РЕФЕРАТ
На тему: Історія розвитку баз даних
Історія розвитку баз даних
У історії обчислювальної техніки можна прослідкувати розвиток двох основних областей її використання. Перша область — застосування обчислювальної техніки для виконання чисельних розрахунків, які дуже довго або взагалі неможливо проводити уручну. Розвиток цієї області сприяв інтенсифікації методів чисельного вирішення складних математичних завдань, появі мов програмування, орієнтованих на зручний запис чисельних алгоритмів, становленню зворотного зв'язку з розробниками нової архітектури ЕОМ. Характерною особливістю даної сфери застосування обчислювальної техніки є наявність складних алгоритмів обробки, які застосовуються до простих по структурі даним, об'єм яких порівняно невеликий.
Друга область, яка безпосередньо відноситься до нашої теми, — це використання засобів обчислювальної техніки в автоматичних або автоматизованих інформаційних системах. Інформаційна система є програмно-апаратним комплексом, що забезпечує виконання наступних функцій:
надійне зберігання інформації в пам'яті комп'ютера;
виконання специфічних для даного застосування перетворень інформації і обчислень;
надання користувачам зручного і легко освоюваного інтерфейсу.
Зазвичай такі системи мають справу з великими об'ємами інформації, що має достатньо складну структуру. Класичними прикладами інформаційних систем є банківські системи, автоматизовані системи управління підприємствами, системи резервування авіаційних або залізничних квитків, місць в готелях і так далі
Друга область використання обчислювальної техніки виникла декілька пізніше першою. Це пов'язано з тим, що на зорі обчислювальної техніки можливості комп'ютерів по зберіганню інформації були дуже обмеженими. Говорити про надійне і довготривале зберігання інформації можна тільки за наявності пристроїв, що запам'ятовують, зберігають інформацію після виключення електричного живлення. Оперативна (основна) пам'ять комп'ютерів цією властивістю зазвичай не володіє. У перших комп'ютерах використовувалися два види пристроїв зовнішньої пам'яті — магнітні стрічки і барабани. Ємкість магнітних стрічок була достатньо велика, але по своїй фізичній природі вони забезпечували послідовний доступ до даних. Магнітні ж барабани (вони щонайближче до сучасним магнітним дискам з фіксованими головками) давали можливість довільного доступу до даних, але мали обмежений об'єм інформації, що зберігалася.
Ці обмеження не були дуже істотними для чисто чисельних розрахунків. Навіть якщо програма повинна обробити (або провести) великий об'єм інформації, при програмуванні можна продумати розташування цієї інформації в зовнішній пам'яті (наприклад, на послідовній магнітній стрічці), що забезпечує ефективне виконання цієї програми. Проте в інформаційних системах сукупність взаємозв'язаних інформаційних об'єктів фактично відображає модель об'єктів реального миру. А потреба користувачів в інформації, адекватно тієї, що відображає стан реальних об'єктів, вимагає порівняно швидкої реакції системи на їх запити. І в цьому випадку наявність порівняльна повільних пристроїв зберігання даних, до яких відносяться магнітні стрічки і барабани, було недостатнім.
Можна припустити, що саме вимоги нечислових застосувань викликали появу знімних магнітних дисків з рухомими головками, що з'явилося революцією в історії обчислювальної техніки. Ці пристрої зовнішньої пам'яті володіли істотно більшою ємкістю, чим магнітні барабани, забезпечували задовільну швидкість доступу до даних в режимі довільної вибірки, а можливість зміни дискового пакету на пристрої дозволяла мати практично необмежений архів даних.
