Математические основы
Преобразовать выражение в соответствии с операциями отрицания
Слова, задающие сущности изучаемого мира
Если для всех xÎM F оценивается как истина, то истиной является ("x)F(x)
Математическая индукция
Рекурсия
Компьютерное задание
Практические задания
Практические задания
Доказательство от противного
Скалемовская нормальная форма
В проверке содержит или не содержит S пустое предложение
По различию используемых символов
Стратегия предпочтения одночленов
Навигация
Логическое и функциональное программирование
Логическое и функциональное программирование
119487
знаков
12
таблиц
22
изображения
ЛОГИЧЕСКОЕ И ФУНКЦИОНАЛЬНОЕ ПРОГРАММИРОВАНИЕ
Введение
Целью логического и функционального программирования является вывод решений и они тесно связаны с задачами, решаемыми в искусственном интеллекте и экспертных системах (ЭС). На начальном этапе развития систем искусственного интеллекта (СИИ) и ЭС даже выделился целый класс специализированных языков программирования: языки логического и функционального программирования.
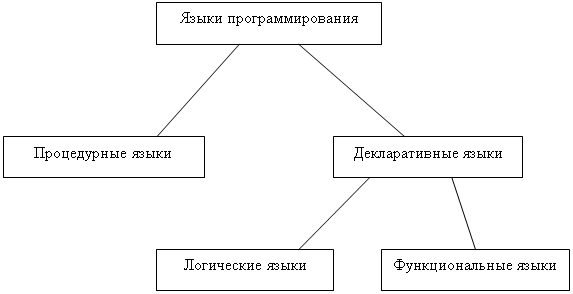
Процедурная программа состоит из последовательности операторов и предложений, управляющих последовательностью их выполнения. В основе такого программирования лежат взятие значения какой-то переменной, совершение над ним действия и сохранение нового значения с помощью оператора присваивания, и так до тех пор пока не будет получено желаемое окончательное значение.
Функциональная программа состоит из совокупности определений функций. Функции, в свою очередь, представляют собой вызовы других функций и предложений, управляющих последовательностью вызовов. Каждый вызов возвращает некоторое значение и вызвавшую ее функцию, вычисление которой после этого продолжается. Этот процесс повторяется до тех пор, пока запустившая процесс функция не вернет результат пользователю.
В логических языках программирования для решения задачи достаточно описания структуры и условий этой задачи. Поскольку последовательность и способ выполнения программы не фиксируется, как при описании алгоритма, программы могут в принципе работать в обоих направлениях, то есть программа может как на основе исходных данных вычислить результаты, так и по результатам – исходные данные.
Наиболее известными языками функционального программирования являются ЛИСП и РЕФАЛ, а логического – Пролог. Однако, с развитием языков программирования (в частности, с появлением объектно-ориентированных языков) и баз данных область их применения сузилась. Так ЛИСП используется как оболочка Автокад, а РЕФАЛ как средство для построения метаязыков и метакомпиляторов.
Поэтому в дальнейшем внимание будет уделено не рассмотрению конкретных языков функционального и логического программирования, а подходам, лежащим в основе их реализации и являющимися базовыми при создании систем принятия решений.
ЛИСП и Пролог в свое время являлись базовыми для создания экспертных систем. Поэтому, для того чтобы наглядно представить какой круг задач решается с помощью логического и функционального программирования, рассмотрим задачи, возникающие в ЭС. Прежде всего, это задачи прямого и обратного вывода.
Прямой и обратный вывод
При использовании прямой цепочки рассуждений решается задача по известным условиям найти последствия. Обратная цепочка рассуждений применяется для того, чтобы по известным результатам найти причины их вызвавшие.
Такие задачи часто записывают в терминах продукционных систем представления знаний, в которых знания записываются в виде продукций/правил, имеющих вид:
Если <условие>, То <вывод>.
Рассмотрим сначала построение обратной цепочки рассуждений. Обратная цепочка рассуждений всегда начинается со следствия (часть То правила). Если в правилах, относящихся к проблемной области, не удается найти условную часть с выполняющимися условиями, необходимо ввести дополнительную информацию. Цепочка означает процедуру логической связи ряда правил.
