – obas.exe # compile/link
Yacc читает грамматические описания в bas.y и генерирует синтаксический анализатор (parser), который включает функцию yyparse, в файле y.tab.c. Файл bas.y содержит в себе объявления токенов. Включение опции – d ведет к тому, что yacc генерирует определения для токенов и помещает их в файл y.tab.h. Lex читает шаблоны, описанные в bas.l, включающие файл y.tab.h и генерирует лексический анализатор, который включает функцию yylex, в файле lex.yy.c. Наконец, лексический анализатор (lexer) и синтаксический анализатор (parser) компилируются и компонуются вместе, образуя исполняемый файл bas.exe. Из main, мы вызываем yyparse, чтобы запустить компилятор. Функция yyparse автоматически вызывает yylex, чтобы получить каждый токен.
Lex TheoryПервая фаза в компиляторе – чтение входного исходного файла и его преобразование в токены. Используя регулярные выражения, мы можем специфицировать шаблоны для лексического анализа, и это позволит сгенерировать код, который позволит сканировать и найти совпадающие строки в исходном коде. Каждому шаблону специфицированному в исходном коде для лексического анализа, сопоставляется ассоциированное действие. Обычно действие возвращает токен, который представляет совпадающую строку, в последующем используемую синтаксическим анализатором. Сначала просто печатаем совпавшую строку, если возвращается значение токена.
Далее следует представление простого шаблона, составляющего регулярное выражение, которое ищет идентификаторы. Lex читает этот шаблон и создает C код для лексического анализатора, который ищет идентификаторы.
letter (letter|digit)*
Этот шаблон ищет строку символов, которая начинается с единичного символа, следующим за нулем или больше символов или цифр. Этот пример хорошо иллюстрирует, операции, разрешенные а регулярных выражениях:
• повторение, представленное оператором «*» (repetition)
• чередование, представленное оператором «|» (alternation)
• объединение (concatenation)
Любое регулярное выражение может быть представлено автоматом с конечным числом состояний (finite state automaton, FSA). Мы можем представить FSA, использующее состояния и переходы между состояниями. Существует одно начальное состояние и одно, или больше, конечных состояний или разрешенных состояний.

На рис. 3, состояние 0 – является начальным состоянием, а состояние 2 – разрешенным состоянием. Когда происходит чтение символа, осуществляется переход из одного состояния в другое. Когда читается первый символ, осуществляется переход в состояние 1. Автомат остается в состоянии 1, пока читаются буквы (letters) или цифры (digits). Когда осуществляется чтение иного символа, кроме буквы или символа, осуществляется переход в состояние 2, разрешенное состояние. Любой FSA может быть представлен с помощью компьютерной программы. Например, этот автомат с 3 мя состояниями программируется следующим образом:
start: goto state0
state0: read c
if c = letter goto state1
goto state0
state1: read c
if c = letter goto state1
if c = digit goto state1
goto state2
state2: accept string
Это техника, используемая lex. Регулярные выражения транслируются с помощью lex в компьютерную программу, которая реализует FSA. Используя следующий входной символ и текущее состояние, следующее состояние определяется с помощью индексирования в сгенерированной компьютером таблице состояний.
Теперь становится легко понять ограничения в lex. Например, lex не может быть использован.
Таблица 1. Элементарные шаблоны (Pattern Matching Primitives)
| Метасимвол (Metacharacter) | Совпадения (Matches) |
| . | Любой символ, кроме перевода строки |
| \n | Символ перевода строки |
| * | 0 или более копий предшествующих выражений |
| + | 1 или более копий предшествующих выражений |
| ? | 0 или 1 копия предшествующих выражений |
| ^ | Начало строки |
| $ | Конец строки |
| a|b | a или b |
| (ab)+ | Одна или более копий ab (группировка, grouping) |
| «a+b» | литерал «a+b» (C escapes still work) |
| [] | Класс символов |
Таблица 2. Примеры шаблонов выражений (Pattern Matching Examples)
| Выражение (Expression) | Совпадения (Matches) |
| abc | abc |
| abc* | ab abc abcc abccc… |
| abc+ | abc abcc abccc… |
| a(bc)+ | abc abcbc abcbcbc… |
| a(bc)? | a abc |
| [abc] | Одно из: a, b, c |
| [a-z] | Любой символ, a-z |
| [a\-z] | Одно из: a, -, z |
| [-az] | Одно из: -, a, z |
| [A-Za-z0–9]+ | Один или более символов алфавита или цифр |
| [\t\n]+ | Пробельные символы |
| [^ab] | Все, кроме: a, b |
| [a^b] | Одно из: a, ^, b |
| [a|b] | Одно из: a, |, b |
| a|b | Одно из: a, b |
Регулярные выражения в lex составляются из метасимволов (Таблица 1). Примеры совпадения шаблонов показаны в таблице 2. При использовании класса символов, обычные операторы теряют свое назначение.