З появою магнітних дисків почалася історія систем управління даними в зовнішній пам'яті. До цього кожна прикладна програма, якою потрібно було зберігати дані в зовнішній пам'яті, сама визначала розташування кожної порції даних на магнітній стрічці або барабані і виконувала обміни між оперативною пам'яттю і пристроями зовнішньої пам'яті за допомогою програмно-апаратних засобів низького рівня (машинних команд або викликів відповідних програм операційної системи). Такий режим роботи не дозволяє або дуже утрудняє підтримка на одному зовнішньому носієві декількох архівів інформації, що довго тривало зберігається. Крім того, кожній прикладній програмі доводилося вирішувати проблеми іменування частин даних і структуризації даних в зовнішній пам'яті.
Файли і файлові системи
Важливим кроком в розвитку саме інформаційних систем з'явився перехід до використання централізованих систем управління файлами. З погляду прикладної програми, файл — це іменована область зовнішньої пам'яті, в яку можна записувати і з якої можна прочитувати дані. Правила іменування файлів, спосіб доступу до даних, що зберігаються у файлі, і структура цих даних залежать від конкретної системи управління файлами і, можливо від типу файлу. Система управління файлами бере на себе розподіл зовнішньої пам'яті, відображення імен файлів у відповідні адреси в зовнішній пам'яті і забезпечення доступу до даних.
Конкретні моделі файлів, використовувані в системі управління файлами, ми розглянемо далі, коли перейдемо до фізичних способів організації баз даних, а на цьому етапі нам досить знати, що користувачі бачать файл як лінійну послідовність записів і можуть виконати над ним ряд стандартних операцій:
1. створити файл (необхідного типу і розміру);
2. відкрити раніше створений файл;
3. прочитати з файлу деякий запис (поточну, наступну, попередню, першу, останню);
4. записати у файл на місце поточного запису нову, додати новий запис в кінець файлу.
У різних файлових системах ці операції могли декілька відрізнятися, але загальний сенс їх був саме таким. Головне, що слід зазначити, це те, що структура запису файлу була відома тільки програмі, яка з ним працювала, система управління файлами не знала її. І тому для того, щоб витягувати деяку інформацію з файлу, необхідно було точно знати структуру запису файлу з точністю до біта. Кожна програма, що працює з файлом, повинна була мати у себе усередині структуру даних, відповідну структурі цього файлу. Тому при зміні структури файлу потрібно було змінювати структуру програми, а це вимагало нової компіляції, тобто процесу перекладу програми у виконувані машинні коди. Така ситуації характеризувалася як залежність програм від даних. Для інформаційних систем характерною є наявність великого числа різних користувачів (програм), кожен з яких має свої специфічні алгоритми обробки інформації, що зберігається в одних і тих же файлах. Зміна структури файлу, яке було необхідне для однієї програми, вимагала виправлення і перекомпіляції і додаткового налагодження решти всіх програм, що працюють з цим же файлом. Це було першим істотним недоліком файлових систем, який з'явився поштовхом до створення нових систем зберігання і управління інформацією.
Далі, оскільки файлові системи є загальним сховищем файлів, що належать, взагалі кажучи, різним користувачам, системи управління файлами повинні забезпечувати авторизацію доступу до файлів. У загальному вигляді підхід полягає в тому, що по відношенню до кожного зареєстрованого користувача даної обчислювальної системи для кожного існуючого файлу указуються дії, які дозволені або заборонені даному користувачеві. У більшості сучасних систем управління файлами застосовується підхід до захисту файлів, вперше реалізований в ОС UNIX. У цій ОС кожному зареєстрованому користувачеві відповідає пара цілочисельних ідентифікаторів: ідентифікатор групи, до якої відноситься цей користувач, і його власний ідентифікатор в групі. При кожному файлі зберігається повний ідентифікатор користувача, який створив цей файл, і фіксується, які дії з файлом може проводити його творець, які дії з файлом доступні для інших користувачів тієї ж групи і що можуть робити з файлом користувачі інших груп. Адміністрування режимом доступу до файлу в основному виконується його творцем-власником. Для безлічі файлів, що відображають інформаційну модель однієї наочної області, такий децентралізований принцип управління доступом викликав додаткові труднощі. І відсутність централізованих методів управління доступом до інформації послужила ще однією причиною розробки СУБД.