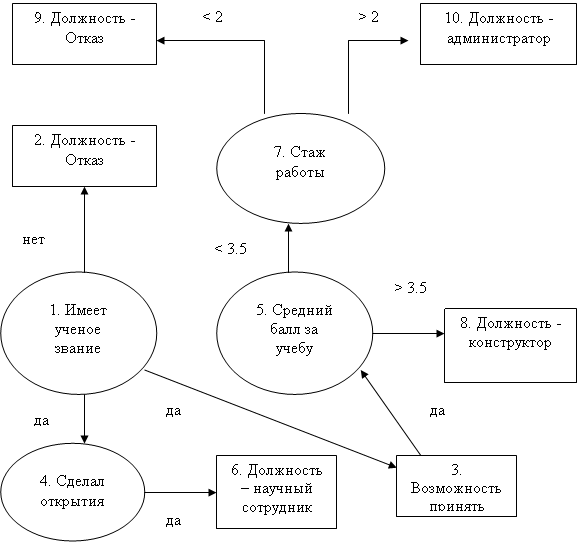
Для представления таких задач принято использовать дерево решений - специальную диаграмму для представления возможных решений. Дерево решений состоит из вершин двух типов. Вершины решений, содержащие вопросы, обозначаются окружностями. Цели или логические выводы обозначаются прямоугольниками. Вершины нумеруются. Каждая вершина может иметь не более одного входа. Рассмотрим простейший пример с приемом на работу, часто используемый в литературе [1].
Дерево решений будем хранить в следующей таблице [2]:
Таблица дерева решений.
| № вершины | Переменная | Значение | Исходная вершина | Дуга | Тип вершины |
| 1 | Звание | - | - | - | решение |
| 2 | Должность | Отказ | 1 | нет | вывод |
| 3 | Возможность | да | 1 | да | вывод |
| 4 | Открытия | - | 1 | да | решение |
| 5 | Средний балл | - | 3 | да | решение |
| 6 | Должность | Научный сотрудник | 4 | да | вывод |
| 7 | стаж | - | 5 | < 3.5 | решение |
| 8 | должность | конструктор | 5 | > 3.5 | вывод |
| 9 | должность | Отказ | 7 | < 2 | вывод |
| 10 | должность | администратор | 7 | > 2 | вывод |
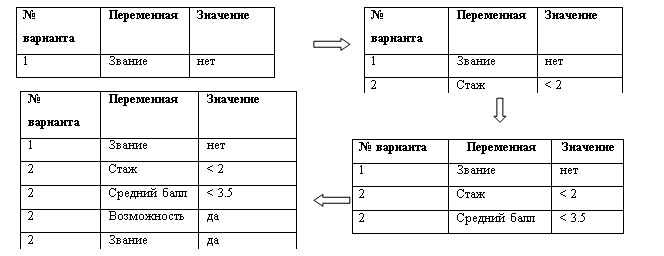
Для сохранения результатов будем использовать таблицу вывода (в начальный момент таблица пуста).
Таблица вывода| № варианта | Переменная | Значение |
1. Определить переменную логического вывода и ее значение.
2. Найти первое вхождение этой переменной в таблицу дерева решений с заданным значением и типом вершины «вывод». Если переменная не найдена – неудача. Установить переменную var = 1.
3. Выбрать исходную по отношению к полученной вершине вершину. Если ее нат, перейти к шагу 5. Если есть, записать в таблицу вывода новую строку со значениями полей № варианта = var, Переменная = Переменная из исходной вершины таблицы дерева решений, Значение = Дуга текущей вершины.
4. Сделать исходную вершину текущей. Перейти к шагу 3.
5. Найти следующее вхождение переменной вывода в таблицу дерева решений. Если нет, конец, иначе var = var + 1. Перейти к шагу 3.
Пусть отказано в приеме на работу. Тогда в ходе выполнения алгоритма таблица вывода будет формироваться следующим образом.
Здесь пропущена таблица вывода на предпоследнем этапе.
Механизм, основанный на прямой цепочке рассуждений, функционирует следующим образом:
1. Вводится условие.
2. Для каждой ситуации система ищет в базе данных (знаний) правила, в условной части которых содержится соответствующее условие.
3. В соответствии с констатирующей частью (частью ТО) каждое правило может генерировать новые ситуации, которые добавляются к уже существующим.