Следующие два оператора разрешены в классе символов: дефис («–», hyphen) и циркумфлекс («^», circumflex). При использовании между двумя символами дефиса, представляется диапазон символов. Циркумфлекс, при использовании его как первого символа, отрицает выражение. Если два шаблона совпадают с некоторой строкой, используется наиболее шаблон, по которому найдена наиболее длинная строка, в случае, если длина одинакова, используется первый шаблон.
… definitions…
%%
… rules…
%%
… subroutines…
Входные данные lex делятся на 3 секции, с символами%%, разделяющими секции. Это проиллюстрировано в примере. Первый пример – это наименьший возможный файл lex:
%%
Входные данные копируются выходные по одному символу за раз. Первый разделитель%% требуется всегда, так как всегда должна быть секция правил. Если не специфицировать ни одного правила, тогда действие по умолчанию – совпадение всего и копирование в выходные данные. По умолчанию для входных и выходных данных используются stdin и stdout, соответственно. Вот некоторый пример, с использованием кода по умолчанию:
%%
/* Совпадение всего, кроме символа новой строки */
ECHO;
/* Совпадение символа перевода строки */
\n ECHO;
%%
int yywrap(void) {
return 1;
}
int main(void) {
yylex();
return 0;
}
Два шаблона специфицированы в секции правил. Каждый шаблон должен начинаться в первом столбце, то есть должен следовать за пробельным символом. Опциональное действие ассоциируется с шаблоном. Действие может быть единичным выражением на языке C или множественным, заключенным в скобки. Все, не начинающееся с первого столбца, дословно копируется в генерируемый C файл. Можно использовать это для спецификации комментариев в lex файле. В этом примере есть 2 выражения:
«.» и «\n» с действием ECHO, ассоциированным с каждым шаблоном. Несколько макросов и переменных определены в lex. ECHO – это макрос, который пишет код, совпадающий с шаблоном. Это действие по умолчанию для каждой несовпадающей строки. Обычно ECHO определяется как
#define ECHO fwrite (yytext, yyleng, 1, yyout)
Переменная yytext – указатель на совпавшую строку (оканчивающийся NULL-символом), и yyleng – длина совпавшей строки. Выражение yyout является выходным файлом и по умолчанию является stdout. Функция yywrap вызывается lex, когда входные данные закончились. Возвращает 1, если закончено, 0 если требуется дальнейшая обработка. Каждая программа на C требует main функцию. В этом случае просто вызывается yylex,
Основная точка входа для lex. Некоторые реализации lex включают копии main и yywrap в библиотеку, устраняя необходимость явно определять их. Поэтому первый пример, наименьшая программа lex правильно функционирует.
| Name | Function |
| int yylex(void) | Вызывается для запуска лексического анализатора, возвращает токен |
| char *yytext | Указатель на совпавшую строку |
| yyleng | Длина совпавшей строки |
| yylval | Значение, ассоциируемое с токеном |
| int yywrap(void) | Wrapup – обертка возвращает 1 – если завершена, 0 – если не завершено |
| FILE *yyout | Выходной файл |
| FILE *yyin | Входной файл |
| INITIAL | Исходное условие старта |
| BEGIN | Условие переключающее условие старта |
| ECHO | Записать совпавшую строку |
Следующий пример присоединяет слева номер линии для каждой линии в файле. Некоторые реализации lex предопределяют вычисление yylineno. Входной файл для lex – это yyin, и является по умолчанию stdin.
%{
int yylineno;
%}
%%
^(.*)\n printf («%4d\t % s», ++yylineno, yytext);
%%
int main (int argc, char *argv[]) {
yyin = fopen (argv[1], «r»);
yylex();
fclose(yyin);
}
Секции определений состоят из замен, кода и начальных состояний. Код в секциях определения просто копируется в начало генерируемого C файла, при этом код должен быть в скобках%{» и «%}». Замены облегчаются правилами совпадения шаблонов. Например, можно определить цифры и символы:
digit [0–9]
letter [A-Za-z]
%{
int count;
%}
%%
/* match identifier */
{letter} ({letter}|{digit})* count++;
%%
int main(void) {
yylex();
printf («number of identifiers =%d\n», count);
return 0;
}
Пробел должен разделять терм и ассоциируемое выражение. Ссылки на подстановки в секциях правил окружены скобками ({letter}), чтобы различать их с символами. Когда происходит совпадение в секции правил, ассоциируемый C код выполняется. Вот программа, которая считает количество символов, слов и линий в файле (подобная команде wc в Unix):
%{
int nchar, nword, nline;
%}
%%
\n {nline++; nchar++;}
[^ \t\n]+ {nword++, nchar += yyleng;}
{nchar++;}
%%
int main(void) {
yylex();
printf («%d\t % d\t % d\n», nchar, nword, nline);
return 0;
}
Реализация lex в UnixВ целом подсистема LEX для систем UNIX включает следующие файлы:
/usr/ccs/bin/lex;
lex.yy.c;
/usr/ccs/lib/lex/ncform;
/usr/lib/libl.a;
/usr/lib/libl.so.