Наступною причиною стала необхідність забезпечення ефективної паралельної роботи багатьох користувачів з одними і тими ж файлами. У загальному випадку системи управління файлами забезпечували режим багато користувацького доступу. Якщо операційна система підтримує багато користувацький режим, цілком реальна ситуація, коли два або більш за користувача одночасно намагаються працювати з одним і тим же файлом. Якщо всі користувачі збираються тільки читати файл, нічого страшного не відбудеться. Але якщо хоч би один з них змінюватиме файл, для коректної роботи цих користувачів потрібна взаємна синхронізація їх дій по відношенню до файлу.
У системах управління файлами зазвичай застосовувався наступний підхід. У операції відкриття файлу (першій і обов'язковій операції, з якою повинен починатися сеанс роботи з файлом) серед інших параметрів указувався режим роботи (читання або зміна). Якщо до моменту виконання цієї операції деяким призначеним для користувача процесом PR1 файл був вже відкритий іншим процесом PR2 в режимі зміни, то залежно від особливостей системи процесу PR1 або повідомлялося про неможливість відкриття файлу, або він блокувався до тих пір, поки в процесі PR2 не виконувалася операція закриття файлу.
При подібному способі організації одночасна робота декількох користувачів, пов'язана з модифікацією даних у файлі, або взагалі не реалізовувалася, або була дуже сповільнена.
Ці недоліки послужили тим поштовхом, який змусив розробників інформаційних систем запропонувати новий підхід до управління інформацією. Цей підхід був реалізований в рамках нових програмних систем, названих згодом Системами Управління Базами Даних (СУБД), а самі сховища інформації, які працювали під управлінням даних систем, називалися базами або банками даних (БД і БНД).
Перший етап - бази даних на великих ЕОМ
Історія розвитку СУБД налічує більше 30 років. У 1968 році була введена в експлуатацію перша промислова СУБД система IMS фірми IBM. У 1975 році з'явився перший стандарт асоціації по мовах систем обробки даних — Conference of Data System Languages (CODASYL), який визначив ряд фундаментальних понять в теорії систем баз даних, які і до цих пір є основоположними для мережевої моделі даних.
У подальший розвиток теорії баз даних великий внесок був зроблений американським математиком Э. Ф. Коддом, який є творцем реляційної моделі даних. У 1981 році Е. Ф. Кодд отримав за створення реляційної моделі і реляційної алгебри престижну премію Тюрінга Американської асоціації по обчислювальній техніці.
Менше двох десятків років пройшли з цієї миті, але стрімкий розвиток обчислювальної техніки, зміна її принциповій ролі в життя суспільства, бум персональних ЕОМ, що обрушився, і, нарешті, появу могутніх робочих станцій і мереж ЕОМ вплинула також і на розвиток технології баз даних. Можна виділити чотири етапи в розвитку даного напряму в обробці даних. Проте необхідно відмітити, що все ж таки немає жорстких тимчасових обмежень в цих етапах: вони плавно переходять один в іншій і навіть співіснують паралельно, але проте виділення цих етапів дозволить чіткіше охарактеризувати окремі стадії розвитку технології баз даних, підкреслити особливості, специфічні для конкретного етапу.
Перший етап розвитку СУБД пов'язаний з організацією баз даних на великих машинах типу IBM 360/370, ЄС-ЕОМ і МІНІ-ЕОМ типу PDP11 (фірми Digital Equipment Corporation — DEC), різних моделях HP (фірми Hewlett Packard).