4. Система обрабатывает каждую вновь сгенерированную ситуацию. При наличии хотя бы одной такой ситуации выполняются действия, начиная с шага 2. Рассуждения заканчиваются, когда больше нет необработанных ситуаций
Алгоритм CLS
Для построения деревьев решений часто используется алгоритм CLS. Этот алгоритм циклически разбивает обучающие примеры на группы/классы в соответствии с переменной, имеющей наибольшую классифицирующую силу. Каждое подмножество примеров (объектов), выделяемое такой переменной, вновь разбивается на классы с использованием следующей переменной с наибольшей классифицирующей способностью и т.д. Разбиение заканчивается, когда в подмножестве оказываются объекты лишь одного класса. В ходе процесса образуется дерево решений. Пути движения по этому дереву с верхнего уровня на самые нижние определяют логические правила в виде цепочек конъюнкций.
Рассмотрим следующий пример. Проводится антропологический анализ лиц людей двух национальностей по 16 признакам.
Х1 (голова) – круглая – 1, овальная – 0.
Х2 (уши) – оттопыренные – 1, прижатые – 0.
Х3 (нос) – круглый –1, длинный – 0.
Х4 (глаза) – круглые – 1, узкие – 0.
Х5 (лоб) – с морщинами –1, без морщин – 0.
Х6(носогубная складка) – есть – 1, нет – 0.
Х7(губы) – толстые – 1, тонкие – 0.
Х8 (волосы) – есть – 1, нет – 0.
Х9(усы) – есть – 1, нет – 0.
Х10 (борода) – есть – 1, нет – 0.
Х11(очки) – есть – 1, нет – 0.
Х12(родинка) – есть – 1, нет – 0.
Х13(бабочка) – есть – 1, нет – 0.
Х14(брови) – поднятые вверх – 1, опущенные – 0.
Х15(серьга) – есть – 1, нет – 0.
Х16(трубка) – есть – 1, нет – 0.
Пусть имеется 16 объектов. Объекты с номерами 1 – 8 относятся к первому классу, 9 – 16 ко второму классу. Далее приводится таблица со значениями признаков для этих объектов.
| № | X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | X9 | X10 | X11 | X12 | X13 | X14 | X15 | X16 | Кл. |
| 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 |
| 2 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 |
| 3 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 |
| 4 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 |
| 5 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 |
| 6 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 |
| 7 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 |
| 8 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 |
| 9 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 2 |
| 10 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 2 |
| 11 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 2 |
| 12 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 2 |
| 13 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 2 |
| 14 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 2 |
| 15 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 2 |
| 16 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 2 |
Объекты для этой таблицы (надо нарисовать).
Основное требование к математическому аппарату обнаружения закономерностей в данных заключается в интерпретации результатов. Правила, выражающие закономерности, формулируются на языке логических высказываний:
ЕСЛИ А ТО В,
ЕСЛИ (условие1) И (условие2) И … И (условиеN) ТО (условиеN+1),
где условиеi может быть Xi =C1, Xi < C2, Xi > C3, C4 < Xi < C5 и т.д. Здесь Xi - переменная, Cj – константа.
Так классификация лиц в рассматриваемом примере может быть произведена с помощью четырех логических правил:
1. ЕСЛИ (голова овальная) И (есть носогубная складка) И (есть очки) И (есть трубка) ТО (класс1).
2. ЕСЛИ (глаза круглые) И (лоб без морщин) И (есть борода) И (есть серьга) ТО (класс1)
3. ЕСЛИ (нос круглый) И (лысый) И (есть усы) И (брови подняты вверх) ТО (класс2).
4. ЕСЛИ (оттопыренные уши) И (толстые губы) И (нет родинки) И (есть бабочка) ТО (класс2).
Математическая запись этих правил выглядит следующим образом:
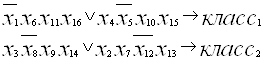
Такие правила имеют две основных характеристики: точность и полноту.
Точность правила – это доля случаев, когда правило подтверждается, среди всех случаев его применения (доля случаев В среди случаев А).
Полнота – это доля случаев, когда правило подтверждается, среди всех случаев, когда имеет место объяснимый исход (доля случаев А среди случаев В).
Правила могут иметь какие угодно сочетания точности и полноты. За исключением одного случая, если точность равна нулю, то равна нулю и полнота, и наоборот.