В каталоге /usr/ccs/lib/lex имеется файл-заготовка ncform, который LEX используется для построения ЛА. Этот файл является уже готовой программой лексического анализа. Но в нем не определены действия, которые необходимо выполнять при распознавании лексем, отсутствуют и сами лексемы, не сформированы рабочие массивы и т.д. С помощью команды lex файл ncform достраивается. В результате мы получаем файл со стандартным именем lex.yy.c. Если LEX-программа размещена в файле program.l, то для получения ЛА с именем program необходимо выполнить следующий набор команд:
lex program.l
cc lex.yy.c – ll – o program
Если имя входного файла для команды lex не указано, то будет использоваться файл стандартного ввода. Флаг – ll требуется для подключения /usr/ccs/lib/libl.a – библиотеки LEX. Если необходимо получить самостоятельную программу, как в данном случае, подключение библиотеки обязательно, поскольку из нее подключается главная функция main. В противном случае, если имеется необходимость включить ЛА в качестве функции в другую программу (например, в программу синтаксического анализа), эту библиотеку необходимо вызвать уже при сборке. Тогда, если main определен в вызывающей ЛА программе, редактор связей не будет подключать раздел main из библиотеки LEX.
Общий формат вызова команды lex:
lex [-ctvn – V – Q [y|n]] [file]
Флаги:
– c – включает фазу генерации Си-файла (устанавливается по умолчанию);
– t – поместить результат в стандартный файл вывода, а не в файл lex.yy.c;
– v – вывести размеры внутренних таблиц;
– n – не выводить размеры таблиц (устанавливается по умолчанию);
– V – вывести информацию о версии LEX в стандартный файл ошибок;
– Q – вывести (Qy) либо не выводить (Qn, устанавливается по умолчанию) информацию о версии в файл lex.yy.c.
YACC – Yet Another Compiler CompilerГрамматики для yacc описываются с помощью Формы Бэкуса-Наура (Backus Naur Form, BNF)
Эту технику была ввели John Backus и Peter Naur и использовали ее, чтобы описать ALGOL60. Грамматика BNF может быть использована для описания контекстно-свободных языков. Большинство конструкций современного программирования могут быть представлены в BNF.
Например, грамматика для выражения, которое умножает и складывает числа может быть представлена следующим образом:
E -> E + E
E -> E * E
E -> id
Были специфицированы 3 правила продукции. Термы, которые могут быть с левой стороны правил продукции(lhs) продукции, такие как E (expression), являются нетерминальными символами. Термы, такие как id (identifier) являются терминальными символами (токенами, возвращаемыми lex) и могут быть только с правой стороны правил продукции(rhs).
Эта грамматика определяет, что выражение может быть суммой двух выражений, произведением двух выражений или идентификатором. Можно использовать эту грамматику, чтобы сгенерировать выражения:
E -> E * E (r2)
-> E * z (r3)
-> E + E * z (r1)
-> E + y * z (r3)
-> x + y * z (r3)
На каждом шаге мы расширяем терм, заменяем левую часть продукции соответствующей правой частью. Числа справа показывают какое правило применяется. Чтобы распознать выражение, необходима обратная операция. Кроме того, что необходимо начинать с единичного нетерминального (начального символа), и генерировать выражение из грамматики. Это известно под термином восходящий (bottom-up) анализ и использование стека для хранения термов. Вот некоторый пример в обратном порядке:
1. x + y * z shift
2 x. + y * z reduce(r3)
3 E. + y * z shift
4 E +. y * z shift
5 E + y. * z reduce(r3)
6 E + E. * z shift
7 E + E *. z shift
8 E + E * z. reduce(r3)
9 E + E * E. reduce(r2) emit multiply
10 E + E. reduce(r1) emit add
11 E. accept
Структура YACC-программыКаждый файл спецификаций состоит из трех секций: объявления, (грамматические) правила, и программы. Секции разделяются символами двойного процента «%%». Другими словами, полный файл спецификации выглядит как:
описания
%%
правила
%%
программы
Секция объявлений может быть пуста. Более того, если секция программ опущена, то вторая метка «%%» также может быть опущена; таким образом, минимальная разрешенная спецификация Yacc есть:
%%
правила
Пример простейшей программы на YACC'e:
%token name
%start e
%%
e: e '+' m | e '-' m | m;
m: m '*' t | m '/' t | t;
t: name | ' (' e ')';
%%
Секция правил содержит информацию о том, что символ name является лексемой (терминалом) грамматики, а символ e – ее начальным нетерминалом.