Бази даних зберігалися в зовнішній пам'яті центральної ЕОМ, користувачами цих баз даних були завдання, що запускаються в основному в пакетному режимі. Інтерактивний режим доступу забезпечувався за допомогою консольних терміналів, які не володіли власними обчислювальними ресурсами (процесором, зовнішньою пам'яттю) і служили тільки пристроями введення-виводу для центральної ЕОМ. Програми доступу до БД писалися на різних мовах і запускалися як звичайні числові програми. Могутні операційні системи забезпечували можливість умовно паралельного виконання всієї безлічі завдань. Ці системи можна було віднести до систем розподіленого доступу, тому що база даних була централізованою, зберігалася на пристроях зовнішньої пам'яті однієї центральної ЕОМ, а доступ до неї підтримувався від багатьох користувачів-завдань.
Особливості цього етапу розвитку виражаються в наступному:
Всі СУБД базуються на могутніх мультипрограмних операційних системах (MVS, SVM, RTE, OSRV, RSX, UNIX), тому в основному підтримується робота з централізованою базою даних в режимі розподіленого доступу.
Функції управління розподілом ресурсів в основному здійснюються операційною системою (ОС).
Підтримуються мови низького рівня маніпулювання даними, орієнтовані на навігаційні методи доступу до даних.
Значна роль відводиться адмініструванню даних.
Проводяться серйозні роботи по обґрунтуванню і формалізації реляційної моделі даних, і була створена перша система (System R), що реалізовує ідеологію реляційної моделі даних.
Проводяться теоретичні роботи по оптимізації запитів і управлінню розподіленим доступом до централізованої БД, було введено поняття транзакції.
Результати наукових досліджень відкрито обговорюються у пресі, йде могутній потік загальнодоступних публікацій, що стосуються всіх аспектів теорії і практики баз даних, і результати теоретичних досліджень активно упроваджуються в комерційні СУБД.
З'являються перші мови високого рівня для роботи з реляційною моделлю даних. Проте відсутні стандарти для цих перших мов.
Епоха персональних комп'ютерів
Персональні комп'ютери нестримно увірвалися в наше життя і буквально перевернули наше уявлення про місце і роль обчислювальної техніки в житті суспільства. Тепер комп'ютери стали ближчими і доступніше кожному користувачеві. Зник благоговійний страх рядових користувачів перед незрозумілими і складними мовами програмування. З'явилася безліч програм, призначених для роботи непідготовлених користувачів. Ці програми були прості у використанні і інтуїтивно зрозумілі: це перш за все різні редактори текстів, електронні таблиці та інші. Простими і зрозумілими сталі операції копіювання файлів і перенесення інформації з одного комп'ютера на іншій, роздрукування текстів, таблиць і інших документів. Системні програмісти були відсунуті на другий план. Кожен користувач міг себе відчути повним господарем цього могутнього і зручного пристрою, що дозволяє автоматизувати багато аспектів діяльності. І, звичайно, це позначилося і на роботі з базами даних. З'явилися програми, які називалися системами управління базами даних і дозволяли зберігати значні об'єми інформації, вони мали зручний інтерфейс для заповнення даних, вбудовані засоби для генерації різних звітів. Ці програми дозволяли автоматизувати багато облікових функцій, які раніше велися уручну. Постійне зниження цін на персональні комп'ютери зробило їх доступними не тільки для організацій і фірм, але і для окремих користувачів. Комп'ютери стали інструментом для ведення документації і власних облікових функцій. Це все зіграло як позитивну, так і негативну роль в області розвитку баз даних. Простота, що здається, і доступність персональних комп'ютерів і їх програмного забезпечення породила безліч дилетантів. Ці розробники, вважаючи себе за знавців, почали проектувати недовговічні бази даних, які не враховували багатьох особливостей об'єктів реального миру. Багато було створено систем-одноднівок, які не відповідали законам розвитку і взаємозв'язку реальних об'єктів. Проте доступність персональних комп'ютерів змусила користувачів з багатьох галузей знань, які раніше не застосовували обчислювальну техніку в своїй діяльності, звернутися до них. І попит на розвинені зручні програми обробки даних примушував постачальників програмного забезпечення поставляти все нові системи, які прийнято називати настільними (desktop) СУБД. Значна конкуренція серед постачальників примушувала удосконалювати ці системи, пропонуючи нові можливості, покращуючи інтерфейс і швидкодію систем, знижуючи їх вартість. Наявність на ринку великого числа СУБД, що виконують схожі функції, зажадало розробки методів експорту-імпорту даних для цих систем і відкриття форматів зберігання даних.