Точное, но неполное правило: Люди смертны (А – человек, В – смертен).
Неточное, но полное правило: Студенты посещают занятия (А – студент, В - посещает).
Методы поиска логических закономерностей в данных обращаются к информации не только в отдельных признаках, но и в сочетании признаков. Это основное преимущество этих методов перед многими другими методами в ряде случаев.
Вернемся к примеру.
На первом шаге определяется признак с наибольшей дискриминирующей силой. Для этого определяется отношение вхождения объектов в разные классы в соответствии со значениями разных признаков:
| Признаки | Х1 | Х2 | Х3 | Х4 | Х5 | Х6 | Х7 | Х8 | Х9 | Х10 | Х11 | Х12 | Х13 | Х14 | Х15 | Х16 |
| Кл1/Кл2 | 3/3 | 4/6 | 4/6 | 5/5 | 3/3 | 6/4 | 4/6 | 3/3 | 5/5 | 6/4 | 6/4 | 3/3 | 5/5 | 4/6 | 4/6 | 5/5 |
Здесь одинаковой и максимальной силой обладают сразу семь признаков: Х2, Х3, Х6, Х7, Х10, Х11, Х14, Х15. Поэтому случайным образом выбираем один из них в качестве ведущего. Пусть это будет Х6. От этого признака отходит две ветви. Первая для значения Х6 = 0, а вторая – для Х6 = 1.
| Объекты | Признаки | |||||||||||||||
| Х1 | Х2 | Х3 | Х4 | Х5 | Х6 | Х7 | Х8 | Х9 | Х10 | Х11 | Х12 | Х13 | Х14 | Х15 | Х16 | |
| 2 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 |
| 7 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 |
| 12 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 |
| 13 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 |
| 14 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 |
| 16 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 |
| 2/2 | 1/3 | 1/3 | 2/3 | 2/2 | 1/4 | 1/4 | 1/2 | 1/3 | 2/0 | 1/3 | 1/1 | 1/2 | 1/2 | 2/3 | 1/3 | |
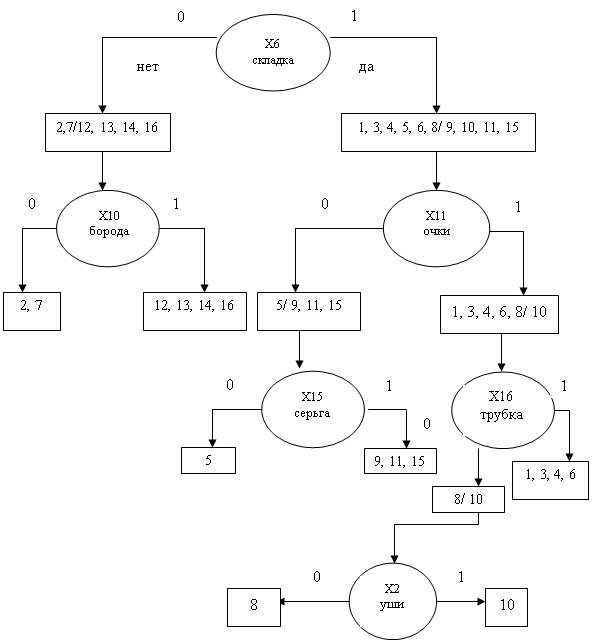
Для ветви Х6 = 0 окончательное решение дает признак Х10. Он принимает значение 1 на объектах 2 и 7 из первого класса и значение 0 на объектах 12, 13, 14 и 16 второго класса. Ветвь Х6 = 1 устроена значительно более сложно и требует дополнительных ветвлений. В результате получаем дерево.
Как следует из рисунка дерево логического вывода, выросшее из признака Х6 имеет 6 исходов. Только два из этих исходов имеет по четыре объекта (полнота 4/8). Один исход группирует три объекта (полнота 3/8), один – два объекта (полнота 2/8) и три исхода включают по одному объекту (полнота 1/8). Отсюда, качество алгоритма не очень высоко, так как обладает малой полнотой. Алгоритм, кроме того, способен приводить к качественным решениям только в случае независимых признаков.
Домашнее заданиеПостроить дерево решений для проблемной области, заданной преподавателем, и построить цепочки прямых и обратных рассуждений для различных ситуаций.
