Навигация
Параллелизм на уровне команд
133942
знака
0
таблиц
27
изображений
2.6 Параллелизм на уровне команд
Разработчики компьютеров стремятся к тому, чтобы улучшить производительность машин, над которыми они работают. Один из способов заставить процессоры работать быстрее — увеличение их скорости, однако при этом существуют некоторые технологические ограничения, связанные с конкретным историческим периодом. Поэтому большинство разработчиков для достижения лучшей производительности при данной скорости работы процессора используют параллелизм (возможность выполнять две или более операций одновременно).
Существует две основные формы параллелизма: параллелизм на уровне команд и параллелизм на уровне процессоров. В первом случае параллелизм осуществляется в пределах отдельных команд и обеспечивает выполнение большого количества команд в секунду. Во втором случае над одной задачей работают одновременно несколько процессоров. Каждый подход имеет свои преимущества.
2.6.1 Конвейеры
Уже много лет известно, что главным препятствием высокой скорости выполнения команд является их вызов из памяти. Для разрешения этой проблемы разработчики придумали средство для вызова команд из памяти заранее, чтобы ониимелись в наличии в тот момент, когда будут необходимы. Эти команды помещались в набор регистров, который назывался буфером выборки с упреждением. Таким образом, когда была нужна определенная команда, она вызывалась прямо из буфера, и не нужно было ждать, пока она считается из памяти. Эта идея использовалась еще при разработке IBM Stretch, который был сконструирован в 1959 году.
В действительности процесс выборки с упреждением подразделяет выполнение команды на два этапа: вызов и собственно выполнение. Идея конвейера еще больше продвинула эту стратегию вперед. Теперь команда подразделялась уже не на два, а на несколько этапов, каждый из которых выполнялся определенной частью аппаратного обеспечения, причем все эти части могли работать параллельно.
На рис. 2.3а изображен конвейер из 5 блоков, которые называются стадиями. Стадия С1 вызывает команду из памяти и помещает ее в буфер, где она хранится до тех пор, пока не будет нужна. Стадия С2 декодирует эту команду, определяя ее тип и тип операндов, над которыми она будет производить определенные действия. Стадия СЗ определяет местонахождение операндов и вызывает их или из регистров, или из памяти. Стадия С4 выполняет команду, обычно путем провода операндов через тракт данных. И наконец, стадия С5 записывает результат обратно в нужный регистр.
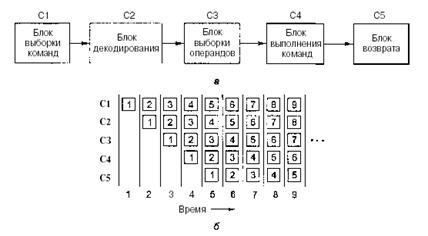
Рисунок 2.3 - Конвейер из 5 стадий (а); состояние каждой стадии в зависимости от количества пройденных циклов (б). Показано 9 циклов
На рис. 2.3, б мы видим, как действует конвейер во времени. Во время цикла 1 стадия С1 работает над командой 1, вызывая ее из памяти. Во время цикла 2 стадия С2 декодирует команду 1, в то время как стадия С1 вызывает из памяти команду 2. Во время цикла 3 стадия СЗ вызывает операнды для команды 1, стадия С2 декодирует команду 2, а стадия С1 вызывает третью команду. Во время цикла 4 стадия С4 выполняет команду 1, СЗ вызывает операнды для команды 2, С2 декодирует команду 3, а С1 вызывает команду 4. Наконец, во время пятого цикла С5 записывает результат выполнения команды 1 обратно в регистр, тогда как другие стадии работают над следующими командами.
Конвейеры позволяют найти компромисс между временем ожидания (сколько времени занимает выполнение одной команды) и пропускной способностью процессора (сколько миллионов команд в секунду выполняет процессор). Если время цикла составляет Т не, а конвейер содержит n стадий, то время ожидания составит nТ не, а пропускная способность — 1000/Т млн команд в секунду.
2.6.2 Суперскалярные архитектуры
Один конвейер — хорошо, а два — еще лучше. Одна из возможных схем процессора с двойным конвейером показана на рис. 2.4. В основе разработки лежит конвейер, изображенный на рис. 2.3. Здесь общий отдел вызова команд берет из памяти сразу по две команды и помешает каждую из них в один из конвейеров. Каждый конвейер содержит АЛУ для параллельных операций. Чтобы выполняться параллельно, две команды не должны конфликтовать при использовании ресурсов (например, регистров), и ни одна из них не должна зависеть от результата выполнения другой. Как и в случае с одним конвейером, либо компилятор должен следить, чтобы не возникало неприятных ситуаций (например, когда аппаратное обеспечение выдает некорректные результаты, если команды несовместимы), либо же конфликты выявляются и устраняются прямо во время выполнения команд благодаря использованию дополнительного аппаратного обеспечения.
Сначала конвейеры (как двойные, так и одинарные) использовались только в компьютерах RISC. У 386-го и его предшественников их не было. Конвейеры в процессорах компании Intel появились только начиная с 486-й модели1.486-й процессор содержал один конвейер, a Pentium — два конвейера из пяти стадий. Похожая схема изображена на рис. 2.4, но разделение функций между второй и третьей стадиями (они назывались декодирование 1 и декодирование 2) было немного другим. Главный конвейер (u-конвейер) мог выполнять произвольные команды. Второй конвейер (v-конвейер) мог выполнять только простые команды с целымичислами, а также одну простую команду с плавающей точкой (FXCH).