Але і в цей період з'являлися любителі, які всупереч здоровому глузду розробляли власні СУБД, використовуючи стандартні мови програмування. Це був тупиковий варіант, тому що подальший розвиток показав, що перенести дані з нестандартних форматів в нові СУБД було набагато важче, а в деяких випадках вимагало таких трудовитрат, що легше було б все розробити наново, але дані все одно треба було переносити на нову перспективнішу СУБД. І це теж було результатом недооцінки тих функцій, які повинна була виконувати СУБД.
Особливості цього етапу наступні:
Всі СУБД були розраховані на створення БД в основному з монопольним доступом. І це зрозуміло. Комп'ютер персональний, він не був приєднаний до мережі, і база даних на нім створювалася для роботи одного користувача. У окремих випадках передбачалася послідовна робота декількох користувачів, наприклад, спочатку оператор, який вводив бухгалтерські документи, а потім головбуха, який визначав проводки, відповідні первинним документам.
Більшість СУБД мали розвинений і зручний призначений для користувача інтерфейс. У більшості існував інтерактивний режим роботи з БД як в рамках опису БД, так і в рамках проектування запитів. Крім того, більшість СУБД пропонували розвинений і зручний інструментарій для розробки готових застосувань без програмування. Інструментальне середовище складалося з готових елементів додатку у вигляді шаблонів екранних форм, звітів, етикеток (Labels), графічних конструкторів запитів, які досить просто могли бути зібрані в єдиний комплекс.
У всіх настільних СУБД підтримувався тільки зовнішній рівень представлення реляційної моделі, тобто тільки зовнішній табличний вигляд структур даних.
За наявності високорівневих мов маніпулювання даними типу реляційної алгебри і SQL в настільних СУБД підтримувалися низькорівневі мови маніпулювання даними на рівні окремих рядків таблиць.
У настільних СУБД були відсутні засоби підтримки посилальної і структурної цілісності бази даних. Ці функції повинні були виконувати додатки, проте незначність засобів розробки додатків іноді не дозволяла це зробити, і в цьому випадку ці функції повинні були виконуватися користувачем, вимагаючи від нього додаткового контролю при введенні і зміні інформації, що зберігається в БД.
Наявність монопольного режиму роботи фактично привела до звироднілості функцій адміністрування БД і у зв'язку з цим — до відсутності інструментальних засобів адміністрування БД.
І, нарешті, остання і зараз вельми позитивна особливість — це порівняно скромні вимоги до апаратного забезпечення з боку настільних СУБД. Цілком працездатні застосування, розроблені, наприклад, на Clipper, працювали на РС 286.
В принципі, їх навіть важко назвати повноцінними СУБД. Яскраві представники цього сімейства — дуже СУБД Dbase (DbaseIII+, DBASEIV), що широко використалися до недавнього часу, FoxPro, Clipper, Paradox.
Розподілені бази даних
Добре відомо, що історія розвивається по спіралі, тому після процесу "персоналізації" почався зворотний процес — інтеграція. Множиться кількість локальних мереж, все більше інформації передається між комп'ютерами, гостро встає завдання узгодженості даних, що зберігаються і обробляються в різних місцях, але логічно один з одним зв'язаних, виникають завдання, пов'язані з паралельною обробкою транзакцій, — послідовностей операцій над БД, що переводять її з одного несуперечливого стану в інший несуперечливий стан. Успішне вирішення цих завдань приводить до появи розподілених баз даних, що зберігають всі переваги настільних СУБД і в той же час дозволяють організувати паралельну обробку інформації і підтримку цілісності БД.