Компьютерное задание
Реализовать дерево решений, прямой и обратный вывод средствами Access. Для реализации необходимо использовать VBA. В Access 2000 по умолчанию установлена модель данных ADO (ActiveX Data Objects). Для установки MSDE, что соответствует модели данных DAO, используемой в Access 97, необходимо использовать другой файл установки. Необходимо вставить установочный компакт диск и дважды щелкнуть на имени файла SETUPSQL.EXE в папке \Sql\x86\Setup.
Иерархия ADO проще иерархии объектов модели
Объекты ADO предназначены для организации доступа к источникам данных, их редактирования и обновления. Модель ADO включает в себя объекты, необходимые для выполнения следующих задач:
1. Соединение с источником данных.
2. Создание объекта, реализующего команды SQL.
3. Указание столбцов, таблиц и значений в качестве переменных параметров в команде SQL.
4. Выполнение команды SQL.
5. Сохранение результатов выполнения в хеше.
6. Создание виртуального представления в хеше, чтобы пользователь мог сортировать, фильтровать данные в БД и перемещаться по ней.
7. Редактирование данных.
8. Обновление источника данных в соответствии со всеми изменениями сделанными в хеше.
9. Фиксация или отмена изменений, внесенных в ходе транзакции, и последующее закрытие транзакции.
К классам объектов в модели ADO относятся:
· Connection – представляет среду, в которой будет выполняться обмен данными с источником данных. Соединение должно быть установлено до начала выполнения любых других операций.
· Command – способ управления источником данных. Можно удалять, добавлять, обновлять и считывать данные из источника.
· Parameter – представляет переменные компоненты объекта Command. В командах часто необходимо указывать вспомогательные параметры, уточняющие способ выполнения команд. Параметры являются изменяемыми, так что перед выполнением команд их можно модифицировать
· Recordset – служит локальным хешем данных, считанных из источника данных.
· Field – представляет столбец таблицы Recordset. Поле содержит свойства определяющие поле. Пример таких свойств – Type, Value.
· Error – возвращает результат всякий раз, когда в приложении возникает ошибка. Каждый объект Connection имеет отдельное семейство объектов Error.
· Property – определяет объекты Connection, Command, Field, Recordset. Каждый объект ADO обладает набором свойств, задающим объект и управляющим его поведением.
· Collection – служит для объединения сходных объектов в группы.
Обращение к объектам ADO выглядит так:
ADODB. имя_объекта.
При создании нового проекта, Access 2000 загружает только библиотеку объектов ADO. Если необходимо работать с DAO, добавляется библиотека объектов DAO в диалоге Preferences редактора VB. Для открытия VB Editor надо нажать Alt + F11. Диалог Preferences открывается командой меню Tools>References. В этом диалоге надо выбрать DAO 3.6 Object Library.
Для того чтобы связать объект Recordset в модели ADO с данными необходимо:
Dim rst As New ADODB.Recordset
rst.Open SQLVar,CurrentProject.Connection
Здесь SQLVar символьная переменная, в которой определяется набор данных либо как выражение SQL, либо как имя таблицы. Например, если необходимо открыть таблицу с именем Student, вторая строка будет выглядеть:
rst.Open “Student”, CurrentProject.Connection
В случае DAO необходимо создать объектную переменную rst типа Recordset без ADODB, а затем использовать метод OpenRecordset:
Set rst = CurrentDB.OpenRecordset(SQLVar, dbOpenDynaset).
Здесь необходимо быть аккуратным, поскольку написание для объектов Recordset в обеих моделях одинаково.
Для перехода в обеих моделях используются методы Move:
· rst.MoveFirst | MoveLast | MoveNext | MovePrevious | Move n – соответственно : Перейти к первой записи | к последней | к следующей | к предыдущей | на n записей
Метод Find используется при поиске в наборе записей, удовлетворяющих тем или иным условиям.
Переменная_Recordset критерий, Пропустить Строки, Направление Поиска, Старт
Здесь:
· критерий – строковое значение (обязательно в кавычках), определяющее имя столбца (поля), оператор сравнения и искомое значение. Это единственный обязательный параметр.
· Пропустить строки – обозначает число строк, начиная с текущей или стартовой позиции, которое необходимо пропустить перед началом поиска.