Грамматика записана обычным образом – идентификаторы обозначают терминалы и нетерминалы, символьные константы типа '+' '-' – терминалы. Символы: |; – принадлежат метаязыку и читаются «есть по определению», «или» и «конец правила» соответственно.
Семантические действияКаждому правилу можно поставить в соответствие некое действие, которое будет выполняться всякий раз, как это правило будет распознано. Действия могут возвращать значения и могут пользоваться значениями, возвращенными предыдущими действиями. Более того, лексический анализатор может возвращать значения для токенов (дополнительно), если хочется. Действие – это обычный оператор языка Си, который может выполнять ввод, вывод, вызывать подпрограммы и изменять глобальные переменные.
Действия, состоящие из нескольких операторов, необходимо заключать в фигурные скобки. Например:
A: ' (' B ')'
{hello (1, «abc»);}
и
XXX: YYY ZZZ
{printf («a message\n»); flag = 25;}
являются грамматическими правилами с действиями.
Чтобы обеспечить связь действий с анализатором, используется спецсимвол «доллар» ($). Чтобы вернуть значение, действие обычно присваивает его псевдопеременной $$. Например, действие, которое не делает ничего, но возвращает единицу:
{$$ = 1;}
Чтобы получить значения, возвращенные предыдущими действиями и лексическим анализатором, действие может использовать псевдопеременные $1, $2 и т.д., которые соответствуют значениям, возвращенным компонентами правой части правила, считая слева направо. Таким образом, если правило имеет вид:
A: B C D;
то $2 соответствует значению, возвращенному нетерминалом C, a $3 – нетерминалом D. Более конкретный пример:
expr: ' (' expr ')';
Значением, возвращаемым этим правилом, обычно является значение выражения в скобках, что может быть записано так:
expr: ' (' expr ')'
{$$ = $2;}
По умолчанию, значением правила считается значение, возвращенное первым элементом ($1). Таким образом, если правило не имеет действия, Yacc автоматически добаляет его в виде $$=$1;, благодаря чему для правила вида
A: B;
обычно не требуется самому писать действие.
В вышеприведенных примерах все действия стояли в конце правил, но иногда желательно выполнить что-либо до того, как правило будет полностью разобрано. Для этого Yacc позволяет записывать действия не только в конце правила, но и в его середине. Значение такого действия доступно действиям, стоящим правее, через обычный механизм:
A: B
{$$ = 1;}
C
{x = $2; y = $3;}
;
В результате разбора иксу (x) присвоится значение 1, а игреку (y) – значение, возвращенное нетерминалом C. Действие, стоящее в середине правила, считается за его компоненту, поэтому x=$2 присваивает X-у значение, возвращенное действием $$=1;
Для действий, находящихся в середине правил, Yacc создает новый нетерминал и новое правило с пустой правой частью и действие выполняется после разбора этого нового правила. На самом деле Yacc трактует последний пример как
NEW_ACT: /* empty */ /* НОВОЕ ПРАВИЛО */
{$$ = 1;}
;
A: B NEW_ACT C
{x = $2; y = $3;}
;
В большинстве приложений действия не выполняют ввода / вывода, а конструируют и обрабатывают в памяти структуры данных, например дерево разбора. Такие действия проще всего выполнять вызывая подпрограммы для создания и модификации структур данных. Предположим, что существует функция node, написанная так, что вызов node (L, n1, n2) создает вершину с меткой L, ветвями n1 и n2 и возвращает индекс свежесозданной вершины. Тогда дерево разбора может строиться так:
expr: expr '+' expr
{$$ = node ('+', $1, $3);}
Программист может также определить собственные переменные, доступные действиям. Их объявление и определение может быть сделано в секции объявлений, заключенное в символы%{и%}. Такие объявления имеют глобальную область видимости, благодаря чему доступны как действиям, так и лексическому анализатору. Например:
%{
int variable = 0;
%}
Такие строчки, помещенные в раздел объявлений, объявляют переменную variable типа int и делают ее доступной для всех действий. Все имена внутренних переменных Yacca начинаются c двух букв y, поэтому не следует давать своим переменным имена типа yymy.