Особливості даного етапу:
Практично всі сучасні СУБД забезпечують підтримку повної реляційної моделі, а саме:
Про структурну цілісність — допустимими є тільки дані, представлені у вигляді стосунків реляційної моделі;
Про мовну цілісність, тобто мов маніпулювання даними високого рівня (в основному SQL);
Про посилальну цілісність, контролю за дотриманням посилальної цілісності протягом всього часу функціонування системи, і гарантій неможливості з боку СУБД порушити ці обмеження.
Більшість сучасних СУБД розраховані на багато платформну архітектуру, тобто вони можуть працювати на комп'ютерах з різною архітектурою і під різними операційними системами, при цьому для користувачів доступ до даних, керованих СУБД на різних платформах, практично невиразний.
Необхідність підтримки багато користувацької роботи з базою даних і можливість децентралізованого зберігання даних зажадали розвитку засобів адміністрування БД з реалізацією загальної концепції засобів захисту даних.
Потреба в нових реалізаціях викликала створення серйозних теоретичних праць по оптимізації реалізацій розподіленій БД і роботі з розподіленими транзакціями і запитами з впровадженням отриманих результатів в комерційні СУБД.
Для того, щоб не втратити клієнтів, які раніше працювали на настільних СУБД, практично всі сучасні СУБД мають засоби підключення клієнтських застосувань, розроблених з використанням настільних СУБД, і засобу експорту даних з форматів настільних СУБД другого етапу розвитку.
Саме до цього етапу можна віднести розробку ряду стандартів в рамках мов опису і маніпулювання даними починаючи з SQL89, SQL92, SQL99 і технологій по обміну даними між різними СУБД, до яких можна віднести і протокол ODBC (Open DataBase Connectivity), запропонований фірмою Microsoft.
Саме до цього етапу можна віднести початок робіт, пов'язаних з концепцією об'єктно-орієнтованих БД, — ООБД. Представниками СУБД, що відносяться до другого етапу, можна рахувати MS Access 97 і всі сучасні сервери баз даних Oracle7.3,Oracle 8.4 MS SQL6.5, MS SQL7.0, System 10, System 11, Informix, DB2, SQL Base і інші сучасні сервери баз даних, яких зараз налічується декілька десятків.
Перспективи розвитку систем управління базами даних
Цей етап характеризується появою нової технології доступу до даних — Інтернет. Основна відмінність цього підходу від технології клієнт-сервер полягає в тому, що відпадає необхідність використання спеціалізованого клієнтського програмного забезпечення. Для роботи з видаленою базою даних використовується стандартний браузер Інтернету, наприклад Microsoft Internet Explorer або Netscape Navigator, і для кінцевого користувача процес звернення до даних відбувається аналогічно ковзанню по Усесвітній Павутині. При цьому вбудований в завантажені користувачем HTML-сторінки код, написаний зазвичай на мові Java, Java-script, Perl і інших, відстежує всі дії користувача і транслює їх в низькорівневі SQL-запроси до бази даних, виконуючи, таким чином, ту роботу, якій в технології клієнт-сервер займається клієнтська програма. Зручність даного підходу привела до того, що він почав використовуватися не тільки для видаленого доступу до баз даних, але і для користувачів локальної мережі підприємства. Прості завдання обробки даних, не пов'язані з складними алгоритмами, що вимагають узгодженої зміни даних в багатьох взаємозв'язаних об'єктах, досить просто і ефективно можуть бути побудовані по даній архітектурі. В цьому випадку для підключення нового користувача до можливості використовувати дане завдання не потрібна установка додаткового клієнтського програмного забезпечення. Проте алгоритмічно складні завдання рекомендується реалізовувати в архітектурі "клієнт-сервер" з розробкою спеціального клієнтського програмного забезпечення.
У кожного з вище перелічених підходів до роботи з даними є свої достоїнства і свої недоліки, які і визначають сферу застосування того або іншого методу, і в даний час всі підходи широко використовуються.