· Направление поиска определяет должен ли поиск вестись по направлению к концу набора (adSearchForward) или к началу (adSearchBackward).
· Старт – закладка, обозначающая начальное положение указателя текущей записи при поиске: adBookmarkFirst (1) – первая запись, adBookmarkLast (2) – последняя запись, adBookmarkCurrent (0) – текущая запись.
Dim Rst As New ADODB.Recordset
Rst.Open “Student”, CurrentProject.Connection
Rst.Find “Sgroup = ‘АП51’”
Rst.Close
Значение критерия может быть строкой, числом или датой. Если значение имеет тип даты, то оно заключается в #, например, #11/11/03#.
При обновлении записей с помощью Recordset.Open необходимо установить значения нескольких свойств, определяющих набор данных. Самыми важными из этих свойств являются свойства LockType и CursorType.
LockType определяет право доступа к набору и принимает значения:
· AdLockReadOnly – объект доступен только для чтения (значение по умолчанию).
· AdLockPessimistic – записи блокируются сразу после начала редактирования по одной.
· AdLockOptimistic – устанавливает блокировку при вызове метода Update (используйте этот вариант).
· AdLockBatchOptimistic – разрешает пакетное обновление.
Свойство CursorType определяет тип курсора, применяемый в наборе данных. Его действие подобно определению набора данных в модели DAO. CursorType может принимать одноиз следующих значений:
· AdOpenForwardOnly – набор представляет собой статическую копию данных, пригодную для поиска, но поиск возможен только в направлении к концу набора (значение по умолчанию).
· AdOpenKeySet – позволяет вносить изменения в набор данных, но пользователь видит изменения, внесенные им самим.
· AdOpenDynamic – позволяет вносить изменения. Пользователь видит все результаты изменений. Наименее эффективен, но имеет больше всего возможностей. Поэтому используйте его.
· AdOpenStatic – набор представляет собой статическую копию данных.
Редактирование:
Rst.Open “Student”, CurrentProject.Connection, adOpenDynamic, adLockOptimistic
Rst.MoveFirst
Rst(“YearEnter”) = 2001
Rst.Update
Rst.Close
Обновляется поле YearEnter первой записи.
Добавление записи:
Rst.Open “Student”, CurrentProject.Connection, adOpenDynamic, adLockOptimistic
Rst.AddNew
Rst(“FIO”) = “Петров И.И.”
Rst(“YearEnter”) = 2003
Rst.Update
Ret.Close
Удаление записи:
Rst.Open “Student”, CurrentProject.Connection, adOpenDynamic, adLockOptimistic
Rst.MoveFirst
Rst.Delete adAffectCurrent
Rst.Update
Rst.Close
Похожие работы
... программирование [application programming] — разработка и отладка программ для конечных пользователей, например бухгалтерских, обработки текстов и т. п. Системное программирование [system programming] — разработка средств общего программного обеспечения, в том числе операционных систем, вспомогательных программ, пакетов программ общесистемного назначения, например: автоматизированных систем ...
... разработки программ, но и разработку пакетов прикладных программ. Эти разработки должны обеспечивать высокое качество и вестись примерно так же, как и выпуск промышленной продукции. Достижения компьютерной техники 1. Универсальные настольные ПК Что такое настольный компьютер, объяснять никому не надо — это любимое молодежью устройство, чтобы красиво набирать тексты рефератов, а ...

... набор процедур и функций языков программирования Basic и Pascal, позволяют управлять графическим режимом работы экрана, создавать разнооборазные графические изображения и выводить на экран текстовые надписи. ГЛАВА 2. ГРАФИЧЕСКИЕ ВОЗМОЖНОСТИ ЯЗЫКА ПРОГРАММИРОВАНИЯ В КУРСЕ ИНФОРМАТИКИ БАЗОВОЙ ШКОЛЫ (НА ПРИМЕРЕ BASIC И PASCAL) 2.1 Разработка мультимедиа курса «Графические возможности языков ...
... информационных технологий, которое заключается как в совершенствовании методов организации информационных процессов, так и их реализации с помощью конкретных инструментов – сред и языков программирования. Итогом работы можно считать созданную функциональную модель вычисления неэлементарных функций. Данная модель применима к функциям, если она не задана одной формулой посредством конечного числа ...
0 комментариев