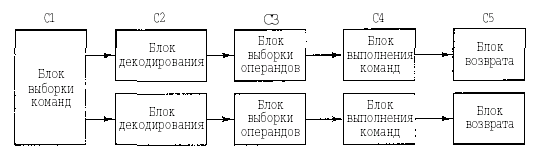
Рисунок 2.4 - Двойной конвейер из пяти стадий с общим отделом вызова команд
Имеются сложные правила определения, является ли пара команд совместимой для того, чтобы выполняться параллельно. Если команды, входящие в пару, были сложными или несовместимыми, выполнялась только одна из них (в и-конвейере). Оставшаяся вторая команда составляла затем пару со следующей командой. Команды всегда выполнялись по порядку. Таким образом, Pentium содержал особые компиляторы, которые объединяли совместимые команды в пары и могли порождать программы, выполняющиеся быстрее, чем в предыдущих версиях. Измерения показали, что программы, производящие операции с целыми числами, на компьютере Pentium выполняются почти в два раза быстрее, чем на 486-м, хотя у него такая же тактовая частота. Вне всяких сомнений, преимущество в скорости появилось благодаря второму конвейеру.
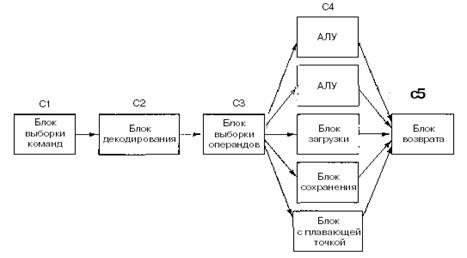
Рисунок 2.5 - Суперскалярный процессор с пятью функциональными блоками
Переход к четырем конвейерам возможен, но это потребовало бы создания громоздкого аппаратного обеспечения. Вместо этого используется другой подход. Основная идея — один конвейер с большим количеством функциональных блоков, как показано па рис. 2.5. Pentium II, к примеру, имеет сходную структуру. В 1987 году для обозначения этого подхода был введен термин суперскалярная архитектура. Однако подобная идея нашла воплощение еще более 30 лет назад в компьютере CDC 6600. CDC 6600 вызывал команду из памяти каждые 100 не и помещал ее в один из 10 функциональных блоков для параллельного выполнения. Пока команды выполнялись, центральный процессор вызывал следующую команду.
Стадия 3 выпускает команды значительно быстрее, чем стадия 4 способна их выполнять. Если бы стадия 3 выпускала команду каждые 10 не, а все функциональные блоки выполняли бы свою работу также за 10 не, то на четвертой стадии всегда функционировал бы только один блок, что сделало бы саму идею конвейера бессмысленной. В действительности большинству функциональных блоков четвертой стадии для выполнения команды требуется значительно больше времени, чем занимает один цикл (это блоки доступа к памяти и блок выполнения операций с плавающей точкой). Как видно из рис. 2 5, на четвертой стадии может быть несколько АЛУ.
Похожие работы
... программе, однако аппаратура обнаружения и устранения конфликтов между логически связанными командами обеспечивает получение результатов в соответствии с заданной программой. Соответствующая организация коммутирующих магистралей, обеспечивающая засылку результата операции непосредственно в буфер, хранящий логически зависимую команду, задержанную из-за конфликта, или непосредственно ...
... элементов, глобальное пространство имен, а также лавинообразную первоначальную загрузку сети. Таким образом ОСРВ SPOX имеет необходимые механизмы для создания отказоустойчивой распределенной операционной системы реального времени, концепция построения которой описана в главе 2. 4.3 Аппаратно-зависимые компоненты ОСРВ Модули маршрутизации, реконфигурации, голосования реализованы как аппаратно- ...
... ? 8. Какими программами можно воспользоваться для устранения проблем и ошибок, обнаруженных программой Sandra? Раздел 3. Автономная и комплексная проверка функционирования и диагностика СВТ, АПС и АПК Некоторые из достаточно интеллектуальных средств вычислительной техники, такие как принтеры, плоттеры, могут иметь режимы автономного тестировании. Так, автономный тест принтера запускается без ...
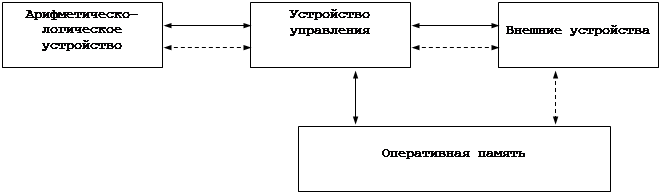
... оснащать их дополнительными устройствами сотен различных производителей. Итак, после начала широкого внедрения персональных компьютеров в повседневную жизнь, продолжилось быстрое развитие вычислительной техники. Остановимся на наиболее важном элементе: микропроцессор – это эффективный с технологической и экономической точки зрения инструмент для переработки возрастающих потоков информации. Новое ...
0 комментариев