Лексический анализПрограммист, использующий Yacc должен написать сам (или создать при помощи программы типа Lex) внешний лексический анализатор, который будет читать символы из входного потока (какого – это внутреннее дело лексического анализатора), обнаруживать терминальные символы (токены) и передавать их синтаксическому анализатору, построенному Yaccом (возможно вместе с неким значением) для дальнейшего разбора. Лексический анализатор должен быть оформлен как функция с именем yylex, возвращающая значение типа int, которое представляет собой тип (номер) обнаруженного во входном потоке токена. Если есть желание вернуть еще некое значение (например номер в группе), оно может быть присвоено глобальной, внешней (по отношению к yylex) переменной по имени yylval.
Лексический анализатор и Yacc должны использовать одинаковые номера токенов, чтобы понимать друг друга. Эти номера обычно выбираются Yaccом, но могут выбираться и человеком. В любом случае механизм define языка Си позволяет лексическому анализатору возвращать эти значения в символическом виде. Предположем, что токен по имени DIGIT был определен в секции объявлений спецификации Yaccа, тогда соответствующий текст лексического анализатора может выглядеть так:
yylex()
{
extern int yylval;
int c;
…
c = getchar();
…
switch (c) {
…
case '0':
case '1':
…
case '9':
yylval = c – '0';
return DIGIT;
…
}
…
Вышеприведенный фрагмент возвращает номер токена DIGIT и значение, равное цифре. Если при этом сам текст лексического анализатора был помещен в секцию программ спецификации Yacca – есть гарантия, что идентификатор DIGIT был определен номером токена DIGIT, причем тем самым, который ожидает Yacc.
Такой механизм позволяет создавать понятные, легкие в модификации лексические анализаторы. Единственным ограничением является запрет на использование в качестве имени токена слов, зарезервированых или часто используемых в языке Си слов. Например, использование в качестве имен токенов таких слов как if или while, почти наверняка приведет к возникновению проблем при компиляции лексического анализатора. Кроме этого, имя error зарезервировано для токена, служащего делу обработки ошибок, и не должно использоваться.
Как уже было сказано, номера токенов выбираются либо Yaccом, либо человеком, но чаще Yaccом, при этом для отдельных символов (например для (или;) выбирается номер, равный ASCII коду этого символа. Для других токенов номера выбираются начиная с 257.
Для того, чтобы присвоить токену (или даже литере) номер вручную, необходимо в секции объявлений после имени токена добавить положительное целое число, которое и станет номером токена или литеры, при этом необходимо позаботиться об уникальности номеров. Если токену не присвоен номер таким образом, Yacc присваивает ему номер по своему выбору.
По традици, концевой маркер должен иметь номер токена, равный, либо меньший нуля, и лексический анализатор должен возвращать ноль или отрицательное число при достижении конца ввода (или файла).
Очень неплохим средством для создания лексических анализаторов является программа Lex. Лексические анализаторы, построенные с ее помощью прекрасно гармонируют с синтаксическими анализаторами, построенными Yaccом. Lex можно легко использовать для построения полного лексического анализатора из файла спецификаций, основанного на системе регулярных выражений (в отличие от системы грамматических правил для Yacca), но, правда, существуют языки (например Фортран) не попадающие ни под какую теоретическю схему, но для них приходится писать лексический анализатор вручную.
Реализация Yacc в Unix YACC(1)НАЗВАНИЕ
yacc – еще один компилятор компиляторов
СИНТАКСИС
yacc [-v] [-d] [-l] [-t] грамматика
ОПИСАНИЕ
Команда yacc преобразует контекстно-свободную грамматику в набор таблиц для простого LR(1) – разбора. Грамматика может содержать неоднозначности; чтобы их преодолеть, используются заданные правила предшествования.
Выходной файл y.tab.c преобразуется C-компилятором в программу yyparse, которую нужно скомпоновать с программой лексического анализа yylex, а также с подпрограммой main и подпрограммой обработки ошибок yyerror. Эти подпрограммы должны быть предоставлены пользователем; при порождении лексических анализаторов полезен lex(1).