1960-ті рр. розробка перших БД. CODASYL — мережева модель даних та одночасно незалежна розробка ієрархічної БД фірмою North American Rockwell, яка пізніше узята за основу IMS — власної розробки IBM.
1970-ті рр. наукове обґрунтування Едгаром Ф. Коддом основ реляційної моделі, котра на качану зацікавила лише наукові кола. Вперше цю модель було використано у БД Ingres (Берклі) та System R(IBM), що булі лише дослідними прототипами, анонсованими протягом 1976 долі.
1980-ті рр. поява перших комерційних версій реляційних БД Oracle та DB2. Реляційні БД починають успішно витісняти мережеві та ієрархічні. Дослідження децентралізованих (розподілених) систем БД, проте сморід не відіграють особливої ролі на ринку БД.
1990-ті рр. увага науковців спрямовується у сторону об'єктно-орієнтованих БД, які знайшли застосування у деру чергу в тихий областях, де використовуються комплексні дані: інженерні, мультимедійні БД.
2000-ні рр. головним нововведенням є підтримка та застосування XML у БД. Розробники комерційних БД, які панували на ринку у 1990-их рр., отримують все більшу конкуренцію зі сторони руху відкритого програмного забезпечення. Реакцією на це стає поява безкоштовних версій комерційних БД.
Похожие работы
... взаємопов'язаних даних об'єднуються в бази даних. СУБД створюються для таких досвідчених користувачів, як програмісти. Системи управління даними третього покоління Можливості СУБД розширились. Створені розвинуті інтерфейси, що забезпечують інтерактивний доступ звичайним користувачам. Переваги СУБД: · Скорочення надлишку даних; · Без баз даних неможливо уникнути зберігання ...
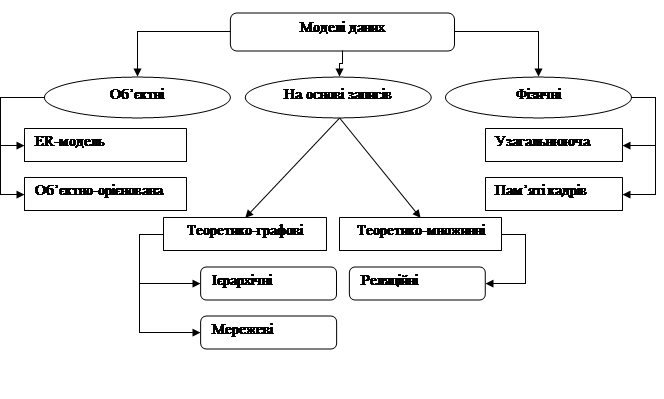
... записів необхідно створювати досить складні програми;· незалежність від даних існує лише у мінімальному ступені;· відсутність загальновизнаних теоретичних основ. 2 Інструментальна система управління базами даних CronosPRO 2.1 Загальна характеристика системи ІСУБД CronosPro – це система, призначена для організації інформації у вигляді банків даних та їх подальшої обробки. Інформація зберігається в ...
... сть в межах єдиної держави безумовно потребує здійснення державою виваженої національної політики, спрямованої на пом'якшення міжнаціональних суперечностей, утвердження дружби і співробітництва націй. 1.2 Актуальні проблеми етнічної соціології В сучасних умовах світ — це надто строката картина національно-етнічної багатоманітності, що не зменшується, а дедалі збільшується і тим самим триває ...
... і, веслувальний у Херсоні та ін. Популярний на Україні туризм диспонує понад 50 туристичними базами і понад 800 туристичними й відпочинковими таборами. 3 СУЧАСНІ ПРІОРИТЕТИ ФІЗИЧНОГО ВИХОВАННЯ В УКРАЇНІ Фізична культура в Україні є часткою загальної культури суспільства, що спрямована на зміцнення здоров'я, розвиток фізичних, морально-вольових та інтелектуальних здібностей людини з метою ...
0 комментариев