Допустимые опции:
| -v | Сгенерировать файл y.output, который содержит описание таблиц разбора с указанием конфликтных ситуаций, вызванных неоднозначностями грамматики. |
| -d | Сгенерировать файл y.tab.h, который содержит определения #define, связывающие заданные пользователем «имена лексем» с назначенными программой yacc «кодами лексем», что позволяет использовать коды лексем в исходных файлах, отличных от y.tab.c. |
| -l | Не вставлять в программу y.tab.c операторы #line. Рекомендуется использовать только после того, как грамматика и другие компоненты полностью отлажены. |
| -t | При помощи средств условной компиляции в программу y.tab.c всегда вставляются отладочные операторы, однако по умолчанию компилятор их пропускает. Если указана опция – t, то при отсутствии других указаний отладочные операторы будут скомпилированы. Вне зависимости от использования опции – t компиляцией отладочных операторов управляет переменная препроцессора YYDEBUG. Если YYDEBUG имеет ненулевое значение, отладочные операторы компилируются; при нулевом значении они пропускаются. Когда программа сформирована без отладочного кода, ее размер меньше и скорость выполнения несколько выше. |
ФАЙЛЫ
y.output
y.tab.c
y.tab.h Определение кодов лексем.
yacc.tmp Временный файл.
yacc.debug Временный файл.
yacc.acts Временный файл.
/usr/lib/yaccpar Прототип алгоритма разбора для
C-программ.
СМ. ТАКЖЕ
lex(1).
ДИАГНОСТИКА
В стандартный протокол направляется информация о числе конфликтных ситуаций типа «свертка-свертка» и «перенос-свертка»; более подробные сообщения содержатся в файле y.output. Аналогичным образом сообщается о продукциях, недостижимых из начального символа грамматики.
ОГРАНИЧЕНИЯ
Так как имена файлов фиксированы, в данном каталоге в каждый момент времени может быть активным только один процесс yacc
Постановка задачиРеализовать:
– транслятор с языка математических выражений на язык деревьев вывода
– интерпретатор языка деревьев вывода
К разрабатываемым программам предъявляются следующие требования:
– реализация осуществляется на языке C++.
– функциональность транслятора и интерпретатора должна быть реализована в виде класса (Класс Analyser).
Должна быть обеспечена поддержка следующей функциональности:
– вычисление математических выражений с любой степенью вложенности
– поддержка в выражениях чисел с плавающей точкой
– математические операции:
– «+», «–» (бинарный / унарный), «*», «/», «^» (возведение в степень)
– поддержка функций:
log(), exp(), sin(), cos(), tan(), acos(), asin(), atan()
– игнорирование пробелов, символов табуляции и переноса строки
– оптимизация синтаксического дерева
– объединение проходов синтаксического и лексического анализаторов в один проход. (Отсюда название «однопроходный / двухпроходный». Второй проход опциональный – это проход оптимизатора.)
– запись / чтение синтаксического дерева в файл/из файла Транслятор Грамматика синтаксического анализатора
Грамматика описана в виде формы Бэкуса-Наура, расширенной метасимволами.
Исходная грамматикаEXPR-> [<+>|<->] EXPR<+>TERM | [<+>|<->] EXPR<->TERM | [<+>|<->] TERM
TERM-> TERM<*>FACTOR | TERM</>FACTOR | FACTOR
FACTOR-> FACTOR<^>POW{<^>} 0 | POW
POW-> <number> | <var_name> | <(>EXPR<)> | FUNC<(>EXPR<)>
FUNC-> <log> | <exp> | <sin> | <cos> | <tan> | <acos> | <asin> | <atan>
Пояснения:
1) <e> это пустой символ
3) {DIGIT} n – это итерация DIGIT, где n – натуральное число
4) {<^>} 0 это отсутствие двойного возведения в степень
5) имена переменных не должны совпадать с именами функций, поддерживаемых интерпретатором.
Данная грамматика позволяет разбирать математические выражения с учетом приоритетов математических операций. Эквивалентная грамматика без левой рекурсии
EXPR-> [<+>|<->] TERM MORETERMS
MORETERMS-> <+>TERM MORETERMS | <->TERM MORETERMS | <e>
TERM-> FACTOR MOREFACTORS
MOREFACTORS-> <*>FACTOR MOREFACTORS | </>FACTOR MOREFACTORS | <e>
FACTOR-> POW MOREPOWS
MOREPOWS-> <^>POW{<^>} 0 | <e>
POW-> <number> | <var_name> | <(>EXPR<)> | FUNC<(>EXPR<)>
FUNC-> <log> | <exp> | <sin> | <cos> | <tan> | <acos> | <asin> | <atan> Лексический анализатор
Лексический анализатор выделяет лексемы на основе конца строки и следующих терминальных символов, одновременно являющихся разделителями:
+, -, *, /, ^, (,)
Синтаксический анализаторСинтаксический анализатор производит обработку потока входных лексем методом предиктивного(предсказывающего) анализа, который является специальным видом метода рекурсивного спуска.
В данном анализаторе нетерминалам грамматики ставится в соответствие функция-обработчик. Смыслом предиктивного анализа является однозначное определение следующей вызываемой функции-обработчика на основе текущей лексемы.
Соответствие нетерминалов функциям-обработчикам:
POW : powNT()
FACTOR : factorNT()
TERM : termNT()
EXPR : exprNT()
Взаимодействие анализаторовВ Analyser реализовано объединение проходов лексического и синтаксического анализаторов в один проход. При просмотре следующей лексемы синтаксическим анализатором вызывается функция, реализующая извлечение лексемы из входной строки, содержащей математическое выражение.
В данном случае это более эффективный подход с точки зрения занимаемой оперативной памяти. Если делать полный проход лексического анализатора, то в оперативной памяти, помимо входной строки с математическим выражением, будет содержаться вектор лексем, который практически повторяет содержимое входной строки. Поскольку синтаксическому анализатору не требуется обозревать несколько лексем одновременно, то наличие вектора лексем не имеет смысла, значит объединение проходов анализаторов в один проход логически обосновано.
ОптимизаторОптимизатор делает проход по синтаксическому дереву и уменьшает количество его узлов за счет вычисления константных подвыражений с любыми знаками и функциями, и для операций +, -, *, если подвыражения частично являются константными.
Если входное выражение не оптимально, содержит переменную и требуется вычисление этого выражения на некотором множестве действительных чисел, мощность которого больше 1, то повышение скорости выполнения программы очевидно.
Алгоритм оптимизации1) Просмотр текущего узла
2) Проверка этого узла на константность:
да:
– вычисление его значения
– освобождение памяти, выделенной для поддерева с вершиной в этом узле
– создание нового узла, содержащего вычисленную константу
нет:
– переход к шагу 3)
3) Операция этого узла + или * (операция «–» не рассматривается, т. к. при построении синтаксического дерева бинарный «–» заменяется унарным «–». Пример: 1–2 преобразуется в 1+(-2)):
да:
– формирование векторов указателей на константные и неконстантные (включая не непосредственные) подузлы данного узла с той же операцией. Если встречается подузел, операция которого отличается от операции данного узла, то:
– добавление указателя на этот подузел в вектор указателей на неконстантные узлы
– переход к шагу 1) для этого подузла
– вычисление результата для вектора указателей на константы
– освобождение памяти, выделенной для узлов, указатели на которые содержатся в векторе указателей на константные узлы
– построение нового поддерева на основе вектора неконстант и вычисленной константы
нет:
– переход к шагу 1) для всех непосредственных подузлов данного узла
Пример оптимизацииИсходное математическое выражение:
(4^2+(2^3*2)^0.5+x*(1+2+3+4+(2*3*4*x)))+((1+2)+sin (x+1+2)) – (log (sin(x))+1)
Формат строки для синтаксического дерева в выводе программы имеет следующий:
(<указатель_на _текущую_вершину>) <список_указателей_на_непосредственные подузлы | значение_подузла> <операция>
или
(<указатель_на _текущую_вершину>) <функция | константа | переменная> [<список_указателей_на_непосредственные подузлы>] [<значение>]
Для этой формулы неоптимизированное синтаксическое дерево имеет вид:
Syntax Tree: (not optimized)
(0x8050da8) left=0x8050d28 right=0x8050d98 op=+
(0x8050d98) right=0x8050d88 op=-
(0x8050d88) left=0x8050d58 right=0x8050d78 op=+
(0x8050d78) CONST=1
(0x8050d58) op=l next=0x8050d48
(0x8050d48) op=s next=0x8050d38
(0x8050d38) VAR=x
(0x8050d28) left=0x8050c38 right=0x8050d18 op=+
(0x8050d18) left=0x8050c88 right=0x8050d08 op=+
(0x8050d08) op=s next=0x8050cf8
(0x8050cf8) left=0x8050cc8 right=0x8050ce8 op=+
(0x8050ce8) CONST=2
(0x8050cc8) left=0x8050c98 right=0x8050cb8 op=+
(0x8050cb8) CONST=1
(0x8050c98) VAR=x
(0x8050c88) left=0x8050c58 right=0x8050c78 op=+
(0x8050c78) CONST=2
(0x8050c58) CONST=1
(0x8050c38) left=0x8050aa8 right=0x8050c28 op=+
(0x8050c28) left=0x8050ab8 right=0x8050c18 op=*
(0x8050c18) left=0x8050b68 right=0x8050c08 op=+
(0x8050c08) left=0x8050be8 right=0x8050bf8 op=*
(0x8050bf8) VAR=x
(0x8050be8) left=0x8050bb8 right=0x8050bd8 op=*
(0x8050bd8) CONST=4
(0x8050bb8) left=0x8050b88 right=0x8050ba8 op=*
(0x8050ba8) CONST=3
(0x8050b88) CONST=2
(0x8050b68) left=0x8050b38 right=0x8050b58 op=+
(0x8050b58) CONST=4
(0x8050b38) left=0x8050b08 right=0x8050b28 op=+
(0x8050b28) CONST=3
(0x8050b08) left=0x8050ad8 right=0x8050af8 op=+
(0x8050af8) CONST=2
(0x8050ad8) CONST=1
(0x8050ab8) VAR=x
(0x8050aa8) left=0x80509e8 right=0x8050a98 op=+
(0x8050a98) left=0x8050a68 right=0x8050a88 op=^
(0x8050a88) CONST=0.5
(0x8050a68) left=0x8050a38 right=0x8050a58 op=*
(0x8050a58) CONST=2
(0x8050a38) left=0x8050a08 right=0x8050a28 op=^
(0x8050a28) CONST=3
(0x8050a08) CONST=2
(0x80509e8) left=0x80509b8 right=0x80509d8 op=^
(0x80509d8) CONST=2
(0x80509b8) CONST=4
nodes num: 47
Как видно из вывода, количество узлов в синтаксическом дереве равно 47.
После прохода оптимизатора дерево имеет следующий вид:
Syntax Tree: (optimized)
(0x8050da8) left=0x8050aa8 right=0x8050c28 op=+
(0x8050c28) left=0x8050e08 right=0x8050ab8 op=*
(0x8050ab8) VAR=x
(0x8050e08) left=0x8050b08 right=0x8050c08 op=+
(0x8050c08) left=0x8050b88 right=0x8050bf8 op=*
(0x8050bf8) VAR=x
(0x8050b88) CONST=24
(0x8050b08) CONST=10
(0x8050aa8) left=0x80509e8 right=0x8050d08 op=+
(0x8050d08) op=s next=0x8050cf8
(0x8050cf8) left=0x8050ce8 right=0x8050c98 op=+
(0x8050c98) VAR=x
(0x8050ce8) CONST=3
(0x80509e8) left=0x80509b8 right=0x8050d98 op=+
(0x8050d98) right=0x8050d58 op=-
(0x8050d58) op=l next=0x8050d48
(0x8050d48) op=s next=0x8050d38
(0x8050d38) VAR=x
(0x80509b8) CONST=22
nodes num: 19
Это дерево соответствует формуле:
22-log (sin(x))+sin (3+x)+x*(10+24*x)
Как видно из вывода, количество узлов в синтаксическом дереве равно 19, против 47, что приводит к повышению скорости выполнения программы.
Сохранение синтаксического дерева в файл
Эта функциональность добавлена для ускорения работы с математическими выражениями. После трансляции математического выражения в синтаксическое дерево, есть возможность сохранить его в том виде, в котором оно находится в оперативной памяти, в файл на жесткий диск. Т. о. если требуется вычислить несколько математических выражений несколько раз, то их можно оттранслировать один раз, сохранить в файлы, а потом извлекать их в виде, готовом для интерпретации, не тратя время на лексический и синтаксический анализ.
Сохранение синтаксического дерева начинается с корня дерева и обходит дочерние узлы слева – направо с их последующим сохранением.
Аналогичным образом происходит извлечение дерева из файла.
ИнтерпретаторИнтерпретатор выполняет извлечение из файла синтаксического дерева, являющегося результатом выполнения транслятора.
После извлечения дерева интерпретатор совершает его обход. Результатом работы интерпретатора является число, в точности соответствующее значению математического выражения, которому, в свою очередь, эквивалентно извлеченное синтаксическое дерево.
Заключение
В работе были рассмотрены теоретические основы построения трансляторов.
Результатом работы являются:
– класс Analyser, реализующий заявленную функциональность
– транслятор с языка математических выражений на язык деревьев вывода
– интерпретатор языка деревьев вывода
Похожие работы
... и определяю- щем вхождении идентификатора. КОНТЕКСТНЫЕ УСЛОВИЯ ЧЕТВЕРТОГО ТИПА Некоторые логические ограничения, которые относятся к реа- лизации той или иной версии транслятора. Массив может быть с неограниченным размером. ЛЕКЦИЯ 17 ПРОГРАММНЫЕ ГРАММАТИКИ Правила вывода этих грамматик имеют тот же вид, что и у классических, однако в ...
0 комментариев